 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeManCAR: Manifold-Constrained Latent Reasoning with Adaptive Test-Time Computation for Sequential Recommendation
Feb 23, 2026Sequential recommendation increasingly employs latent multi-step reasoning to enhance test-time computation. Despite empirical gains, existing approaches largely drive intermediate reasoning states via target-dominant objectives without imposing explicit feasibility constraints. This results in latent drift, where reasoning trajectories deviate into implausible regions. We argue that effective recommendation reasoning should instead be viewed as navigation on a collaborative manifold rather than free-form latent refinement. To this end, we propose ManCAR (Manifold-Constrained Adaptive Reasoning), a principled framework that grounds reasoning within the topology of a global interaction graph. ManCAR constructs a local intent prior from the collaborative neighborhood of a user's recent actions, represented as a distribution over the item simplex. During training, the model progressively aligns its latent predictive distribution with this prior, forcing the reasoning trajectory to remain within the valid manifold. At test time, reasoning proceeds adaptively until the predictive distribution stabilizes, avoiding over-refinement. We provide a variational interpretation of ManCAR to theoretically validate its drift-prevention and adaptive test-time stopping mechanisms. Experiments on seven benchmarks demonstrate that ManCAR consistently outperforms state-of-the-art baselines, achieving up to a 46.88% relative improvement w.r.t. NDCG@10. Our code is available at https://github.com/FuCongResearchSquad/ManCAR.
Instance-based Vision Transformer for Subtyping of Papillary Renal Cell Carcinoma in Histopathological Image
Jun 23, 2021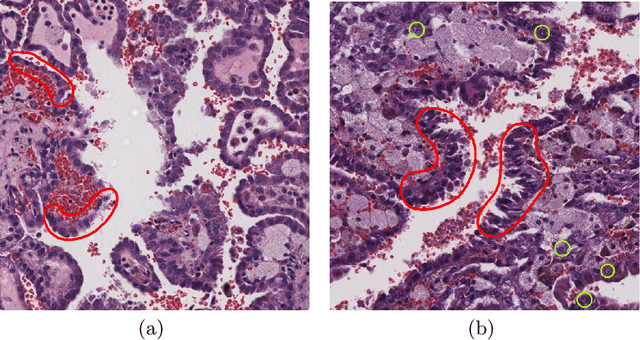
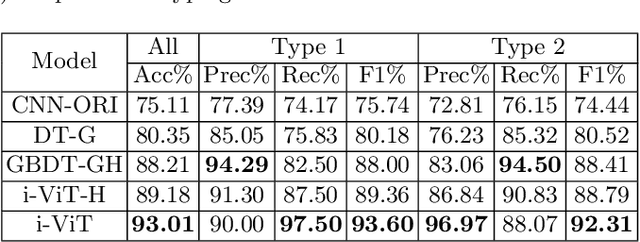
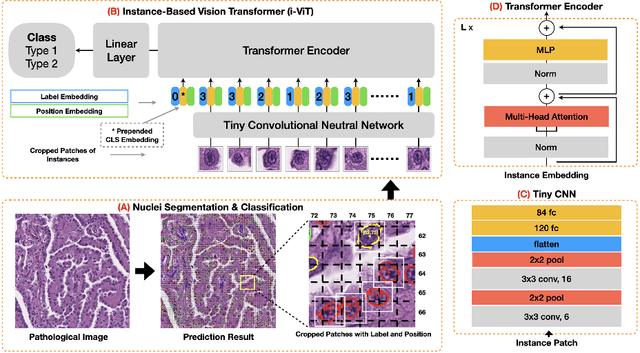
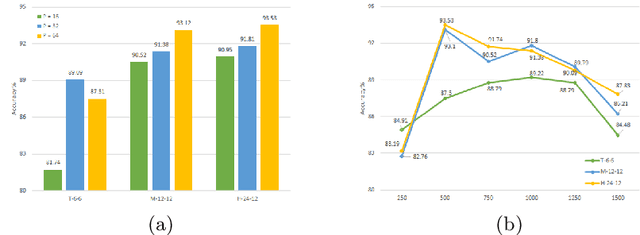
Histological subtype of papillary (p) renal cell carcinoma (RCC), type 1 vs. type 2, is an essential prognostic factor. The two subtypes of pRCC have a similar pattern, i.e., the papillary architecture, yet some subtle differences, including cellular and cell-layer level patterns. However, the cellular and cell-layer level patterns almost cannot be captured by existing CNN-based models in large-size histopathological images, which brings obstacles to directly applying these models to such a fine-grained classification task. This paper proposes a novel instance-based Vision Transformer (i-ViT) to learn robust representations of histopathological images for the pRCC subtyping task by extracting finer features from instance patches (by cropping around segmented nuclei and assigning predicted grades). The proposed i-ViT takes top-K instances as input and aggregates them for capturing both the cellular and cell-layer level patterns by a position-embedding layer, a grade-embedding layer, and a multi-head multi-layer self-attention module. To evaluate the performance of the proposed framework, experienced pathologists are invited to selected 1162 regions of interest from 171 whole slide images of type 1 and type 2 pRCC. Experimental results show that the proposed method achieves better performance than existing CNN-based models with a significant margin.