 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCBR-Net: Cascade Boundary Refinement Network for Action Detection: Submission to ActivityNet Challenge 2020 (Task 1)
Jun 24, 2020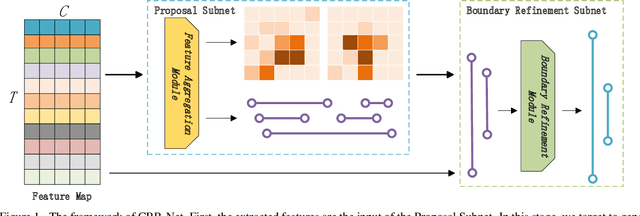
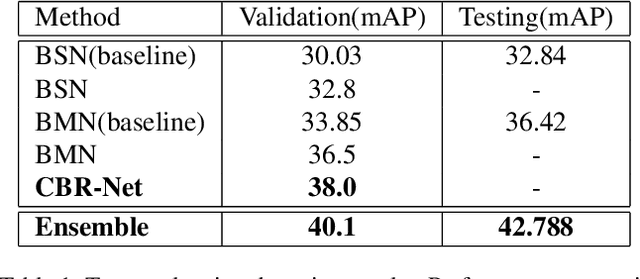
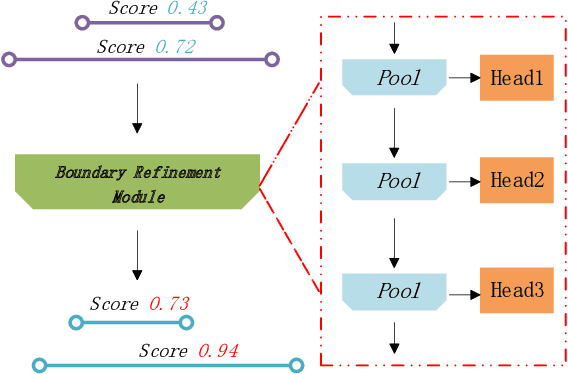

In this report, we present our solution for the task of temporal action localization (detection) (task 1) in ActivityNet Challenge 2020. The purpose of this task is to temporally localize intervals where actions of interest occur and predict the action categories in a long untrimmed video. Our solution mainly includes three components: 1) feature encoding: we apply three kinds of backbones, including TSN [7], Slowfast[3] and I3d[1], which are both pretrained on Kinetics dataset[2]. Applying these models, we can extract snippet-level video representations; 2) proposal generation: we choose BMN [5] as our baseline, base on which we design a Cascade Boundary Refinement Network (CBR-Net) to conduct proposal detection. The CBR-Net mainly contains two modules: temporal feature encoding, which applies BiLSTM to encode long-term temporal information; CBR module, which targets to refine the proposal precision under different parameter settings; 3) action localization: In this stage, we combine the video-level classification results obtained by the fine tuning networks to predict the category of each proposal. Moreover, we also apply to different ensemble strategies to improve the performance of the designed solution, by which we achieve 42.788% on the testing set of ActivityNet v1.3 dataset in terms of mean Average Precision metrics.
Temporal Fusion Network for Temporal Action Localization:Submission to ActivityNet Challenge 2020 (Task E)
Jun 13, 2020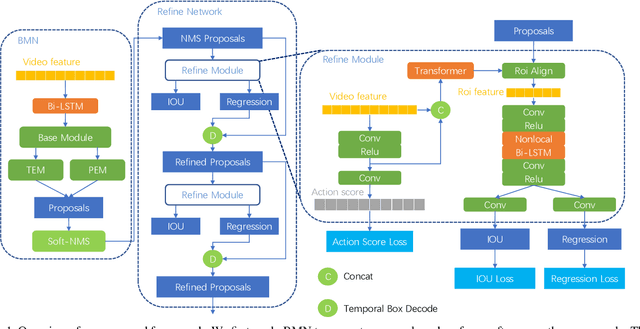
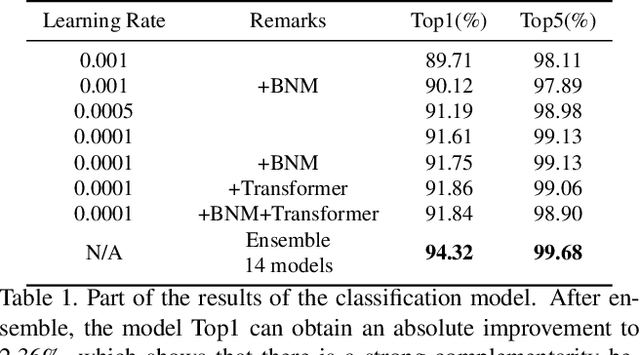

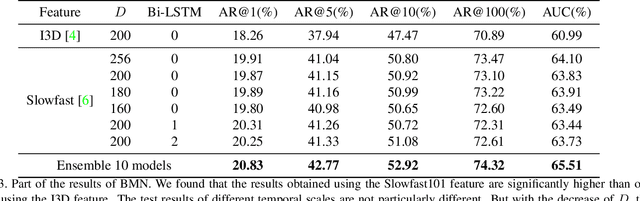
This technical report analyzes a temporal action localization method we used in the HACS competition which is hosted in Activitynet Challenge 2020.The goal of our task is to locate the start time and end time of the action in the untrimmed video, and predict action category.Firstly, we utilize the video-level feature information to train multiple video-level action classification models. In this way, we can get the category of action in the video.Secondly, we focus on generating high quality temporal proposals.For this purpose, we apply BMN to generate a large number of proposals to obtain high recall rates. We then refine these proposals by employing a cascade structure network called Refine Network, which can predict position offset and new IOU under the supervision of ground truth.To make the proposals more accurate, we use bidirectional LSTM, Nonlocal and Transformer to capture temporal relationships between local features of each proposal and global features of the video data.Finally, by fusing the results of multiple models, our method obtains 40.55% on the validation set and 40.53% on the test set in terms of mAP, and achieves Rank 1 in this challenge.