 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMinions: Cost-efficient Collaboration Between On-device and Cloud Language Models
Feb 21, 2025We investigate an emerging setup in which a small, on-device language model (LM) with access to local data communicates with a frontier, cloud-hosted LM to solve real-world tasks involving financial, medical, and scientific reasoning over long documents. Can a local-remote collaboration reduce cloud inference costs while preserving quality? First, we consider a naive collaboration protocol where the local and remote models simply chat back and forth. Because only the local model reads the full context, this protocol achieves a 30.4x reduction in remote costs, but recovers only 87% of the performance of the frontier model. We identify two key limitations of this protocol: the local model struggles to (1) follow the remote model's multi-step instructions and (2) reason over long contexts. Motivated by these observations, we study an extension of this protocol, coined MinionS, in which the remote model decomposes the task into easier subtasks over shorter chunks of the document, that are executed locally in parallel. MinionS reduces costs by 5.7x on average while recovering 97.9% of the performance of the remote model alone. Our analysis reveals several key design choices that influence the trade-off between cost and performance in local-remote systems.
The Mamba in the Llama: Distilling and Accelerating Hybrid Models
Aug 27, 2024Linear RNN architectures, like Mamba, can be competitive with Transformer models in language modeling while having advantageous deployment characteristics. Given the focus on training large-scale Transformer models, we consider the challenge of converting these pretrained models for deployment. We demonstrate that it is feasible to distill large Transformers into linear RNNs by reusing the linear projection weights from attention layers with academic GPU resources. The resulting hybrid model, which incorporates a quarter of the attention layers, achieves performance comparable to the original Transformer in chat benchmarks and outperforms open-source hybrid Mamba models trained from scratch with trillions of tokens in both chat benchmarks and general benchmarks. Moreover, we introduce a hardware-aware speculative decoding algorithm that accelerates the inference speed of Mamba and hybrid models. Overall we show how, with limited computation resources, we can remove many of the original attention layers and generate from the resulting model more efficiently. Our top-performing model, distilled from Llama3-8B-Instruct, achieves a 29.61 length-controlled win rate on AlpacaEval 2 against GPT-4 and 7.35 on MT-Bench, surpassing the best instruction-tuned linear RNN model.
SpecExec: Massively Parallel Speculative Decoding for Interactive LLM Inference on Consumer Devices
Jun 04, 2024As large language models gain widespread adoption, running them efficiently becomes crucial. Recent works on LLM inference use speculative decoding to achieve extreme speedups. However, most of these works implicitly design their algorithms for high-end datacenter hardware. In this work, we ask the opposite question: how fast can we run LLMs on consumer machines? Consumer GPUs can no longer fit the largest available models (50B+ parameters) and must offload them to RAM or SSD. When running with offloaded parameters, the inference engine can process batches of hundreds or thousands of tokens at the same time as just one token, making it a natural fit for speculative decoding. We propose SpecExec (Speculative Execution), a simple parallel decoding method that can generate up to 20 tokens per target model iteration for popular LLM families. It utilizes the high spikiness of the token probabilities distribution in modern LLMs and a high degree of alignment between model output probabilities. SpecExec takes the most probable tokens continuation from the draft model to build a "cache" tree for the target model, which then gets validated in a single pass. Using SpecExec, we demonstrate inference of 50B+ parameter LLMs on consumer GPUs with RAM offloading at 4-6 tokens per second with 4-bit quantization or 2-3 tokens per second with 16-bit weights.
Sequoia: Scalable, Robust, and Hardware-aware Speculative Decoding
Feb 29, 2024



As the usage of large language models (LLMs) grows, performing efficient inference with these models becomes increasingly important. While speculative decoding has recently emerged as a promising direction for speeding up inference, existing methods are limited in their ability to scale to larger speculation budgets, and adapt to different hyperparameters and hardware. This paper introduces Sequoia, a scalable, robust, and hardware-aware algorithm for speculative decoding. To attain better scalability, Sequoia introduces a dynamic programming algorithm to find the optimal tree structure for the speculated tokens. To achieve robust speculative performance, Sequoia uses a novel sampling and verification method that outperforms prior work across different decoding temperatures. Finally, Sequoia introduces a hardware-aware tree optimizer that maximizes speculative performance by automatically selecting the token tree size and depth for a given hardware platform. Evaluation shows that Sequoia improves the decoding speed of Llama2-7B, Llama2-13B, and Vicuna-33B on an A100 by up to $4.04\times$, $3.73\times$, and $2.27\times$. For offloading setting on L40, Sequoia achieves as low as 0.56 s/token for exact Llama2-70B inference latency, which is $9.96\times$ on our optimized offloading system (5.6 s/token), $9.7\times$ than DeepSpeed-Zero-Inference, $19.5\times$ than Huggingface Accelerate.
Audio-visual fine-tuning of audio-only ASR models
Dec 14, 2023


Audio-visual automatic speech recognition (AV-ASR) models are very effective at reducing word error rates on noisy speech, but require large amounts of transcribed AV training data. Recently, audio-visual self-supervised learning (SSL) approaches have been developed to reduce this dependence on transcribed AV data, but these methods are quite complex and computationally expensive. In this work, we propose replacing these expensive AV-SSL methods with a simple and fast \textit{audio-only} SSL method, and then performing AV supervised fine-tuning. We show that this approach is competitive with state-of-the-art (SOTA) AV-SSL methods on the LRS3-TED benchmark task (within 0.5% absolute WER), while being dramatically simpler and more efficient (12-30x faster to pre-train). Furthermore, we show we can extend this approach to convert a SOTA audio-only ASR model into an AV model. By doing so, we match SOTA AV-SSL results, even though no AV data was used during pre-training.
Contextual Embeddings: When Are They Worth It?
May 18, 2020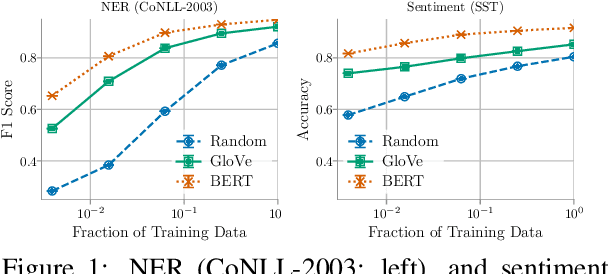
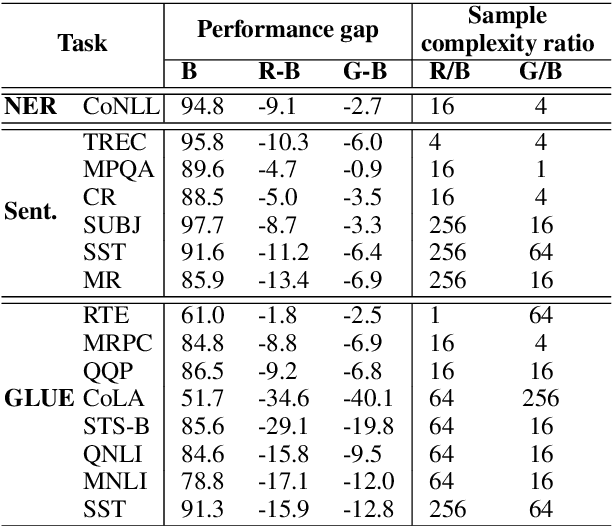
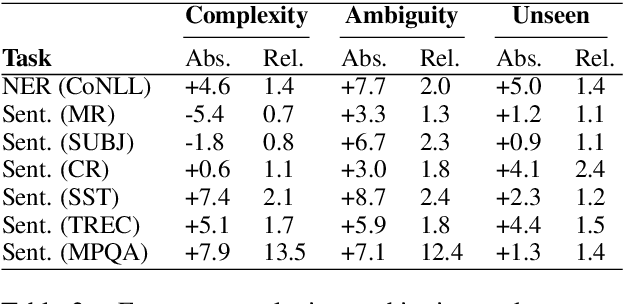
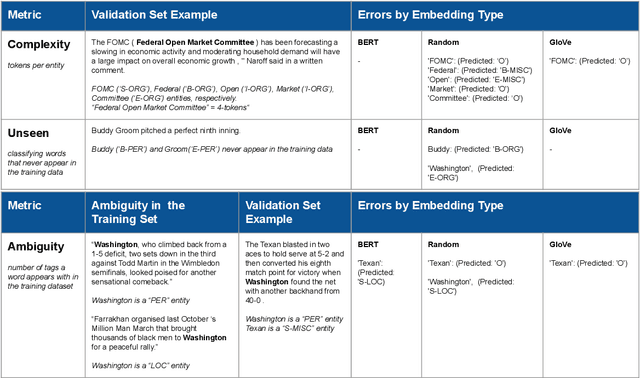
We study the settings for which deep contextual embeddings (e.g., BERT) give large improvements in performance relative to classic pretrained embeddings (e.g., GloVe), and an even simpler baseline---random word embeddings---focusing on the impact of the training set size and the linguistic properties of the task. Surprisingly, we find that both of these simpler baselines can match contextual embeddings on industry-scale data, and often perform within 5 to 10% accuracy (absolute) on benchmark tasks. Furthermore, we identify properties of data for which contextual embeddings give particularly large gains: language containing complex structure, ambiguous word usage, and words unseen in training.
Understanding the Downstream Instability of Word Embeddings
Feb 29, 2020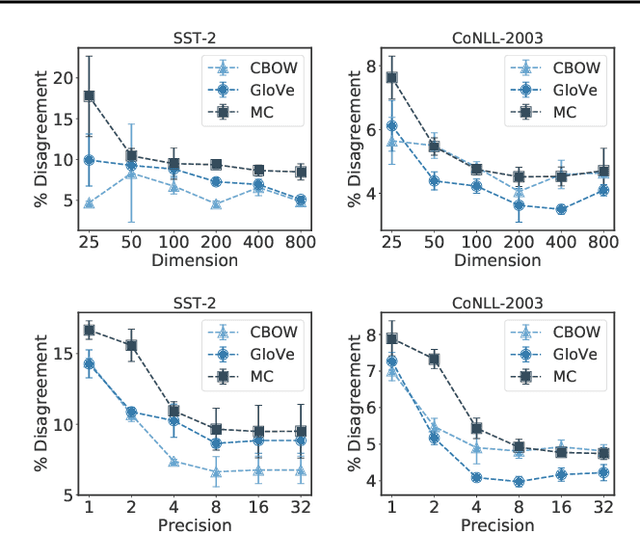

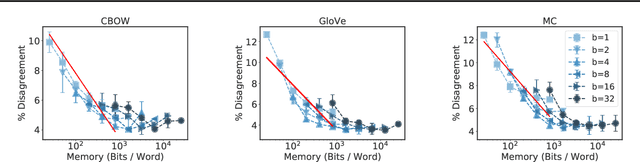
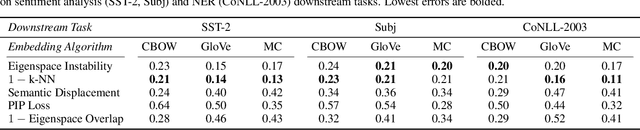
Many industrial machine learning (ML) systems require frequent retraining to keep up-to-date with constantly changing data. This retraining exacerbates a large challenge facing ML systems today: model training is unstable, i.e., small changes in training data can cause significant changes in the model's predictions. In this paper, we work on developing a deeper understanding of this instability, with a focus on how a core building block of modern natural language processing (NLP) pipelines---pre-trained word embeddings---affects the instability of downstream NLP models. We first empirically reveal a tradeoff between stability and memory: increasing the embedding memory 2x can reduce the disagreement in predictions due to small changes in training data by 5% to 37% (relative). To theoretically explain this tradeoff, we introduce a new measure of embedding instability---the eigenspace instability measure---which we prove bounds the disagreement in downstream predictions introduced by the change in word embeddings. Practically, we show that the eigenspace instability measure can be a cost-effective way to choose embedding parameters to minimize instability without training downstream models, outperforming other embedding distance measures and performing competitively with a nearest neighbor-based measure. Finally, we demonstrate that the observed stability-memory tradeoffs extend to other types of embeddings as well, including knowledge graph and contextual word embeddings.
On the Downstream Performance of Compressed Word Embeddings
Sep 03, 2019
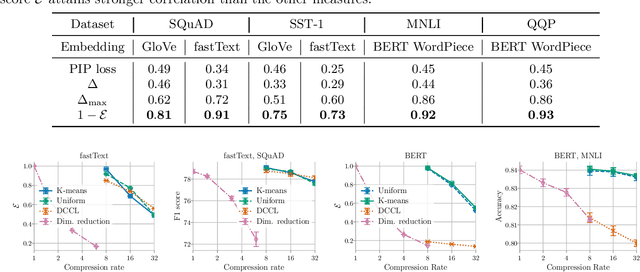
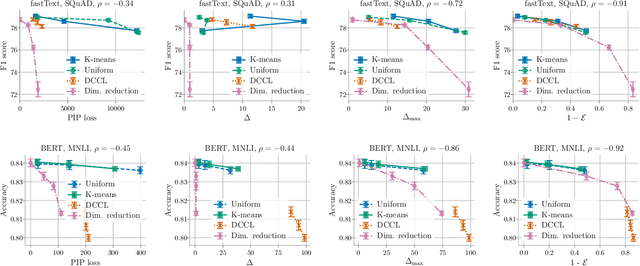
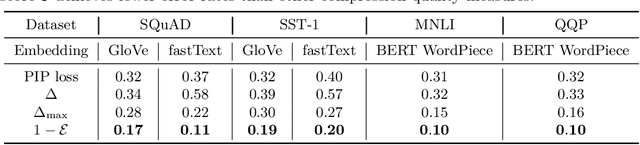
Compressing word embeddings is important for deploying NLP models in memory-constrained settings. However, understanding what makes compressed embeddings perform well on downstream tasks is challenging---existing measures of compression quality often fail to distinguish between embeddings that perform well and those that do not. We thus propose the eigenspace overlap score as a new measure. We relate the eigenspace overlap score to downstream performance by developing generalization bounds for the compressed embeddings in terms of this score, in the context of linear and logistic regression. We then show that we can lower bound the eigenspace overlap score for a simple uniform quantization compression method, helping to explain the strong empirical performance of this method. Finally, we show that by using the eigenspace overlap score as a selection criterion between embeddings drawn from a representative set we compressed, we can efficiently identify the better performing embedding with up to $2\times$ lower selection error rates than the next best measure of compression quality, and avoid the cost of training a model for each task of interest.
Low-Precision Random Fourier Features for Memory-Constrained Kernel Approximation
Oct 31, 2018
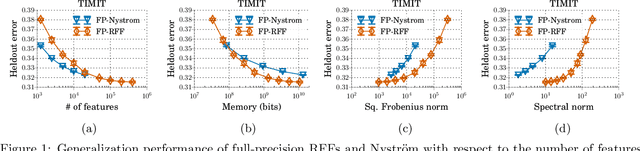
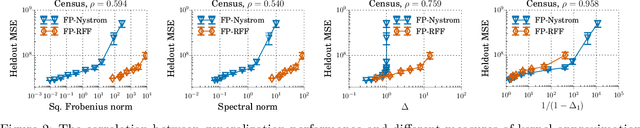

We investigate how to train kernel approximation methods that generalize well under a memory budget. Building on recent theoretical work, we define a measure of kernel approximation error which we find to be much more predictive of the empirical generalization performance of kernel approximation methods than conventional metrics. An important consequence of this definition is that a kernel approximation matrix must be high-rank to attain close approximation. Because storing a high-rank approximation is memory-intensive, we propose using a low-precision quantization of random Fourier features (LP-RFFs) to build a high-rank approximation under a memory budget. Theoretically, we show quantization has a negligible effect on generalization performance in important settings. Empirically, we demonstrate across four benchmark datasets that LP-RFFs can match the performance of full-precision RFFs and the Nystr\"{o}m method, with 3x-10x and 50x-460x less memory, respectively.
Kernel Approximation Methods for Speech Recognition
Jan 13, 2017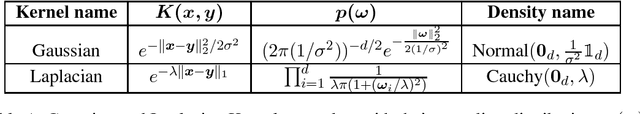
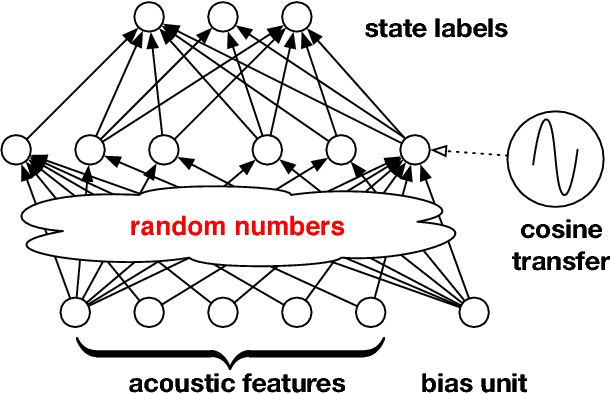
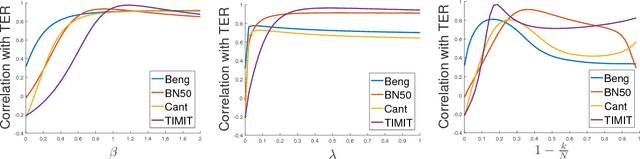

We study large-scale kernel methods for acoustic modeling in speech recognition and compare their performance to deep neural networks (DNNs). We perform experiments on four speech recognition datasets, including the TIMIT and Broadcast News benchmark tasks, and compare these two types of models on frame-level performance metrics (accuracy, cross-entropy), as well as on recognition metrics (word/character error rate). In order to scale kernel methods to these large datasets, we use the random Fourier feature method of Rahimi and Recht (2007). We propose two novel techniques for improving the performance of kernel acoustic models. First, in order to reduce the number of random features required by kernel models, we propose a simple but effective method for feature selection. The method is able to explore a large number of non-linear features while maintaining a compact model more efficiently than existing approaches. Second, we present a number of frame-level metrics which correlate very strongly with recognition performance when computed on the heldout set; we take advantage of these correlations by monitoring these metrics during training in order to decide when to stop learning. This technique can noticeably improve the recognition performance of both DNN and kernel models, while narrowing the gap between them. Additionally, we show that the linear bottleneck method of Sainath et al. (2013) improves the performance of our kernel models significantly, in addition to speeding up training and making the models more compact. Together, these three methods dramatically improve the performance of kernel acoustic models, making their performance comparable to DNNs on the tasks we explored.