 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow Do Large Language Monkeys Get Their Power (Laws)?
Feb 24, 2025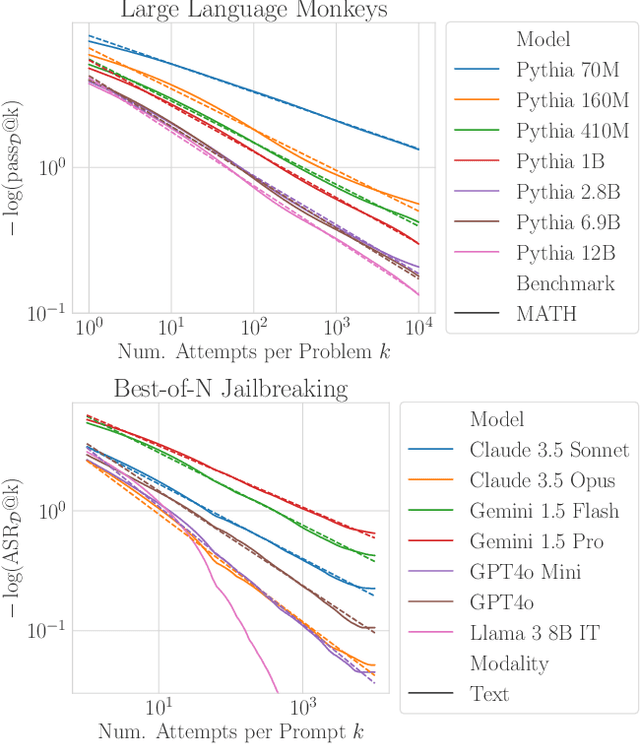
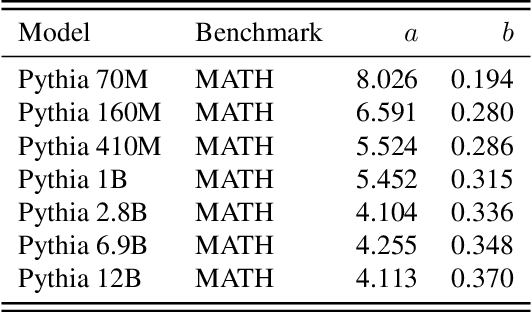
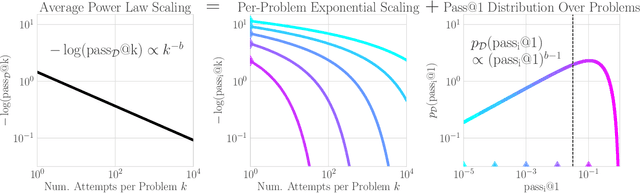
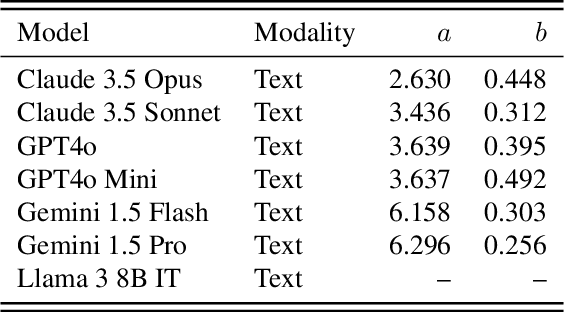
Recent research across mathematical problem solving, proof assistant programming and multimodal jailbreaking documents a striking finding: when (multimodal) language model tackle a suite of tasks with multiple attempts per task -- succeeding if any attempt is correct -- then the negative log of the average success rate scales a power law in the number of attempts. In this work, we identify an apparent puzzle: a simple mathematical calculation predicts that on each problem, the failure rate should fall exponentially with the number of attempts. We confirm this prediction empirically, raising a question: from where does aggregate polynomial scaling emerge? We then answer this question by demonstrating per-problem exponential scaling can be made consistent with aggregate polynomial scaling if the distribution of single-attempt success probabilities is heavy tailed such that a small fraction of tasks with extremely low success probabilities collectively warp the aggregate success trend into a power law - even as each problem scales exponentially on its own. We further demonstrate that this distributional perspective explains previously observed deviations from power law scaling, and provides a simple method for forecasting the power law exponent with an order of magnitude lower relative error, or equivalently, ${\sim}2-4$ orders of magnitude less inference compute. Overall, our work contributes to a better understanding of how neural language model performance improves with scaling inference compute and the development of scaling-predictable evaluations of (multimodal) language models.
CodeMonkeys: Scaling Test-Time Compute for Software Engineering
Jan 24, 2025Scaling test-time compute is a promising axis for improving LLM capabilities. However, test-time compute can be scaled in a variety of ways, and effectively combining different approaches remains an active area of research. Here, we explore this problem in the context of solving real-world GitHub issues from the SWE-bench dataset. Our system, named CodeMonkeys, allows models to iteratively edit a codebase by jointly generating and running a testing script alongside their draft edit. We sample many of these multi-turn trajectories for every issue to generate a collection of candidate edits. This approach lets us scale "serial" test-time compute by increasing the number of iterations per trajectory and "parallel" test-time compute by increasing the number of trajectories per problem. With parallel scaling, we can amortize up-front costs across multiple downstream samples, allowing us to identify relevant codebase context using the simple method of letting an LLM read every file. In order to select between candidate edits, we combine voting using model-generated tests with a final multi-turn trajectory dedicated to selection. Overall, CodeMonkeys resolves 57.4% of issues from SWE-bench Verified using a budget of approximately 2300 USD. Our selection method can also be used to combine candidates from different sources. Selecting over an ensemble of edits from existing top SWE-bench Verified submissions obtains a score of 66.2% and outperforms the best member of the ensemble on its own. We fully release our code and data at https://scalingintelligence.stanford.edu/pubs/codemonkeys.
That Chip Has Sailed: A Critique of Unfounded Skepticism Around AI for Chip Design
Nov 15, 2024



In 2020, we introduced a deep reinforcement learning method capable of generating superhuman chip layouts, which we then published in Nature and open-sourced on GitHub. AlphaChip has inspired an explosion of work on AI for chip design, and has been deployed in state-of-the-art chips across Alphabet and extended by external chipmakers. Even so, a non-peer-reviewed invited paper at ISPD 2023 questioned its performance claims, despite failing to run our method as described in Nature. For example, it did not pre-train the RL method (removing its ability to learn from prior experience), used substantially fewer compute resources (20x fewer RL experience collectors and half as many GPUs), did not train to convergence (standard practice in machine learning), and evaluated on test cases that are not representative of modern chips. Recently, Igor Markov published a meta-analysis of three papers: our peer-reviewed Nature paper, the non-peer-reviewed ISPD paper, and Markov's own unpublished paper (though he does not disclose that he co-authored it). Although AlphaChip has already achieved widespread adoption and impact, we publish this response to ensure that no one is wrongly discouraged from innovating in this impactful area.
Large Language Monkeys: Scaling Inference Compute with Repeated Sampling
Jul 31, 2024



Scaling the amount of compute used to train language models has dramatically improved their capabilities. However, when it comes to inference, we often limit the amount of compute to only one attempt per problem. Here, we explore inference compute as another axis for scaling by increasing the number of generated samples. Across multiple tasks and models, we observe that coverage - the fraction of problems solved by any attempt - scales with the number of samples over four orders of magnitude. In domains like coding and formal proofs, where all answers can be automatically verified, these increases in coverage directly translate into improved performance. When we apply repeated sampling to SWE-bench Lite, the fraction of issues solved with DeepSeek-V2-Coder-Instruct increases from 15.9% with one sample to 56% with 250 samples, outperforming the single-attempt state-of-the-art of 43% which uses more capable frontier models. Moreover, using current API pricing, amplifying the cheaper DeepSeek model with five samples is more cost-effective and solves more issues than paying a premium for one sample from GPT-4o or Claude 3.5 Sonnet. Interestingly, the relationship between coverage and the number of samples is often log-linear and can be modelled with an exponentiated power law, suggesting the existence of inference-time scaling laws. Finally, we find that identifying correct samples out of many generations remains an important direction for future research in domains without automatic verifiers. When solving math word problems from GSM8K and MATH, coverage with Llama-3 models grows to over 95% with 10,000 samples. However, common methods to pick correct solutions from a sample collection, such as majority voting or reward models, plateau beyond several hundred samples and fail to fully scale with the sample budget.
Training of Physical Neural Networks
Jun 05, 2024



Physical neural networks (PNNs) are a class of neural-like networks that leverage the properties of physical systems to perform computation. While PNNs are so far a niche research area with small-scale laboratory demonstrations, they are arguably one of the most underappreciated important opportunities in modern AI. Could we train AI models 1000x larger than current ones? Could we do this and also have them perform inference locally and privately on edge devices, such as smartphones or sensors? Research over the past few years has shown that the answer to all these questions is likely "yes, with enough research": PNNs could one day radically change what is possible and practical for AI systems. To do this will however require rethinking both how AI models work, and how they are trained - primarily by considering the problems through the constraints of the underlying hardware physics. To train PNNs at large scale, many methods including backpropagation-based and backpropagation-free approaches are now being explored. These methods have various trade-offs, and so far no method has been shown to scale to the same scale and performance as the backpropagation algorithm widely used in deep learning today. However, this is rapidly changing, and a diverse ecosystem of training techniques provides clues for how PNNs may one day be utilized to create both more efficient realizations of current-scale AI models, and to enable unprecedented-scale models.
CHESS: Contextual Harnessing for Efficient SQL Synthesis
May 27, 2024



Utilizing large language models (LLMs) for transforming natural language questions into SQL queries (text-to-SQL) is a promising yet challenging approach, particularly when applied to real-world databases with complex and extensive schemas. In particular, effectively incorporating data catalogs and database values for SQL generation remains an obstacle, leading to suboptimal solutions. We address this problem by proposing a new pipeline that effectively retrieves relevant data and context, selects an efficient schema, and synthesizes correct and efficient SQL queries. To increase retrieval precision, our pipeline introduces a hierarchical retrieval method leveraging model-generated keywords, locality-sensitive hashing indexing, and vector databases. Additionally, we have developed an adaptive schema pruning technique that adjusts based on the complexity of the problem and the model's context size. Our approach generalizes to both frontier proprietary models like GPT-4 and open-source models such as Llama-3-70B. Through a series of ablation studies, we demonstrate the effectiveness of each component of our pipeline and its impact on the end-to-end performance. Our method achieves new state-of-the-art performance on the cross-domain challenging BIRD dataset.
CATS: Contextually-Aware Thresholding for Sparsity in Large Language Models
Apr 12, 2024Large Language Models (LLMs) have dramatically advanced AI applications, yet their deployment remains challenging due to their immense inference costs. Recent studies ameliorate the computational costs of LLMs by increasing their activation sparsity but suffer from significant performance degradation on downstream tasks. In this work, we introduce a new framework for sparsifying the activations of base LLMs and reducing inference costs, dubbed Contextually Aware Thresholding for Sparsity (CATS). CATS is relatively simple, easy to implement, and highly effective. At the heart of our framework is a new non-linear activation function. We demonstrate that CATS can be applied to various base models, including Mistral-7B and Llama2-7B, and outperforms existing sparsification techniques in downstream task performance. More precisely, CATS-based models often achieve downstream task performance within 1-2% of their base models without any fine-tuning and even at activation sparsity levels of 50%. Furthermore, CATS-based models converge faster and display better task performance than competing techniques when fine-tuning is applied. Finally, we develop a custom GPU kernel for efficient implementation of CATS that translates the activation of sparsity of CATS to real wall-clock time speedups. Our custom kernel implementation of CATS results in a ~15% improvement in wall-clock inference latency of token generation on both Llama-7B and Mistral-7B.
Hydragen: High-Throughput LLM Inference with Shared Prefixes
Feb 07, 2024



Transformer-based large language models (LLMs) are now deployed to hundreds of millions of users. LLM inference is commonly performed on batches of sequences that share a prefix, such as few-shot examples or a chatbot system prompt. Decoding in this large-batch setting can be bottlenecked by the attention operation, which reads large key-value (KV) caches from memory and computes inefficient matrix-vector products for every sequence in the batch. In this work, we introduce Hydragen, a hardware-aware exact implementation of attention with shared prefixes. Hydragen computes attention over the shared prefix and unique suffixes separately. This decomposition enables efficient prefix attention by batching queries together across sequences, reducing redundant memory reads and enabling the use of hardware-friendly matrix multiplications. Our method can improve end-to-end LLM throughput by up to 32x against competitive baselines, with speedup growing with the batch size and shared prefix length. Hydragen also enables the use of very long shared contexts: with a high batch size, increasing the prefix length from 1K to 16K tokens decreases Hydragen throughput by less than 15%, while the throughput of baselines drops by over 90%. Hydragen generalizes beyond simple prefix-suffix decomposition and can be applied to tree-based prompt sharing patterns, allowing us to further reduce inference time on competitive programming problems by 55%.
Specific versus General Principles for Constitutional AI
Oct 20, 2023



Human feedback can prevent overtly harmful utterances in conversational models, but may not automatically mitigate subtle problematic behaviors such as a stated desire for self-preservation or power. Constitutional AI offers an alternative, replacing human feedback with feedback from AI models conditioned only on a list of written principles. We find this approach effectively prevents the expression of such behaviors. The success of simple principles motivates us to ask: can models learn general ethical behaviors from only a single written principle? To test this, we run experiments using a principle roughly stated as "do what's best for humanity". We find that the largest dialogue models can generalize from this short constitution, resulting in harmless assistants with no stated interest in specific motivations like power. A general principle may thus partially avoid the need for a long list of constitutions targeting potentially harmful behaviors. However, more detailed constitutions still improve fine-grained control over specific types of harms. This suggests both general and specific principles have value for steering AI safely.
Embroid: Unsupervised Prediction Smoothing Can Improve Few-Shot Classification
Jul 20, 2023



Recent work has shown that language models' (LMs) prompt-based learning capabilities make them well suited for automating data labeling in domains where manual annotation is expensive. The challenge is that while writing an initial prompt is cheap, improving a prompt is costly -- practitioners often require significant labeled data in order to evaluate the impact of prompt modifications. Our work asks whether it is possible to improve prompt-based learning without additional labeled data. We approach this problem by attempting to modify the predictions of a prompt, rather than the prompt itself. Our intuition is that accurate predictions should also be consistent: samples which are similar under some feature representation should receive the same prompt prediction. We propose Embroid, a method which computes multiple representations of a dataset under different embedding functions, and uses the consistency between the LM predictions for neighboring samples to identify mispredictions. Embroid then uses these neighborhoods to create additional predictions for each sample, and combines these predictions with a simple latent variable graphical model in order to generate a final corrected prediction. In addition to providing a theoretical analysis of Embroid, we conduct a rigorous empirical evaluation across six different LMs and up to 95 different tasks. We find that (1) Embroid substantially improves performance over original prompts (e.g., by an average of 7.3 points on GPT-JT), (2) also realizes improvements for more sophisticated prompting strategies (e.g., chain-of-thought), and (3) can be specialized to domains like law through the embedding functions.