 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStorySage: Conversational Autobiography Writing Powered by a Multi-Agent Framework
Jun 17, 2025Every individual carries a unique and personal life story shaped by their memories and experiences. However, these memories are often scattered and difficult to organize into a coherent narrative, a challenge that defines the task of autobiography writing. Existing conversational writing assistants tend to rely on generic user interactions and pre-defined guidelines, making it difficult for these systems to capture personal memories and develop a complete biography over time. We introduce StorySage, a user-driven software system designed to meet the needs of a diverse group of users that supports a flexible conversation and a structured approach to autobiography writing. Powered by a multi-agent framework composed of an Interviewer, Session Scribe, Planner, Section Writer, and Session Coordinator, our system iteratively collects user memories, updates their autobiography, and plans for future conversations. In experimental simulations, StorySage demonstrates its ability to navigate multiple sessions and capture user memories across many conversations. User studies (N=28) highlight how StorySage maintains improved conversational flow, narrative completeness, and higher user satisfaction when compared to a baseline. In summary, StorySage contributes both a novel architecture for autobiography writing and insights into how multi-agent systems can enhance human-AI creative partnerships.
When to Trust Context: Self-Reflective Debates for Context Reliability
Jun 06, 2025



Large language models frequently encounter conflicts between their parametric knowledge and contextual input, often resulting in factual inconsistencies or hallucinations. We propose Self-Reflective Debate for Contextual Reliability (SR-DCR), a lightweight framework that integrates token-level self-confidence with an asymmetric multi-agent debate to adjudicate such conflicts. A critic, deprived of context, challenges a defender who argues from the given passage; a judge model evaluates the debate and determines the context's reliability. The final answer is selected by combining the verdict with model confidence. Experiments on the ClashEval benchmark demonstrate that SR-DCR consistently enhances robustness to misleading context while maintaining accuracy on trustworthy inputs, outperforming both classical debate and confidence-only baselines with minimal computational overhead. The code is available at https://github.com/smiles724/Self-Reflective-Debates.
SPRINT: Enabling Interleaved Planning and Parallelized Execution in Reasoning Models
Jun 06, 2025Large reasoning models (LRMs) excel at complex reasoning tasks but typically generate lengthy sequential chains-of-thought, resulting in long inference times before arriving at the final answer. To address this challenge, we introduce SPRINT, a novel post-training and inference-time framework designed to enable LRMs to dynamically identify and exploit opportunities for parallelization during their reasoning process. SPRINT incorporates an innovative data curation pipeline that reorganizes natural language reasoning trajectories into structured rounds of long-horizon planning and parallel execution. By fine-tuning LRMs on a small amount of such curated data, the models learn to dynamically identify independent subtasks within extended reasoning processes and effectively execute them in parallel. Through extensive evaluations, we show that the models fine-tuned with the SPRINT framework match the performance of reasoning models on complex domains such as mathematics while generating up to ~39% fewer sequential tokens on problems requiring more than 8000 output tokens. Finally, we observe consistent results transferred to two out-of-distribution tasks of GPQA and Countdown with up to 45% and 65% reduction in average sequential tokens for longer reasoning trajectories, while achieving the performance of the fine-tuned reasoning model.
Reasoning-SQL: Reinforcement Learning with SQL Tailored Partial Rewards for Reasoning-Enhanced Text-to-SQL
Apr 01, 2025



Text-to-SQL is a challenging task involving multiple reasoning-intensive subtasks, including natural language understanding, database schema comprehension, and precise SQL query formulation. Existing approaches often rely on handcrafted reasoning paths with inductive biases that can limit their overall effectiveness. Motivated by the recent success of reasoning-enhanced models such as DeepSeek R1 and OpenAI o1, which effectively leverage reward-driven self-exploration to enhance reasoning capabilities and generalization, we propose a novel set of partial rewards tailored specifically for the Text-to-SQL task. Our reward set includes schema-linking, AI feedback, n-gram similarity, and syntax check, explicitly designed to address the reward sparsity issue prevalent in reinforcement learning (RL). Leveraging group relative policy optimization (GRPO), our approach explicitly encourages large language models (LLMs) to develop intrinsic reasoning skills necessary for accurate SQL query generation. With models of different sizes, we demonstrate that RL-only training with our proposed rewards consistently achieves higher accuracy and superior generalization compared to supervised fine-tuning (SFT). Remarkably, our RL-trained 14B-parameter model significantly outperforms larger proprietary models, e.g. o3-mini by 4% and Gemini-1.5-Pro-002 by 3% on the BIRD benchmark. These highlight the efficacy of our proposed RL-training framework with partial rewards for enhancing both accuracy and reasoning capabilities in Text-to-SQL tasks.
CHASE-SQL: Multi-Path Reasoning and Preference Optimized Candidate Selection in Text-to-SQL
Oct 02, 2024



In tackling the challenges of large language model (LLM) performance for Text-to-SQL tasks, we introduce CHASE-SQL, a new framework that employs innovative strategies, using test-time compute in multi-agent modeling to improve candidate generation and selection. CHASE-SQL leverages LLMs' intrinsic knowledge to generate diverse and high-quality SQL candidates using different LLM generators with: (1) a divide-and-conquer method that decomposes complex queries into manageable sub-queries in a single LLM call; (2) chain-of-thought reasoning based on query execution plans, reflecting the steps a database engine takes during execution; and (3) a unique instance-aware synthetic example generation technique, which offers specific few-shot demonstrations tailored to test questions.To identify the best candidate, a selection agent is employed to rank the candidates through pairwise comparisons with a fine-tuned binary-candidates selection LLM. This selection approach has been demonstrated to be more robust over alternatives. The proposed generators-selector framework not only enhances the quality and diversity of SQL queries but also outperforms previous methods. Overall, our proposed CHASE-SQL achieves the state-of-the-art execution accuracy of 73.0% and 73.01% on the test set and development set of the notable BIRD Text-to-SQL dataset benchmark, rendering CHASE-SQL the top submission of the leaderboard (at the time of paper submission).
OptiMUS-0.3: Using Large Language Models to Model and Solve Optimization Problems at Scale
Jul 29, 2024



Optimization problems are pervasive in sectors from manufacturing and distribution to healthcare. However, most such problems are still solved heuristically by hand rather than optimally by state-of-the art solvers because the expertise required to formulate and solve these problems limits the widespread adoption of optimization tools and techniques. We introduce a Large Language Model (LLM)-based system designed to formulate and solve (mixed integer) linear programming problems from their natural language descriptions. Our system is capable of developing mathematical models, writing and debugging solver code, evaluating the generated solutions, and improving efficiency and correctness of its model and code based on these evaluations. OptiMUS-0.3 utilizes a modular structure to process problems, allowing it to handle problems with long descriptions and complex data without long prompts. Experiments demonstrate that OptiMUS-0.3 outperforms existing state-of-the-art methods on easy datasets by more than 12% and on hard datasets (including a new dataset, NLP4LP, released with this paper that features long and complex problems) by more than 8%.
CHESS: Contextual Harnessing for Efficient SQL Synthesis
May 27, 2024



Utilizing large language models (LLMs) for transforming natural language questions into SQL queries (text-to-SQL) is a promising yet challenging approach, particularly when applied to real-world databases with complex and extensive schemas. In particular, effectively incorporating data catalogs and database values for SQL generation remains an obstacle, leading to suboptimal solutions. We address this problem by proposing a new pipeline that effectively retrieves relevant data and context, selects an efficient schema, and synthesizes correct and efficient SQL queries. To increase retrieval precision, our pipeline introduces a hierarchical retrieval method leveraging model-generated keywords, locality-sensitive hashing indexing, and vector databases. Additionally, we have developed an adaptive schema pruning technique that adjusts based on the complexity of the problem and the model's context size. Our approach generalizes to both frontier proprietary models like GPT-4 and open-source models such as Llama-3-70B. Through a series of ablation studies, we demonstrate the effectiveness of each component of our pipeline and its impact on the end-to-end performance. Our method achieves new state-of-the-art performance on the cross-domain challenging BIRD dataset.
Hybrid Decentralized Optimization: First- and Zeroth-Order Optimizers Can Be Jointly Leveraged For Faster Convergence
Oct 14, 2022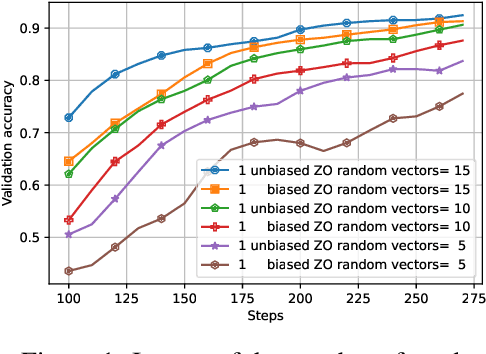
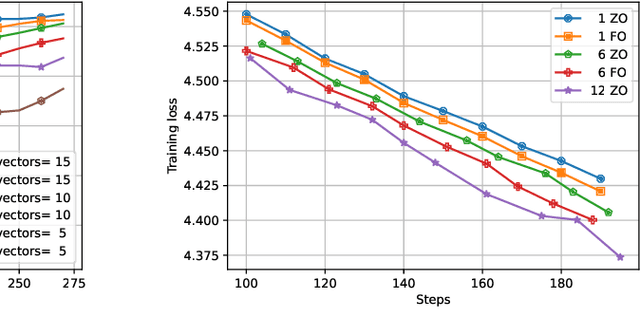
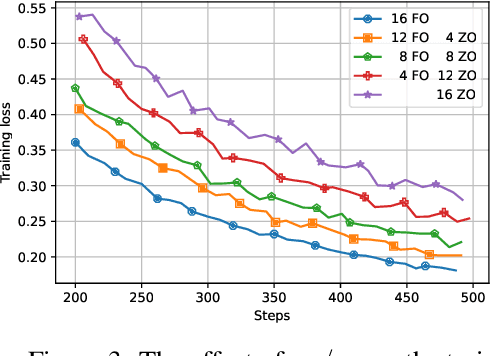
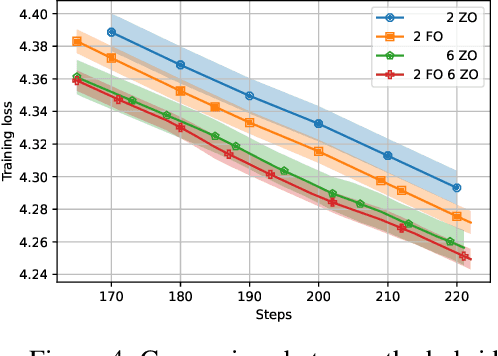
Distributed optimization has become one of the standard ways of speeding up machine learning training, and most of the research in the area focuses on distributed first-order, gradient-based methods. Yet, there are settings where some computationally-bounded nodes may not be able to implement first-order, gradient-based optimization, while they could still contribute to joint optimization tasks. In this paper, we initiate the study of hybrid decentralized optimization, studying settings where nodes with zeroth-order and first-order optimization capabilities co-exist in a distributed system, and attempt to jointly solve an optimization task over some data distribution. We essentially show that, under reasonable parameter settings, such a system can not only withstand noisier zeroth-order agents but can even benefit from integrating such agents into the optimization process, rather than ignoring their information. At the core of our approach is a new analysis of distributed optimization with noisy and possibly-biased gradient estimators, which may be of independent interest. Experimental results on standard optimization tasks confirm our analysis, showing that hybrid first-zeroth order optimization can be practical.
QuAFL: Federated Averaging Can Be Both Asynchronous and Communication-Efficient
Jun 22, 2022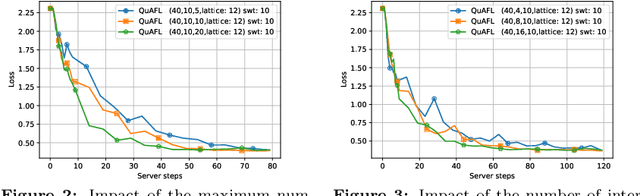
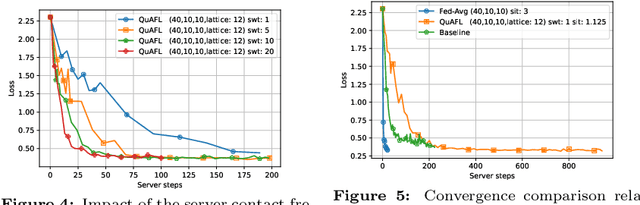
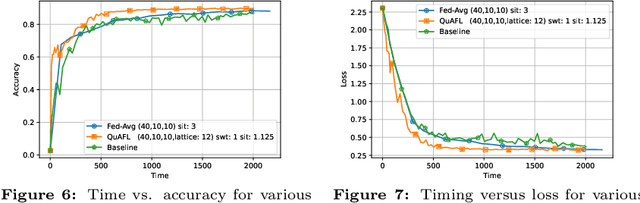
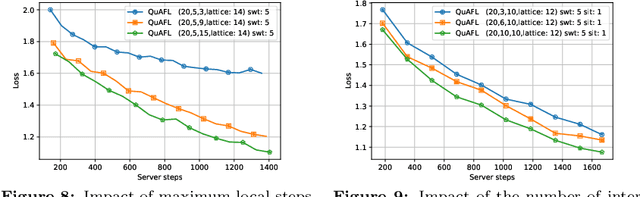
Federated Learning (FL) is an emerging paradigm to enable the large-scale distributed training of machine learning models, while still providing privacy guarantees. In this work, we jointly address two of the main practical challenges when scaling federated optimization to large node counts: the need for tight synchronization between the central authority and individual computing nodes, and the large communication cost of transmissions between the central server and clients. Specifically, we present a new variant of the classic federated averaging (FedAvg) algorithm, which supports both asynchronous communication and communication compression. We provide a new analysis technique showing that, in spite of these system relaxations, our algorithm essentially matches the best known bounds for FedAvg, under reasonable parameter settings. On the experimental side, we show that our algorithm ensures fast practical convergence for standard federated tasks.