 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvolutionary Approach to Security Games with Signaling
Apr 29, 2022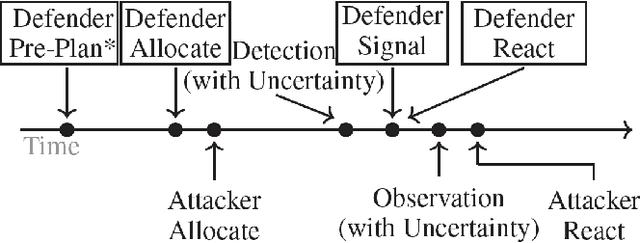
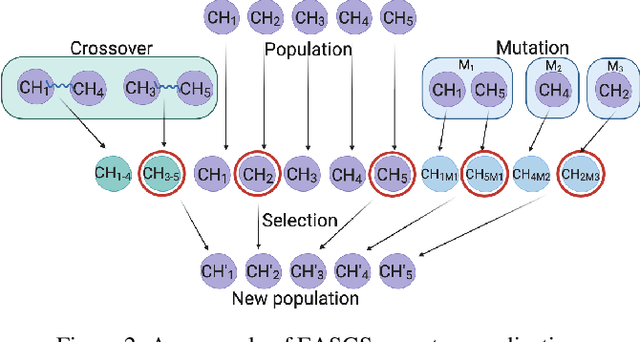
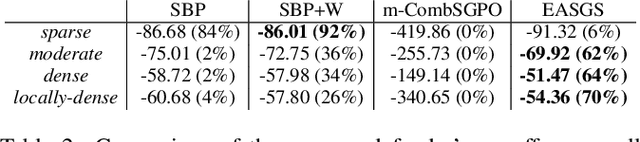
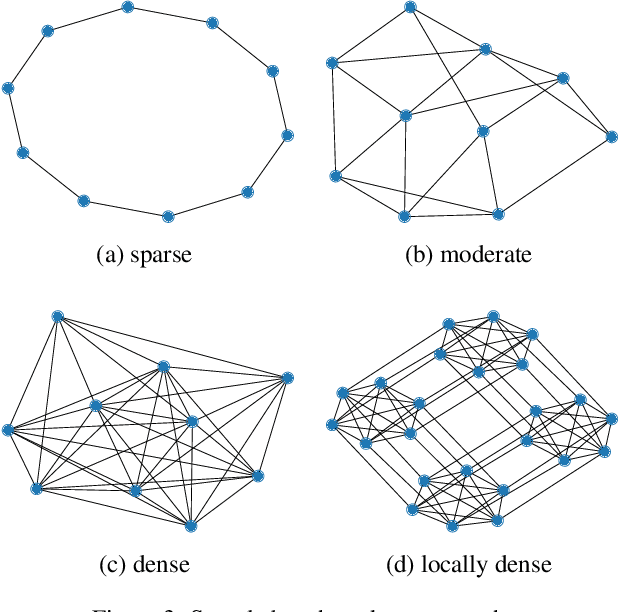
Green Security Games have become a popular way to model scenarios involving the protection of natural resources, such as wildlife. Sensors (e.g. drones equipped with cameras) have also begun to play a role in these scenarios by providing real-time information. Incorporating both human and sensor defender resources strategically is the subject of recent work on Security Games with Signaling (SGS). However, current methods to solve SGS do not scale well in terms of time or memory. We therefore propose a novel approach to SGS, which, for the first time in this domain, employs an Evolutionary Computation paradigm: EASGS. EASGS effectively searches the huge SGS solution space via suitable solution encoding in a chromosome and a specially-designed set of operators. The operators include three types of mutations, each focusing on a particular aspect of the SGS solution, optimized crossover and a local coverage improvement scheme (a memetic aspect of EASGS). We also introduce a new set of benchmark games, based on dense or locally-dense graphs that reflect real-world SGS settings. In the majority of 342 test game instances, EASGS outperforms state-of-the-art methods, including a reinforcement learning method, in terms of time scalability, nearly constant memory utilization, and quality of the returned defender's strategies (expected payoffs).
A survey in Adversarial Defences and Robustness in NLP
Apr 12, 2022
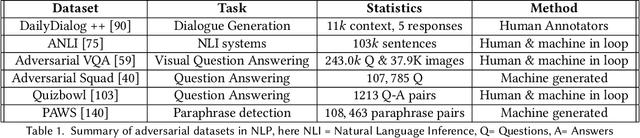
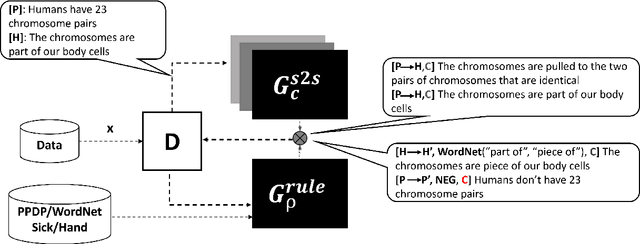

In recent years, it has been seen that deep neural networks are lacking robustness and are likely to break in case of adversarial perturbations in input data. Strong adversarial attacks are proposed by various authors for computer vision and Natural Language Processing (NLP). As a counter-effort, several defense mechanisms are also proposed to save these networks from failing. In contrast with image data, generating adversarial attacks and defending these models is not easy in NLP because of the discrete nature of the text data. However, numerous methods for adversarial defense are proposed of late, for different NLP tasks such as text classification, named entity recognition, natural language inferencing, etc. These methods are not just used for defending neural networks from adversarial attacks, but also used as a regularization mechanism during training, saving the model from overfitting. The proposed survey is an attempt to review different methods proposed for adversarial defenses in NLP in the recent past by proposing a novel taxonomy. This survey also highlights the fragility of the advanced deep neural networks in NLP and the challenges in defending them.
A Causal Approach for Unfair Edge Prioritization and Discrimination Removal
Nov 29, 2021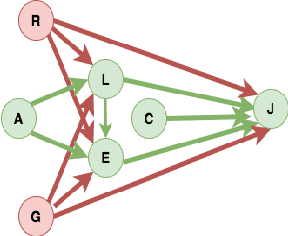
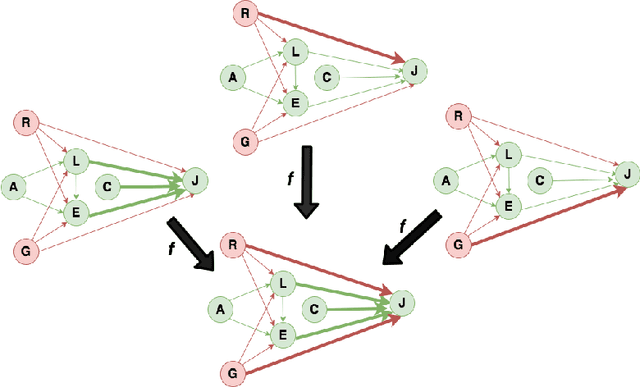
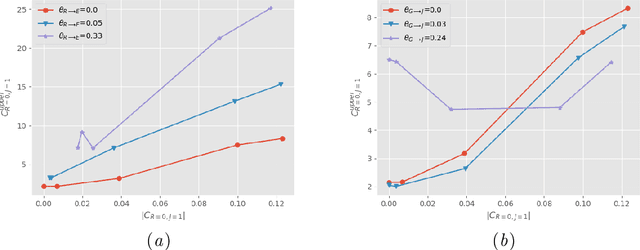
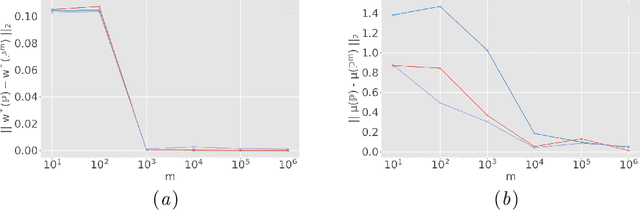
In budget-constrained settings aimed at mitigating unfairness, like law enforcement, it is essential to prioritize the sources of unfairness before taking measures to mitigate them in the real world. Unlike previous works, which only serve as a caution against possible discrimination and de-bias data after data generation, this work provides a toolkit to mitigate unfairness during data generation, given by the Unfair Edge Prioritization algorithm, in addition to de-biasing data after generation, given by the Discrimination Removal algorithm. We assume that a non-parametric Markovian causal model representative of the data generation procedure is given. The edges emanating from the sensitive nodes in the causal graph, such as race, are assumed to be the sources of unfairness. We first quantify Edge Flow in any edge X -> Y, which is the belief of observing a specific value of Y due to the influence of a specific value of X along X -> Y. We then quantify Edge Unfairness by formulating a non-parametric model in terms of edge flows. We then prove that cumulative unfairness towards sensitive groups in a decision, like race in a bail decision, is non-existent when edge unfairness is absent. We prove this result for the non-trivial non-parametric model setting when the cumulative unfairness cannot be expressed in terms of edge unfairness. We then measure the Potential to mitigate the Cumulative Unfairness when edge unfairness is decreased. Based on these measurements, we propose the Unfair Edge Prioritization algorithm that can then be used by policymakers. We also propose the Discrimination Removal Procedure that de-biases a data distribution by eliminating optimization constraints that grow exponentially in the number of sensitive attributes and values taken by them. Extensive experiments validate the theorem and specifications used for quantifying the above measures.
Smooth Imitation Learning via Smooth Costs and Smooth Policies
Nov 03, 2021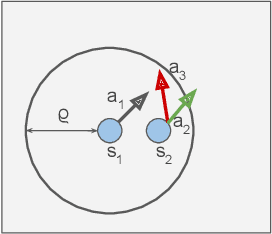
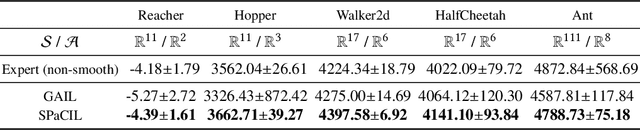
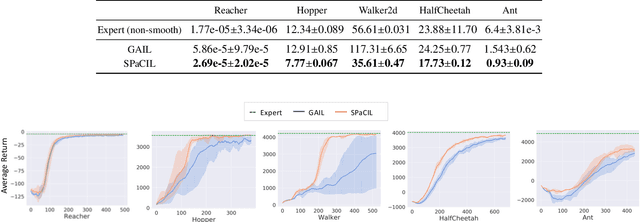
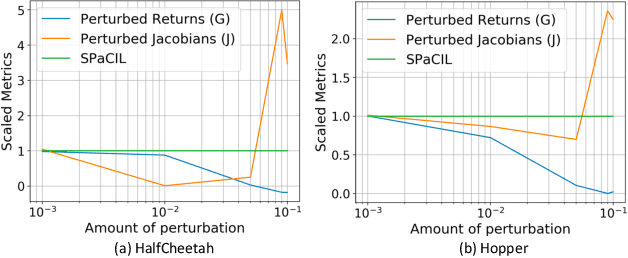
Imitation learning (IL) is a popular approach in the continuous control setting as among other reasons it circumvents the problems of reward mis-specification and exploration in reinforcement learning (RL). In IL from demonstrations, an important challenge is to obtain agent policies that are smooth with respect to the inputs. Learning through imitation a policy that is smooth as a function of a large state-action ($s$-$a$) space (typical of high dimensional continuous control environments) can be challenging. We take a first step towards tackling this issue by using smoothness inducing regularizers on \textit{both} the policy and the cost models of adversarial imitation learning. Our regularizers work by ensuring that the cost function changes in a controlled manner as a function of $s$-$a$ space; and the agent policy is well behaved with respect to the state space. We call our new smooth IL algorithm \textit{Smooth Policy and Cost Imitation Learning} (SPaCIL, pronounced 'Special'). We introduce a novel metric to quantify the smoothness of the learned policies. We demonstrate SPaCIL's superior performance on continuous control tasks from MuJoCo. The algorithm not just outperforms the state-of-the-art IL algorithm on our proposed smoothness metric, but, enjoys added benefits of faster learning and substantially higher average return.
Dynamic probabilistic logic models for effective abstractions in RL
Oct 15, 2021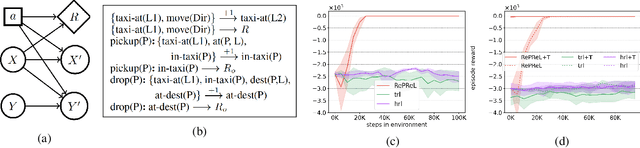
State abstraction enables sample-efficient learning and better task transfer in complex reinforcement learning environments. Recently, we proposed RePReL (Kokel et al. 2021), a hierarchical framework that leverages a relational planner to provide useful state abstractions for learning. We present a brief overview of this framework and the use of a dynamic probabilistic logic model to design these state abstractions. Our experiments show that RePReL not only achieves better performance and efficient learning on the task at hand but also demonstrates better generalization to unseen tasks.
Multi-Tailed, Multi-Headed, Spatial Dynamic Memory refined Text-to-Image Synthesis
Oct 15, 2021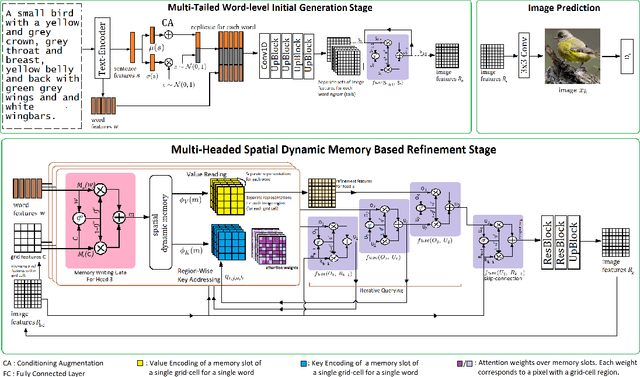


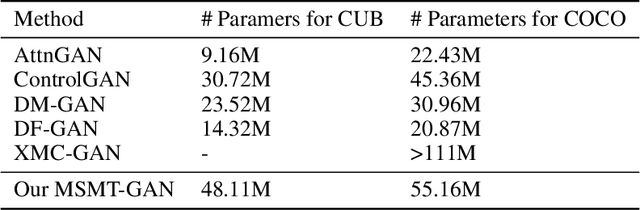
Synthesizing high-quality, realistic images from text-descriptions is a challenging task, and current methods synthesize images from text in a multi-stage manner, typically by first generating a rough initial image and then refining image details at subsequent stages. However, existing methods that follow this paradigm suffer from three important limitations. Firstly, they synthesize initial images without attempting to separate image attributes at a word-level. As a result, object attributes of initial images (that provide a basis for subsequent refinement) are inherently entangled and ambiguous in nature. Secondly, by using common text-representations for all regions, current methods prevent us from interpreting text in fundamentally different ways at different parts of an image. Different image regions are therefore only allowed to assimilate the same type of information from text at each refinement stage. Finally, current methods generate refinement features only once at each refinement stage and attempt to address all image aspects in a single shot. This single-shot refinement limits the precision with which each refinement stage can learn to improve the prior image. Our proposed method introduces three novel components to address these shortcomings: (1) An initial generation stage that explicitly generates separate sets of image features for each word n-gram. (2) A spatial dynamic memory module for refinement of images. (3) An iterative multi-headed mechanism to make it easier to improve upon multiple image aspects. Experimental results demonstrate that our Multi-Headed Spatial Dynamic Memory image refinement with our Multi-Tailed Word-level Initial Generation (MSMT-GAN) performs favourably against the previous state of the art on the CUB and COCO datasets.
Semi-Supervised Deep Learning for Multiplex Networks
Oct 05, 2021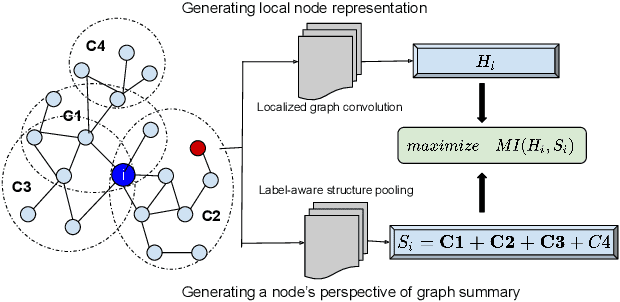
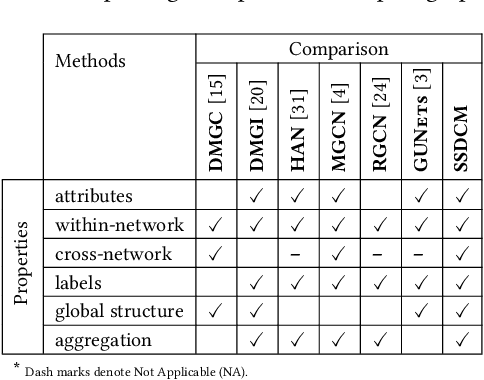
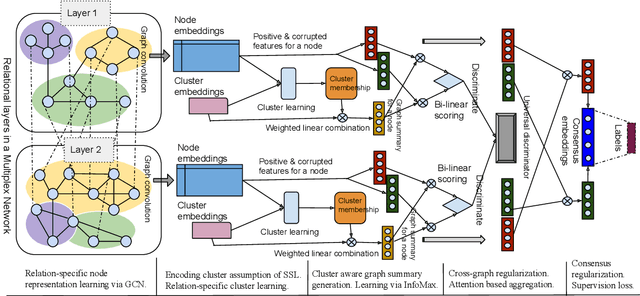
Multiplex networks are complex graph structures in which a set of entities are connected to each other via multiple types of relations, each relation representing a distinct layer. Such graphs are used to investigate many complex biological, social, and technological systems. In this work, we present a novel semi-supervised approach for structure-aware representation learning on multiplex networks. Our approach relies on maximizing the mutual information between local node-wise patch representations and label correlated structure-aware global graph representations to model the nodes and cluster structures jointly. Specifically, it leverages a novel cluster-aware, node-contextualized global graph summary generation strategy for effective joint-modeling of node and cluster representations across the layers of a multiplex network. Empirically, we demonstrate that the proposed architecture outperforms state-of-the-art methods in a range of tasks: classification, clustering, visualization, and similarity search on seven real-world multiplex networks for various experiment settings.
TAG: Task-based Accumulated Gradients for Lifelong learning
May 11, 2021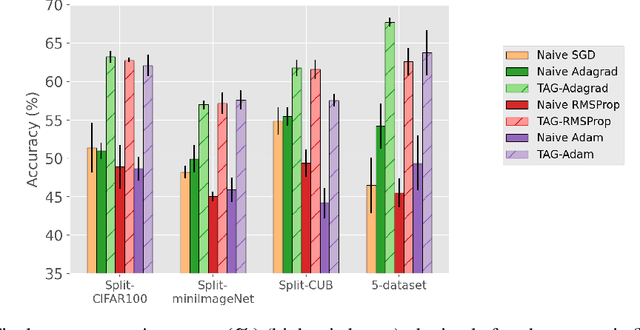
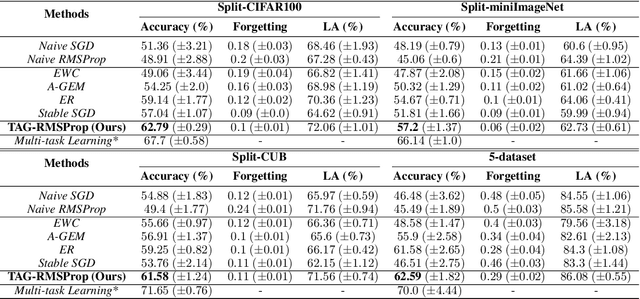
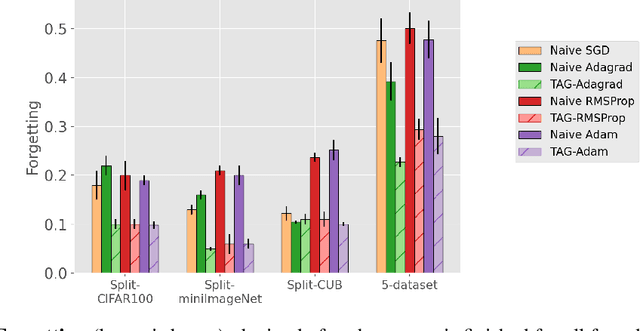
When an agent encounters a continual stream of new tasks in the lifelong learning setting, it leverages the knowledge it gained from the earlier tasks to help learn the new tasks better. In such a scenario, identifying an efficient knowledge representation becomes a challenging problem. Most research works propose to either store a subset of examples from the past tasks in a replay buffer, dedicate a separate set of parameters to each task or penalize excessive updates over parameters by introducing a regularization term. While existing methods employ the general task-agnostic stochastic gradient descent update rule, we propose a task-aware optimizer that adapts the learning rate based on the relatedness among tasks. We utilize the directions taken by the parameters during the updates by accumulating the gradients specific to each task. These task-based accumulated gradients act as a knowledge base that is maintained and updated throughout the stream. We empirically show that our proposed adaptive learning rate not only accounts for catastrophic forgetting but also allows positive backward transfer. We also show that our method performs better than several state-of-the-art methods in lifelong learning on complex datasets with a large number of tasks.
Selective Intervention Planning using Restless Multi-Armed Bandits to Improve Maternal and Child Health Outcomes
Apr 05, 2021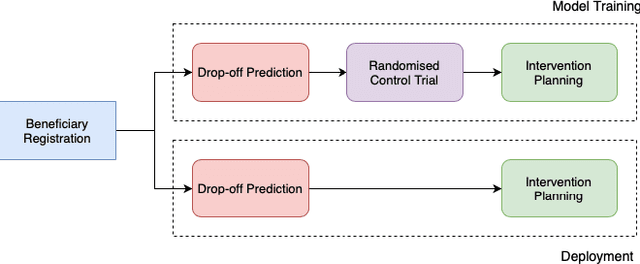
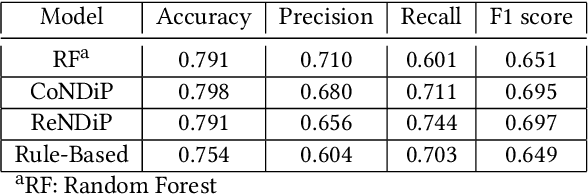
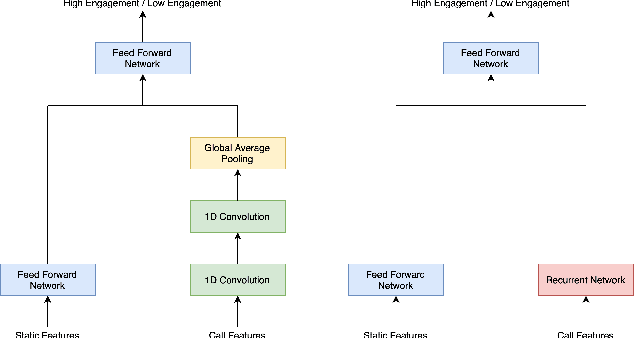
India has a maternal mortality ratio of 113 and child mortality ratio of 2830 per 100,000 live births. Lack of access to preventive care information is a major contributing factor for these deaths, especially in low resource households. We partner with ARMMAN, a non-profit based in India employing a call-based information program to disseminate health-related information to pregnant women and women with recent child deliveries. We analyze call records of over 300,000 women registered in the program created by ARMMAN and try to identify women who might not engage with these call programs that are proven to result in positive health outcomes. We built machine learning based models to predict the long term engagement pattern from call logs and beneficiaries' demographic information, and discuss the applicability of this method in the real world through a pilot validation. Through a randomized controlled trial, we show that using our model's predictions to make interventions boosts engagement metrics by 61.37%. We then formulate the intervention planning problem as restless multi-armed bandits (RMABs), and present preliminary results using this approach.
Hyperedge Prediction using Tensor Eigenvalue Decomposition
Feb 06, 2021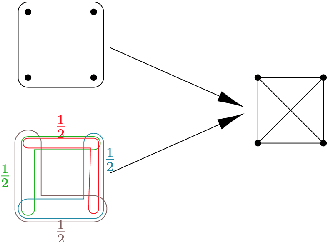
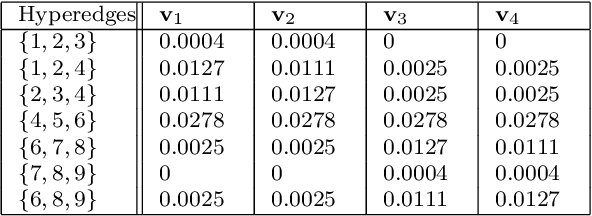
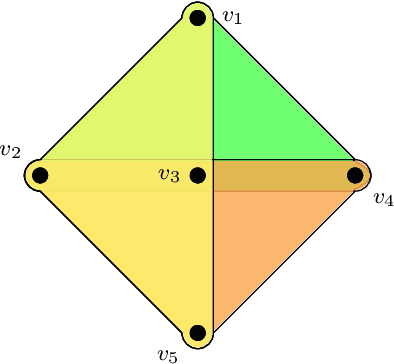
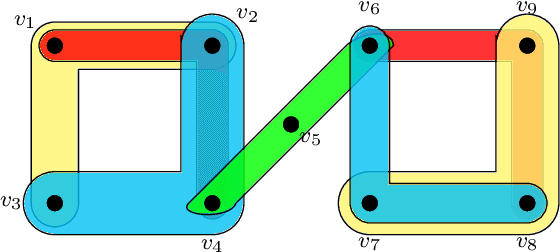
Link prediction in graphs is studied by modeling the dyadic interactions among two nodes. The relationships can be more complex than simple dyadic interactions and could require the user to model super-dyadic associations among nodes. Such interactions can be modeled using a hypergraph, which is a generalization of a graph where a hyperedge can connect more than two nodes. In this work, we consider the problem of hyperedge prediction in a $k-$uniform hypergraph. We utilize the tensor-based representation of hypergraphs and propose a novel interpretation of the tensor eigenvectors. This is further used to propose a hyperedge prediction algorithm. The proposed algorithm utilizes the \textit{Fiedler} eigenvector computed using tensor eigenvalue decomposition of hypergraph Laplacian. The \textit{Fiedler} eigenvector is used to evaluate the construction cost of new hyperedges, which is further utilized to determine the most probable hyperedges to be constructed. The functioning and efficacy of the proposed method are illustrated using some example hypergraphs and a few real datasets. The code for the proposed method is available on https://github.com/d-maurya/hypred_ tensorEVD