 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeM1: Towards Scalable Test-Time Compute with Mamba Reasoning Models
Apr 14, 2025Effective reasoning is crucial to solving complex mathematical problems. Recent large language models (LLMs) have boosted performance by scaling test-time computation through long chain-of-thought reasoning. However, transformer-based models are inherently limited in extending context length due to their quadratic computational complexity and linear memory requirements. In this paper, we introduce a novel hybrid linear RNN reasoning model, M1, built on the Mamba architecture, which allows memory-efficient inference. Our approach leverages a distillation process from existing reasoning models and is further enhanced through RL training. Experimental results on the AIME and MATH benchmarks show that M1 not only outperforms previous linear RNN models but also matches the performance of state-of-the-art Deepseek R1 distilled reasoning models at a similar scale. We also compare our generation speed with a highly performant general purpose inference engine, vLLM, and observe more than a 3x speedup compared to a same size transformer. With throughput speedup, we are able to achieve higher accuracy compared to DeepSeek R1 distilled transformer reasoning models under a fixed generation time budget using self-consistency voting. Overall, we introduce a hybrid Mamba reasoning model and provide a more effective approach to scaling test-time generation using self-consistency or long chain of thought reasoning.
Thinking Slow, Fast: Scaling Inference Compute with Distilled Reasoners
Feb 27, 2025Recent advancements have demonstrated that the performance of large language models (LLMs) can be significantly enhanced by scaling computational resources at test time. A common strategy involves generating multiple Chain-of-Thought (CoT) trajectories and aggregating their outputs through various selection mechanisms. This raises a fundamental question: can models with lower complexity leverage their superior generation throughput to outperform similarly sized Transformers for a fixed computational budget? To address this question and overcome the lack of strong subquadratic reasoners, we distill pure and hybrid Mamba models from pretrained Transformers. Trained on only 8 billion tokens, our distilled models show strong performance and scaling on mathematical reasoning datasets while being much faster at inference for large batches and long sequences. Despite the zero-shot performance hit due to distillation, both pure and hybrid Mamba models can scale their coverage and accuracy performance past their Transformer teacher models under fixed time budgets, opening a new direction for scaling inference compute.
Leveraging the true depth of LLMs
Feb 05, 2025



Large Language Models demonstrate remarkable capabilities at the cost of high compute requirements. While recent research has shown that intermediate layers can be removed or have their order shuffled without impacting performance significantly, these findings have not been employed to reduce the computational cost of inference. We investigate several potential ways to reduce the depth of pre-trained LLMs without significantly affecting performance. Leveraging our insights, we present a novel approach that exploits this decoupling between layers by grouping some of them into pairs that can be evaluated in parallel. This modification of the computational graph -- through better parallelism -- results in an average improvement of around 1.20x on the number of tokens generated per second, without re-training nor fine-tuning, while retaining 95%-99% of the original accuracy. Empirical evaluation demonstrates that this approach significantly improves serving efficiency while maintaining model performance, offering a practical improvement for large-scale LLM deployment.
The Mamba in the Llama: Distilling and Accelerating Hybrid Models
Aug 27, 2024Linear RNN architectures, like Mamba, can be competitive with Transformer models in language modeling while having advantageous deployment characteristics. Given the focus on training large-scale Transformer models, we consider the challenge of converting these pretrained models for deployment. We demonstrate that it is feasible to distill large Transformers into linear RNNs by reusing the linear projection weights from attention layers with academic GPU resources. The resulting hybrid model, which incorporates a quarter of the attention layers, achieves performance comparable to the original Transformer in chat benchmarks and outperforms open-source hybrid Mamba models trained from scratch with trillions of tokens in both chat benchmarks and general benchmarks. Moreover, we introduce a hardware-aware speculative decoding algorithm that accelerates the inference speed of Mamba and hybrid models. Overall we show how, with limited computation resources, we can remove many of the original attention layers and generate from the resulting model more efficiently. Our top-performing model, distilled from Llama3-8B-Instruct, achieves a 29.61 length-controlled win rate on AlpacaEval 2 against GPT-4 and 7.35 on MT-Bench, surpassing the best instruction-tuned linear RNN model.
Understanding and Minimising Outlier Features in Neural Network Training
May 29, 2024



Outlier Features (OF) are neurons whose activation magnitudes significantly exceed the average over a neural network's (NN) width. They are well known to emerge during standard transformer training and have the undesirable effect of hindering quantisation in afflicted models. Despite their practical importance, little is known behind why OFs emerge during training, nor how one can minimise them. Our work focuses on the above questions, first identifying several quantitative metrics, such as the kurtosis over neuron activation norms, to measure OFs. With these metrics, we study how architectural and optimisation choices influence OFs, and provide practical insights to minimise OFs during training. As highlights, we emphasise the importance of controlling signal propagation throughout training, and propose the Outlier Protected transformer block, which removes standard Pre-Norm layers to mitigate OFs, without loss of convergence speed or training stability. Overall, our findings shed new light on our understanding of, our ability to prevent, and the complexity of this important facet in NN training dynamics.
Faster Causal Attention Over Large Sequences Through Sparse Flash Attention
Jun 01, 2023



Transformer-based language models have found many diverse applications requiring them to process sequences of increasing length. For these applications, the causal self-attention -- which is the only component scaling quadratically w.r.t. the sequence length -- becomes a central concern. While many works have proposed schemes to sparsify the attention patterns and reduce the computational overhead of self-attention, those are often limited by implementations concerns and end up imposing a simple and static structure over the attention matrix. Conversely, implementing more dynamic sparse attentions often results in runtimes significantly slower than computing the full attention using the Flash implementation from Dao et al. (2022). We extend FlashAttention to accommodate a large class of attention sparsity patterns that, in particular, encompass key/query dropping and hashing-based attention. This leads to implementations with no computational complexity overhead and a multi-fold runtime speedup on top of FlashAttention. Even with relatively low degrees of sparsity, our method improves visibly upon FlashAttention as the sequence length increases. Without sacrificing perplexity, we increase the training speed of a transformer language model by $2.0\times$ and $3.3\times$ for sequences of respectively $8k$ and $16k$ tokens.
Graph Neural Networks Go Forward-Forward
Feb 10, 2023



We present the Graph Forward-Forward (GFF) algorithm, an extension of the Forward-Forward procedure to graphs, able to handle features distributed over a graph's nodes. This allows training graph neural networks with forward passes only, without backpropagation. Our method is agnostic to the message-passing scheme, and provides a more biologically plausible learning scheme than backpropagation, while also carrying computational advantages. With GFF, graph neural networks are trained greedily layer by layer, using both positive and negative samples. We run experiments on 11 standard graph property prediction tasks, showing how GFF provides an effective alternative to backpropagation for training graph neural networks. This shows in particular that this procedure is remarkably efficient in spite of combining the per-layer training with the locality of the processing in a GNN.
SUPA: A Lightweight Diagnostic Simulator for Machine Learning in Particle Physics
Feb 10, 2022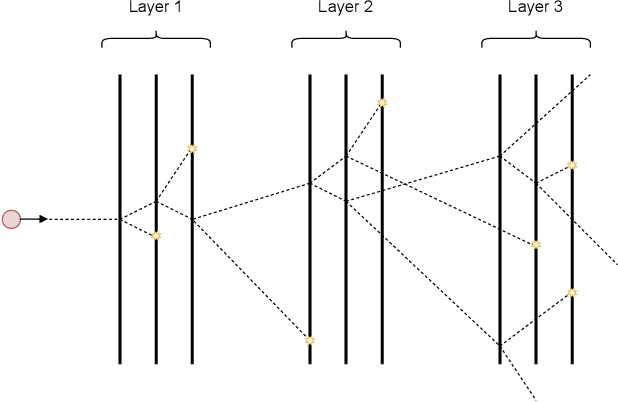
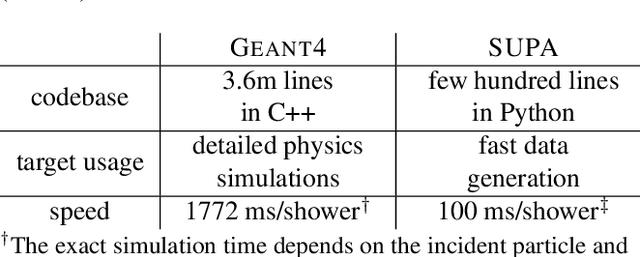
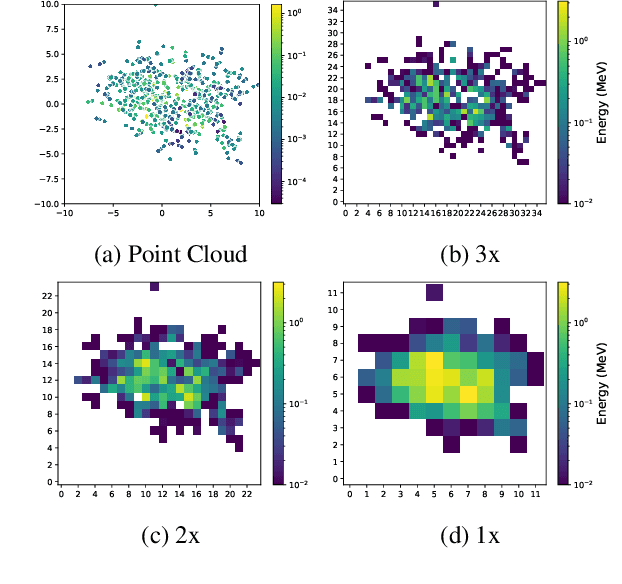
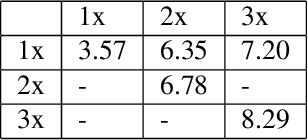
Deep learning methods have gained popularity in high energy physics for fast modeling of particle showers in detectors. Detailed simulation frameworks such as the gold standard Geant4 are computationally intensive, and current deep generative architectures work on discretized, lower resolution versions of the detailed simulation. The development of models that work at higher spatial resolutions is currently hindered by the complexity of the full simulation data, and by the lack of simpler, more interpretable benchmarks. Our contribution is SUPA, the SUrrogate PArticle propagation simulator, an algorithm and software package for generating data by simulating simplified particle propagation, scattering and shower development in matter. The generation is extremely fast and easy to use compared to Geant4, but still exhibits the key characteristics and challenges of the detailed simulation. We support this claim experimentally by showing that performance of generative models on data from our simulator reflects the performance on a dataset generated with Geant4. The proposed simulator generates thousands of particle showers per second on a desktop machine, a speed up of up to 6 orders of magnitudes over Geant4, and stores detailed geometric information about the shower propagation. SUPA provides much greater flexibility for setting initial conditions and defining multiple benchmarks for the development of models. Moreover, interpreting particle showers as point clouds creates a connection to geometric machine learning and provides challenging and fundamentally new datasets for the field. The code for SUPA is available at https://github.com/itsdaniele/SUPA.