 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Prevent Monocular SLAM Failure using Reinforcement Learning
Dec 23, 2018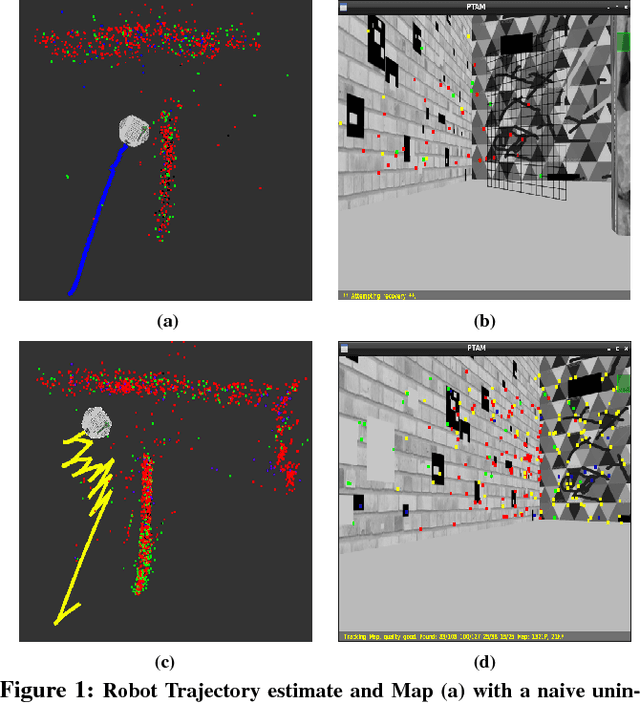

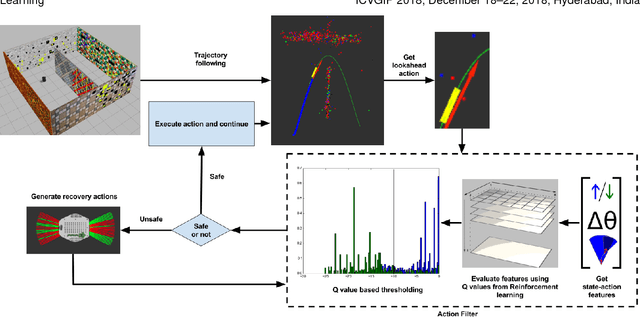
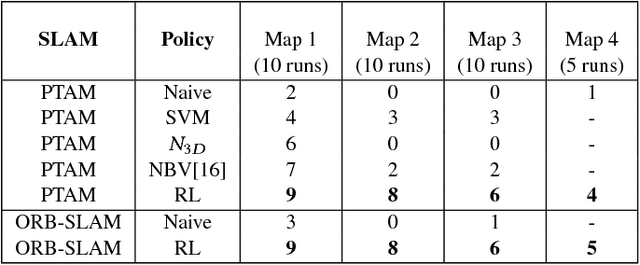
Monocular SLAM refers to using a single camera to estimate robot ego motion while building a map of the environment. While Monocular SLAM is a well studied problem, automating Monocular SLAM by integrating it with trajectory planning frameworks is particularly challenging. This paper presents a novel formulation based on Reinforcement Learning (RL) that generates fail safe trajectories wherein the SLAM generated outputs do not deviate largely from their true values. Quintessentially, the RL framework successfully learns the otherwise complex relation between perceptual inputs and motor actions and uses this knowledge to generate trajectories that do not cause failure of SLAM. We show systematically in simulations how the quality of the SLAM dramatically improves when trajectories are computed using RL. Our method scales effectively across Monocular SLAM frameworks in both simulation and in real world experiments with a mobile robot.
Discovering hierarchies using Imitation Learning from hierarchy aware policies
Dec 01, 2018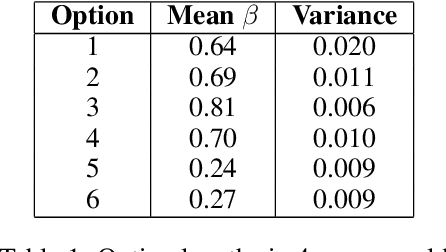
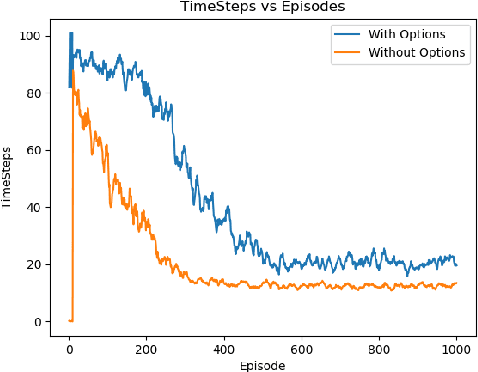
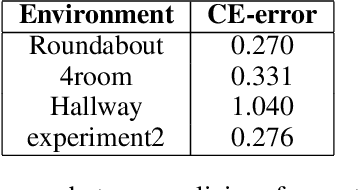
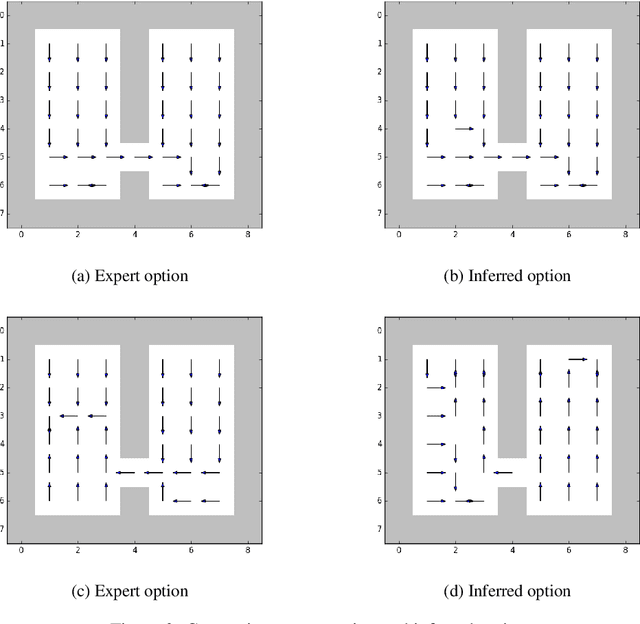
Learning options that allow agents to exhibit temporally higher order behavior has proven to be useful in increasing exploration, reducing sample complexity and for various transfer scenarios. Deep Discovery of Options (DDO) is a generative algorithm that learns a hierarchical policy along with options directly from expert trajectories. We perform a qualitative and quantitative analysis of options inferred from DDO in different domains. To this end, we suggest different value metrics like option termination condition, hinge value function error and KL-Divergence based distance metric to compare different methods. Analyzing the termination condition of the options and number of time steps the options were run revealed that the options were terminating prematurely. We suggest modifications which can be incorporated easily and alleviates the problem of shorter options and a collapse of options to the same mode.
Improvements on Hindsight Learning
Nov 04, 2018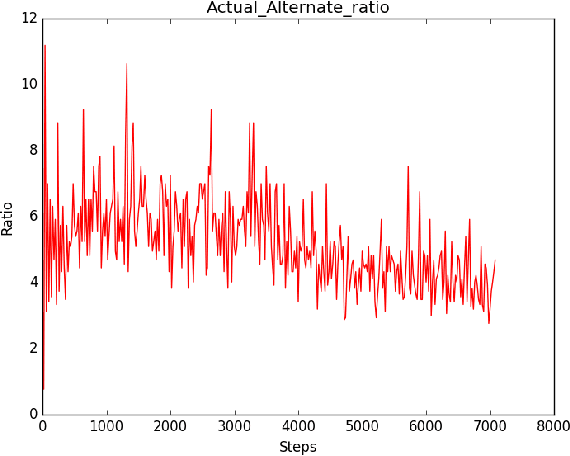
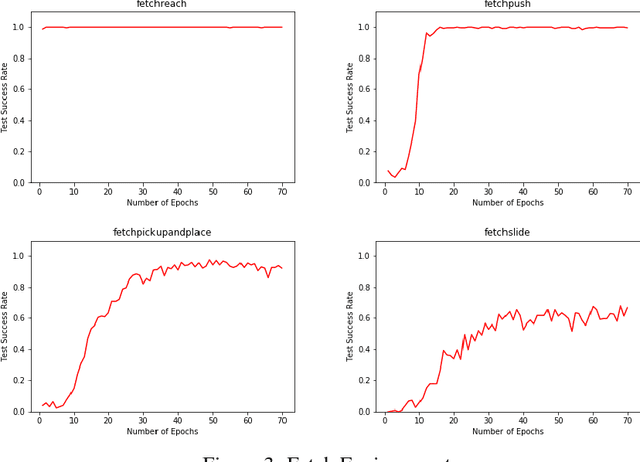
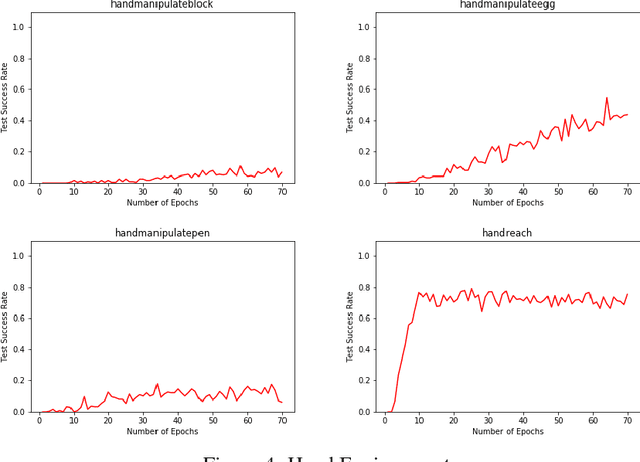
Sparse reward problems are one of the biggest challenges in Reinforcement Learning. Goal-directed tasks are one such sparse reward problems where a reward signal is received only when the goal is reached. One promising way to train an agent to perform goal-directed tasks is to use Hindsight Learning approaches. In these approaches, even when an agent fails to reach the desired goal, the agent learns to reach the goal it achieved instead. Doing this over multiple trajectories while generalizing the policy learned from the achieved goals, the agent learns a goal conditioned policy to reach any goal. One such approach is Hindsight Experience replay which uses an off-policy Reinforcement Learning algorithm to learn a goal conditioned policy. In this approach, a replay of the past transitions happens in a uniformly random fashion. Another approach is to use a Hindsight version of the policy gradients to directly learn a policy. In this work, we discuss different ways to replay past transitions to improve learning in hindsight experience replay focusing on prioritized variants in particular. Also, we implement the Hindsight Policy gradient methods to robotic tasks.
Pack and Detect: Fast Object Detection in Videos Using Region-of-Interest Packing
Oct 01, 2018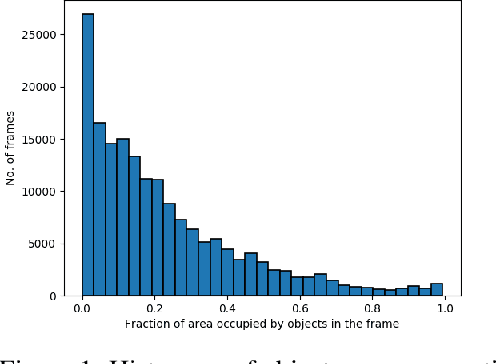
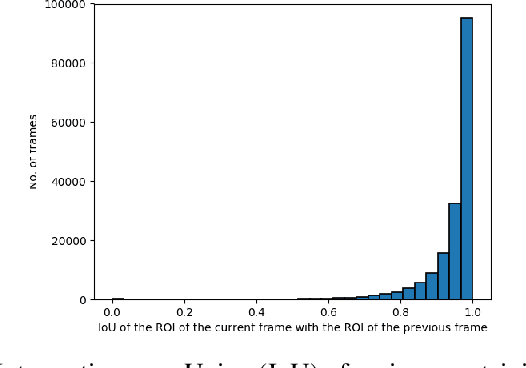
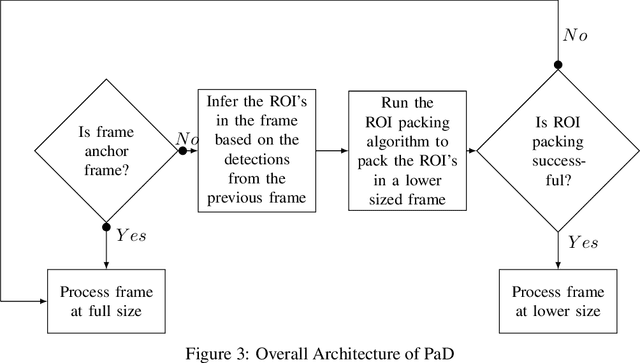
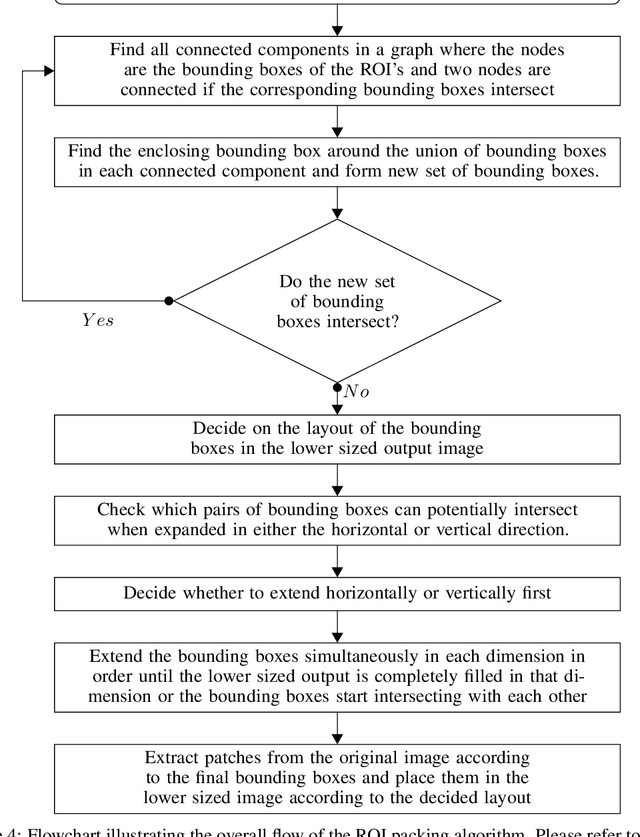
Object detection in videos is an important task in computer vision for various applications such as object tracking, video summarization and video search. Although great progress has been made in improving the accuracy of object detection in recent years due to improved techniques for training and deploying deep neural networks, they are computationally very intensive. For example, processing a video at 300x300 resolution using the SSD300 (Single Shot Detector) object detection network with VGG16 as backbone at 30 fps requires 1.87 trillion FLOPS/s. In order to address this challenge, we make two important observations in the context of videos. In some scenarios, most of the regions in a video frame are background and the salient objects occupy only a small fraction of the area in the frame. Further, in a video, there is a strong temporal correlation between consecutive frames. Based on these observations, we propose Pack and Detect (PaD) to reduce the computational requirements for the task of object detection in videos using neural networks. In PaD, the input video frame is processed at full size in selected frames called anchor frames. In the frames between the anchor frames, namely inter-anchor frames, the regions of interest(ROI) are identified based on the detections in the previous frame. We propose an algorithm to pack the ROI's of each inter-anchor frame together in a lower sized frame. In order to maintain the accuracy of object detection, the proposed algorithm expands the ROI's greedily to provide more background information to the detector. The computational requirements are reduced due to the lower size of the input. This method can potentially reduce the number of FLOPS required for a frame by 4x. Tuning the algorithm parameters can provide a 1.3x increase in throughput with only a 2.5% drop in accuracy.
HOPF: Higher Order Propagation Framework for Deep Collective Classification
Sep 21, 2018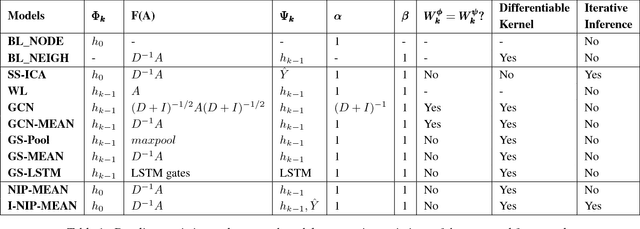
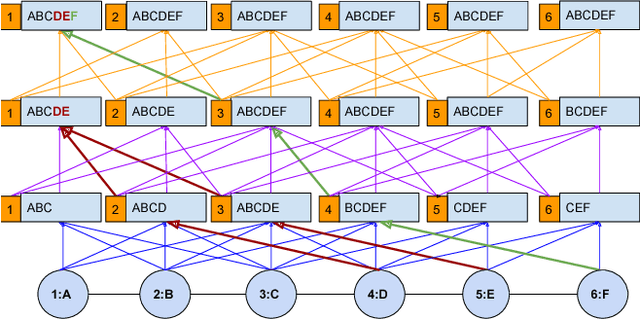
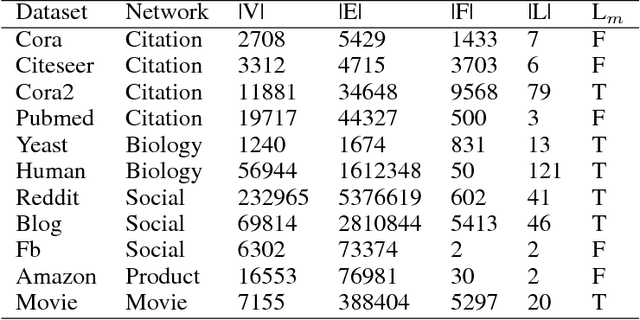
Given a graph where every node has certain attributes associated with it and some nodes have labels associated with them, Collective Classification (CC) is the task of assigning labels to every unlabeled node using information from the node as well as its neighbors. It is often the case that a node is not only influenced by its immediate neighbors but also by higher order neighbors, multiple hops away. Recent state-of-the-art models for CC learn end-to-end differentiable variations of Weisfeiler-Lehman (WL) kernels to aggregate multi-hop neighborhood information. In this work, we propose a Higher Order Propagation Framework, HOPF, which provides an iterative inference mechanism for these powerful differentiable kernels. Such a combination of classical iterative inference mechanism with recent differentiable kernels allows the framework to learn graph convolutional filters that simultaneously exploit the attribute and label information available in the neighborhood. Further, these iterative differentiable kernels can scale to larger hops beyond the memory limitations of existing differentiable kernels. We also show that existing WL kernel-based models suffer from the problem of Node Information Morphing where the information of the node is morphed or overwhelmed by the information of its neighbors when considering multiple hops. To address this, we propose a specific instantiation of HOPF, called the NIP models, which preserves the node information at every propagation step. The iterative formulation of NIP models further helps in incorporating distant hop information concisely as summaries of the inferred labels. We do an extensive evaluation across 11 datasets from different domains. We show that existing CC models do not provide consistent performance across datasets, while the proposed NIP model with iterative inference is more robust.
Fusion Graph Convolutional Networks
Sep 21, 2018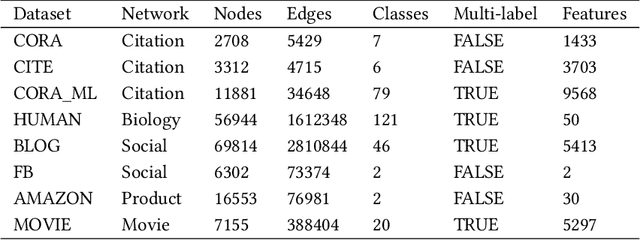
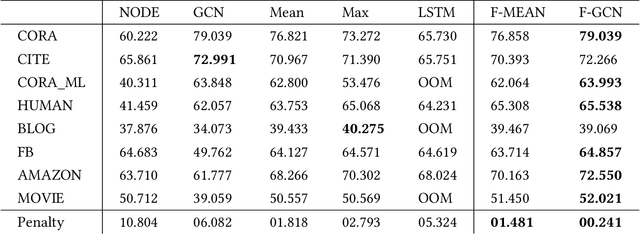
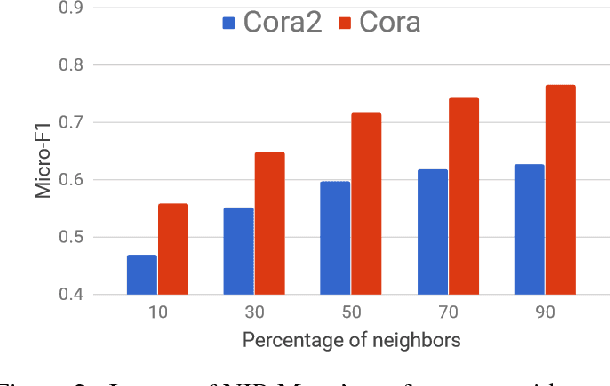
Semi-supervised node classification in attributed graphs, i.e., graphs with node features, involves learning to classify unlabeled nodes given a partially labeled graph. Label predictions are made by jointly modeling the node and its' neighborhood features. State-of-the-art models for node classification on such attributed graphs use differentiable recursive functions that enable aggregation and filtering of neighborhood information from multiple hops. In this work, we analyze the representation capacity of these models to regulate information from multiple hops independently. From our analysis, we conclude that these models despite being powerful, have limited representation capacity to capture multi-hop neighborhood information effectively. Further, we also propose a mathematically motivated, yet simple extension to existing graph convolutional networks (GCNs) which has improved representation capacity. We extensively evaluate the proposed model, F-GCN on eight popular datasets from different domains. F-GCN outperforms the state-of-the-art models for semi-supervised learning on six datasets while being extremely competitive on the other two.
Diversity driven Attention Model for Query-based Abstractive Summarization
Jul 13, 2018

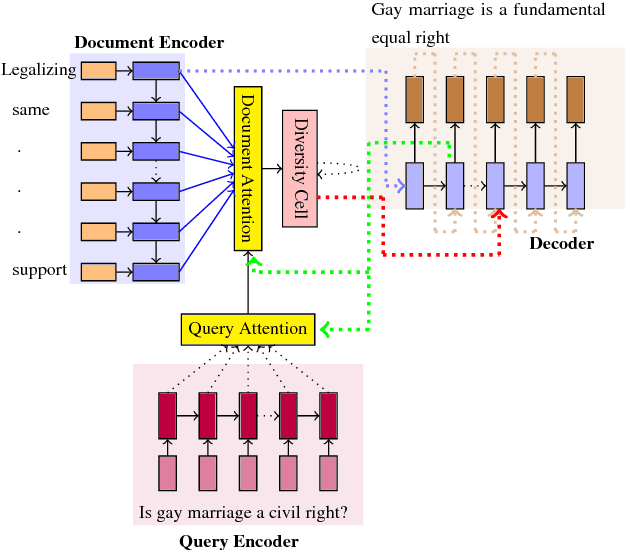
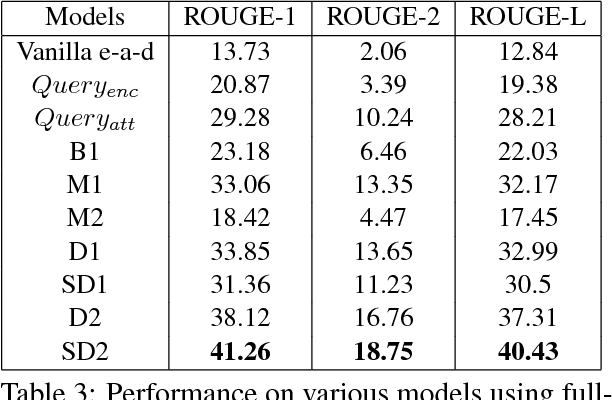
Abstractive summarization aims to generate a shorter version of the document covering all the salient points in a compact and coherent fashion. On the other hand, query-based summarization highlights those points that are relevant in the context of a given query. The encode-attend-decode paradigm has achieved notable success in machine translation, extractive summarization, dialog systems, etc. But it suffers from the drawback of generation of repeated phrases. In this work we propose a model for the query-based summarization task based on the encode-attend-decode paradigm with two key additions (i) a query attention model (in addition to document attention model) which learns to focus on different portions of the query at different time steps (instead of using a static representation for the query) and (ii) a new diversity based attention model which aims to alleviate the problem of repeating phrases in the summary. In order to enable the testing of this model we introduce a new query-based summarization dataset building on debatepedia. Our experiments show that with these two additions the proposed model clearly outperforms vanilla encode-attend-decode models with a gain of 28% (absolute) in ROUGE-L scores.
Language Expansion In Text-Based Games
May 17, 2018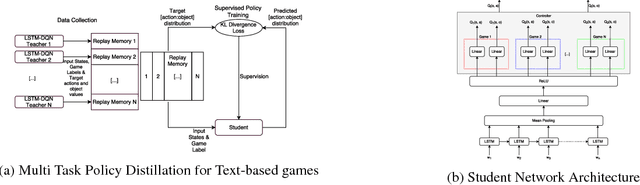
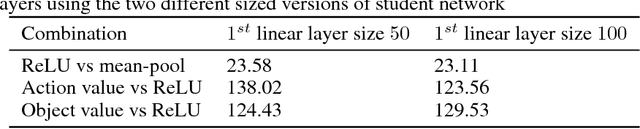
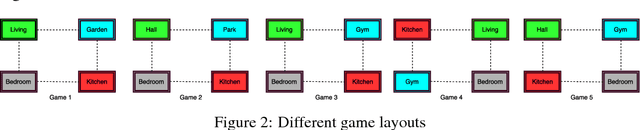
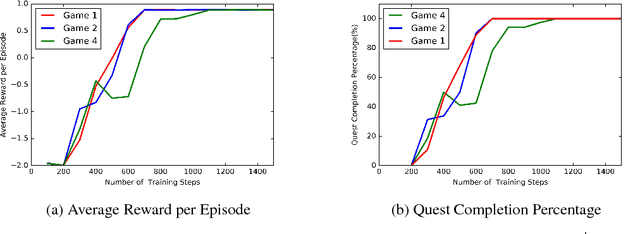
Text-based games are suitable test-beds for designing agents that can learn by interaction with the environment in the form of natural language text. Very recently, deep reinforcement learning based agents have been successfully applied for playing text-based games. In this paper, we explore the possibility of designing a single agent to play several text-based games and of expanding the agent's vocabulary using the vocabulary of agents trained for multiple games. To this extent, we explore the application of recently proposed policy distillation method for video games to the text-based game setting. We also use text-based games as a test-bed to analyze and hence understand policy distillation approach in detail.
DiGrad: Multi-Task Reinforcement Learning with Shared Actions
Feb 27, 2018
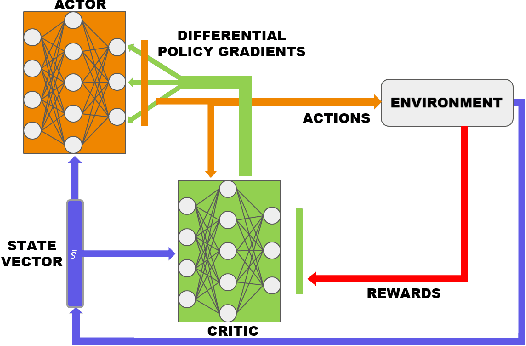
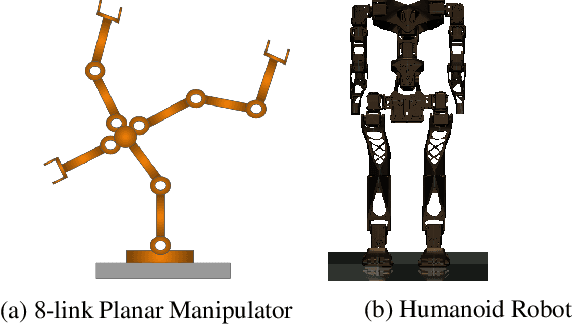
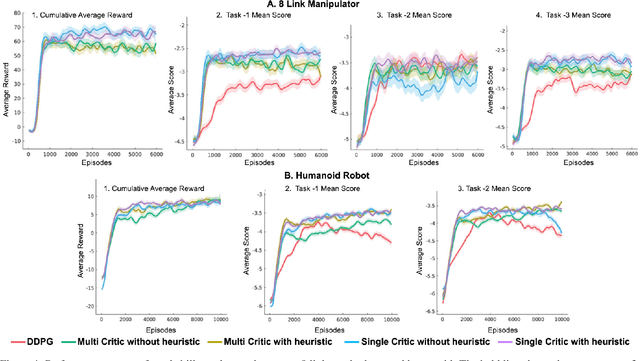
Most reinforcement learning algorithms are inefficient for learning multiple tasks in complex robotic systems, where different tasks share a set of actions. In such environments a compound policy may be learnt with shared neural network parameters, which performs multiple tasks concurrently. However such compound policy may get biased towards a task or the gradients from different tasks negate each other, making the learning unstable and sometimes less data efficient. In this paper, we propose a new approach for simultaneous training of multiple tasks sharing a set of common actions in continuous action spaces, which we call as DiGrad (Differential Policy Gradient). The proposed framework is based on differential policy gradients and can accommodate multi-task learning in a single actor-critic network. We also propose a simple heuristic in the differential policy gradient update to further improve the learning. The proposed architecture was tested on 8 link planar manipulator and 27 degrees of freedom(DoF) Humanoid for learning multi-goal reachability tasks for 3 and 2 end effectors respectively. We show that our approach supports efficient multi-task learning in complex robotic systems, outperforming related methods in continuous action spaces.
Recovering from Random Pruning: On the Plasticity of Deep Convolutional Neural Networks
Jan 31, 2018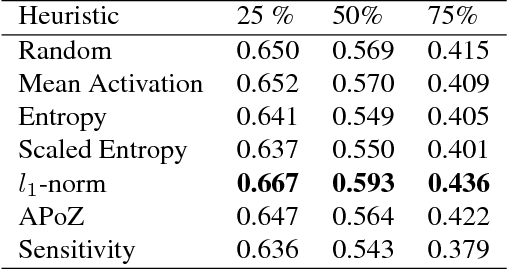
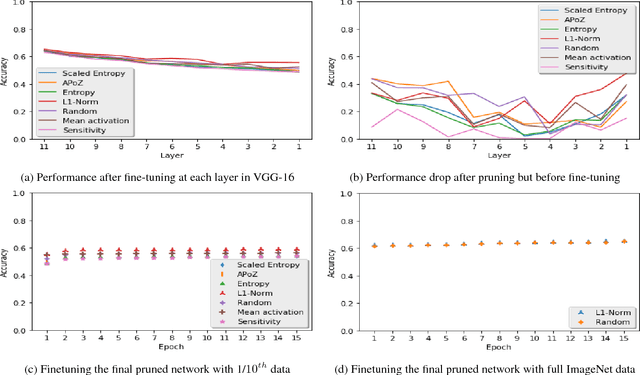
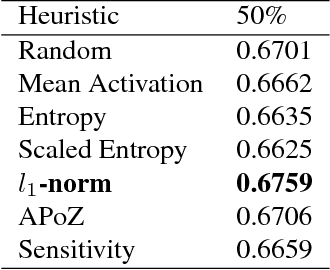
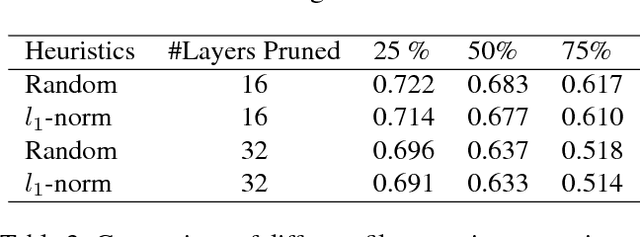
Recently there has been a lot of work on pruning filters from deep convolutional neural networks (CNNs) with the intention of reducing computations. The key idea is to rank the filters based on a certain criterion (say, $l_1$-norm, average percentage of zeros, etc) and retain only the top ranked filters. Once the low scoring filters are pruned away the remainder of the network is fine tuned and is shown to give performance comparable to the original unpruned network. In this work, we report experiments which suggest that the comparable performance of the pruned network is not due to the specific criterion chosen but due to the inherent plasticity of deep neural networks which allows them to recover from the loss of pruned filters once the rest of the filters are fine-tuned. Specifically, we show counter-intuitive results wherein by randomly pruning 25-50\% filters from deep CNNs we are able to obtain the same performance as obtained by using state of the art pruning methods. We empirically validate our claims by doing an exhaustive evaluation with VGG-16 and ResNet-50. Further, we also evaluate a real world scenario where a CNN trained on all 1000 ImageNet classes needs to be tested on only a small set of classes at test time (say, only animals). We create a new benchmark dataset from ImageNet to evaluate such class specific pruning and show that even here a random pruning strategy gives close to state of the art performance. Lastly, unlike existing approaches which mainly focus on the task of image classification, in this work we also report results on object detection. We show that using a simple random pruning strategy we can achieve significant speed up in object detection (74$\%$ improvement in fps) while retaining the same accuracy as that of the original Faster RCNN model.