 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Clustering Strikes Back: Building Cost-Effective and High-Performance ANNS at Scale with Helmsman
Jun 11, 2026RedNote (a.k.a., Xiaohongshu, a global-scale social network platform) widely adopts approximate nearest neighbor search (ANNS) to power its search, recommendation, and advertising services. Due to the demanding Service Level Agreements (SLAs), we have to rely on in-memory graph-based ANNS (i.e., HNSW) to provide high throughput and low latency. However, the ever-growing user base and content volume have led to an explosive increase in memory footprint and consequently huge CapEx and OpEx. After exploring various alternatives, we find that building a clustering-based ANNS on top of all-flash servers can be promising. Yet, we still experience severe overheads from the kernel I/O stack, a fixed pruning strategy, and slow index construction. We present HELMSMAN, a high-performance and cost-effective clustering-based ANNS system, which combines an ANNS-oriented userspace storage stack, a leveling-learned pruning module, and GPU-accelerated pipelines of construction. HELMSMAN saves over 90% of hardware costs and enables billion-scale index (re)builds within hours. In the current production deployment, operating stably for several months, 40 machines now host ANNS workloads that previously required about 35,000 cores and 0.35 PB DRAM.
CCD-Level and Load-Aware Thread Orchestration for In-Memory Vector ANNS on Multi-Core CPUs
May 11, 2026Vector approximate nearest neighbor search (ANNS) underpins search engines, recommendation systems, and advertising services. Recent advances in ANNS indexes make CPU a cost-effective choice for serving million-scale, in-memory vector search, yet per-core throughput remains constrained by memory access latency of vector reading and the compute intensity of distance evaluations in production deployments. With the growing scale of the business and advances in hardware, modern CCD-based multi-core CPUs have been widely deployed for high throughput in our services. However, we find that simply increasing core counts does not yield optimal performance scaling. To improve the efficiency of more cores from the CCD-based architecture, we analyze the distributions of real-world requests in our production environments. We observe high access locality in vector search in our online services and low cache utilization, resulting from overlooking the multi-chiplet nature of CCD based CPUs. Hence, we propose a workload- and hardware-aware thread orchestration framework at CCD-level that (i) provides a uniform interface for both inter-query parallel HNSW search and intra-query parallel IVF search, (ii) achieves cache-friendly and workload-adaptive mapping of task dispatching, and (iii) employs CCD-aware task stealing to address load imbalance. Applied to real production workloads from search, recommendation, and advertising services of Xiaohongshu (RedNote), our approach delivers up to 3.7x higher throughput and 30-90% reductions in P50 and P999 latency. In detail, compared with the original framework, the cache-miss ratio decreases by 6-30%, and the total CPU stall is reduced by 20-80%.
CBR-Net: Cascade Boundary Refinement Network for Action Detection: Submission to ActivityNet Challenge 2020 (Task 1)
Jun 24, 2020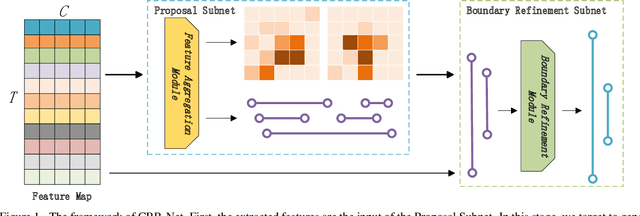
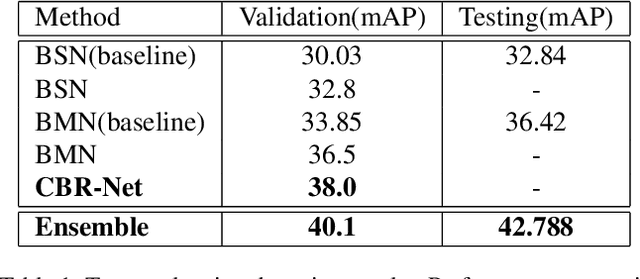
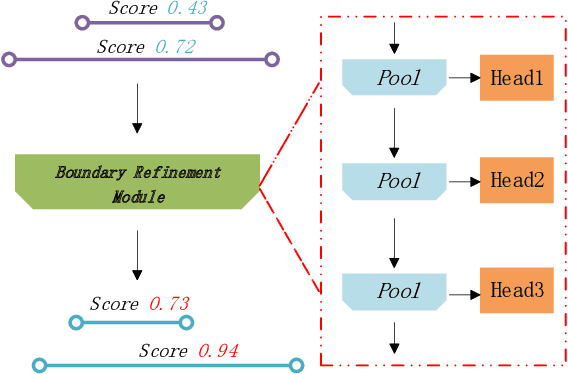

In this report, we present our solution for the task of temporal action localization (detection) (task 1) in ActivityNet Challenge 2020. The purpose of this task is to temporally localize intervals where actions of interest occur and predict the action categories in a long untrimmed video. Our solution mainly includes three components: 1) feature encoding: we apply three kinds of backbones, including TSN [7], Slowfast[3] and I3d[1], which are both pretrained on Kinetics dataset[2]. Applying these models, we can extract snippet-level video representations; 2) proposal generation: we choose BMN [5] as our baseline, base on which we design a Cascade Boundary Refinement Network (CBR-Net) to conduct proposal detection. The CBR-Net mainly contains two modules: temporal feature encoding, which applies BiLSTM to encode long-term temporal information; CBR module, which targets to refine the proposal precision under different parameter settings; 3) action localization: In this stage, we combine the video-level classification results obtained by the fine tuning networks to predict the category of each proposal. Moreover, we also apply to different ensemble strategies to improve the performance of the designed solution, by which we achieve 42.788% on the testing set of ActivityNet v1.3 dataset in terms of mean Average Precision metrics.