 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFederated Learning with Compression: Unified Analysis and Sharp Guarantees
Jul 02, 2020


In federated learning, communication cost is often a critical bottleneck to scale up distributed optimization algorithms to collaboratively learn a model from millions of devices with potentially unreliable or limited communication and heterogeneous data distributions. Two notable trends to deal with the communication overhead of federated algorithms are \emph{gradient compression} and \emph{local computation with periodic communication}. Despite many attempts, characterizing the relationship between these two approaches has proven elusive. We address this by proposing a set of algorithms with periodical compressed (quantized or sparsified) communication and analyze their convergence properties in both homogeneous and heterogeneous local data distributions settings. For the homogeneous setting, our analysis improves existing bounds by providing tighter convergence rates for both \emph{strongly convex} and \emph{non-convex} objective functions. To mitigate data heterogeneity, we introduce a \emph{local gradient tracking} scheme and obtain sharp convergence rates that match the best-known communication complexities without compression for convex, strongly convex, and nonconvex settings. We complement our theoretical results and demonstrate the effectiveness of our proposed methods by several experiments on real-world datasets.
Safe Learning under Uncertain Objectives and Constraints
Jun 23, 2020
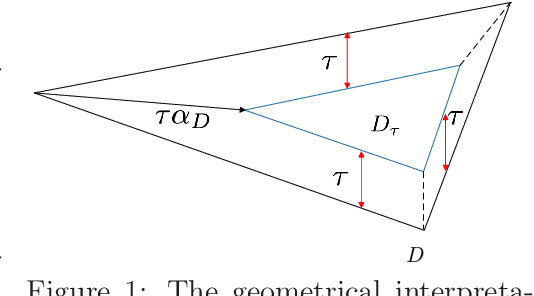
In this paper, we consider non-convex optimization problems under \textit{unknown} yet safety-critical constraints. Such problems naturally arise in a variety of domains including robotics, manufacturing, and medical procedures, where it is infeasible to know or identify all the constraints. Therefore, the parameter space should be explored in a conservative way to ensure that none of the constraints are violated during the optimization process once we start from a safe initialization point. To this end, we develop an algorithm called Reliable Frank-Wolfe (Reliable-FW). Given a general non-convex function and an unknown polytope constraint, Reliable-FW simultaneously learns the landscape of the objective function and the boundary of the safety polytope. More precisely, by assuming that Reliable-FW has access to a (stochastic) gradient oracle of the objective function and a noisy feasibility oracle of the safety polytope, it finds an $\epsilon$-approximate first-order stationary point with the optimal ${\mathcal{O}}({1}/{\epsilon^2})$ gradient oracle complexity (resp. $\tilde{\mathcal{O}}({1}/{\epsilon^3})$ (also optimal) in the stochastic gradient setting), while ensuring the safety of all the iterates. Rather surprisingly, Reliable-FW only makes $\tilde{\mathcal{O}}(({d^2}/{\epsilon^2})\log 1/\delta)$ queries to the noisy feasibility oracle (resp. $\tilde{\mathcal{O}}(({d^2}/{\epsilon^4})\log 1/\delta)$ in the stochastic gradient setting) where $d$ is the dimension and $\delta$ is the reliability parameter, tightening the existing bounds even for safe minimization of convex functions. We further specialize our results to the case that the objective function is convex. A crucial component of our analysis is to introduce and apply a technique called geometric shrinkage in the context of safe optimization.
Hybrid Model for Anomaly Detection on Call Detail Records by Time Series Forecasting
Jun 07, 2020
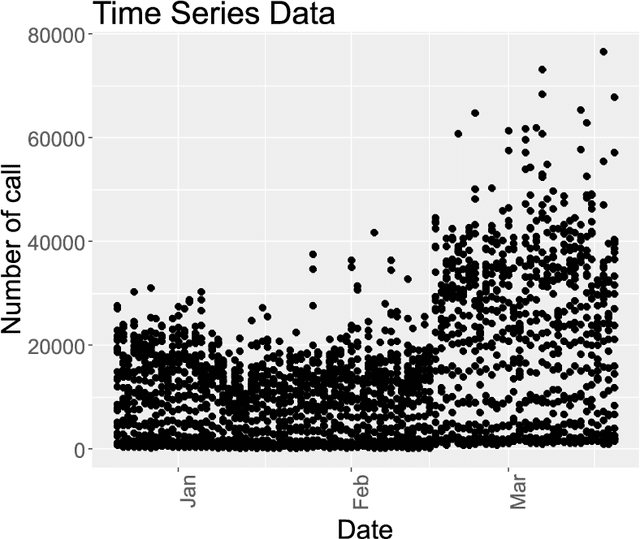
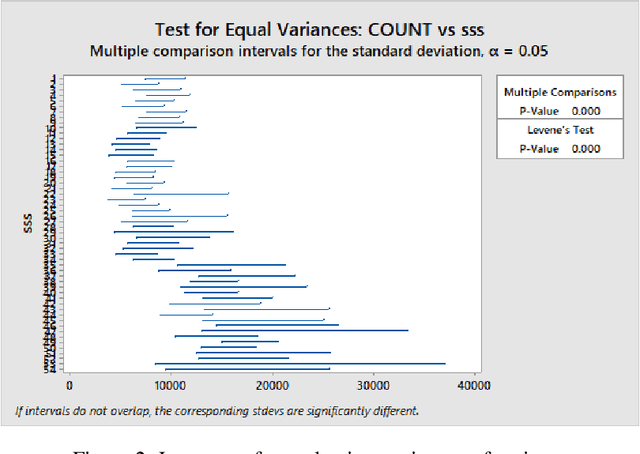
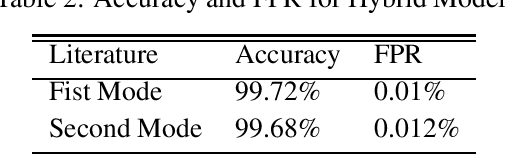
Mobile network operators store an enormous amount of information like log files that describe various events and users' activities. Analysis of these logs might be used in many critical applications such as detecting cyber-attacks, finding behavioral patterns of users, security incident response, network forensics, etc. In a cellular network Call Detail Records (CDR) is one type of such logs containing metadata of calls and usually includes valuable information about contact such as the phone numbers of originating and receiving subscribers, call duration, the area of activity, type of call (SMS or voice call) and a timestamp. With anomaly detection, it is possible to determine abnormal reduction or increment of network traffic in an area or for a particular person. This paper's primary goal is to study subscribers' behavior in a cellular network, mainly predicting the number of calls in a region and detecting anomalies in the network traffic. In this paper, a new hybrid method is proposed based on various anomaly detection methods such as GARCH, K-means, and Neural Network to determine the anomalous data. Moreover, we have discussed the possible causes of such anomalies.
Non-asymptotic Superlinear Convergence of Standard Quasi-Newton Methods
Mar 30, 2020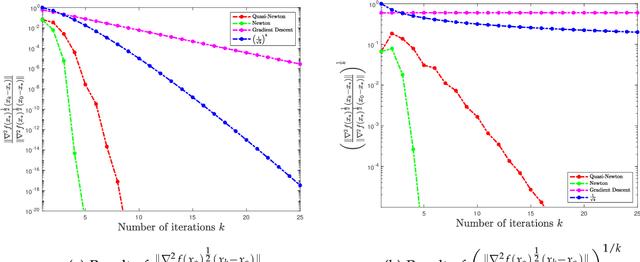
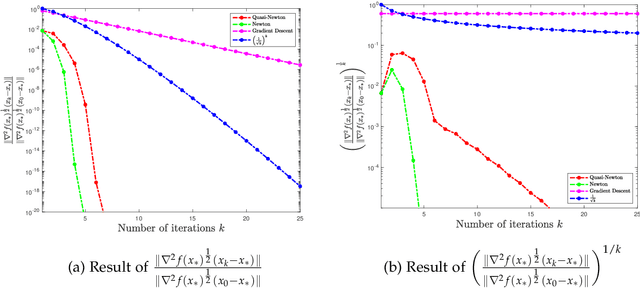
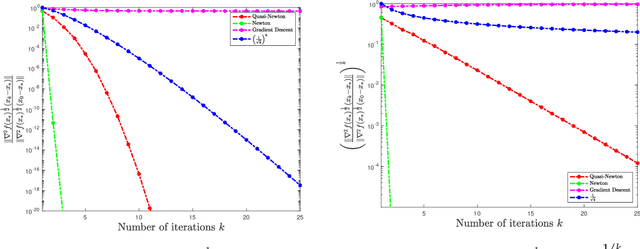
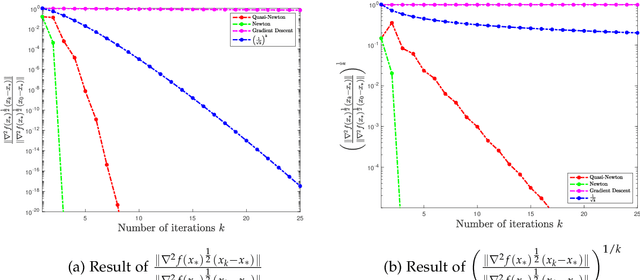
In this paper, we study the non-asymptotic superlinear convergence rate of DFP and BFGS, which are two well-known quasi-Newton methods. The asymptotic superlinear convergence rate of these quasi-Newton methods has been extensively studied, but their explicit finite time local convergence rate has not been established yet. In this paper, we provide a finite time (non-asymptotic) convergence analysis for BFGS and DFP methods under the assumptions that the objective function is strongly convex, its gradient is Lipschitz continuous, and its Hessian is Lipschitz continuous only in the direction of the optimal solution. We show that in a local neighborhood of the optimal solution, the iterates generated by both DFP and BFGS converge to the optimal solution at a superlinear rate of $\mathcal{O}((\frac{1}{ {k}})^{k/2})$, where $k$ is the number of iterations. In particular, for a specific choice of the local neighborhood, both DFP and BFGS converge to the optimal solution at the rate of $(\frac{0.85}{k})^{k/2}$. Our theoretical guarantee is one of the first results that provide a non-asymptotic superlinear convergence rate for DFP and BFGS quasi-Newton methods.
Quantized Push-sum for Gossip and Decentralized Optimization over Directed Graphs
Feb 25, 2020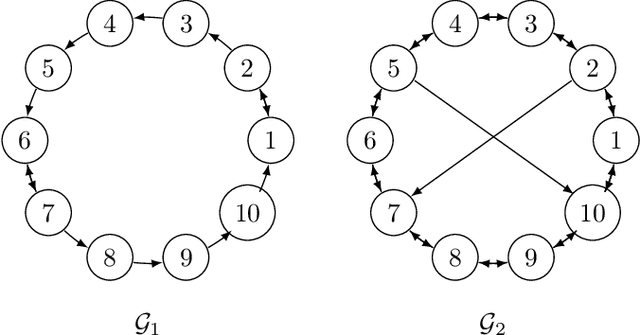
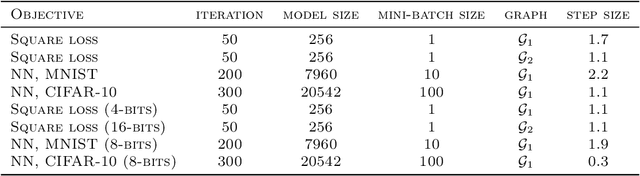
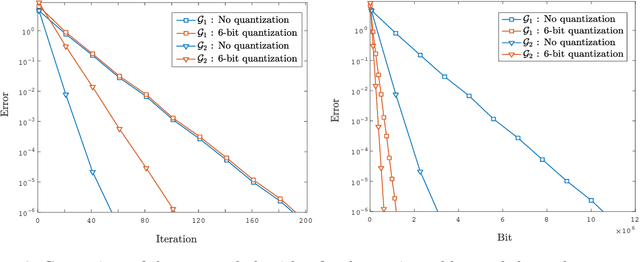
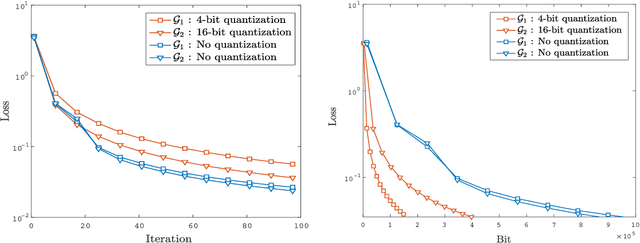
We consider a decentralized stochastic learning problem where data points are distributed among computing nodes communicating over a directed graph. As the model size gets large, decentralized learning faces a major bottleneck that is the heavy communication load due to each node transmitting large messages (model updates) to its neighbors. To tackle this bottleneck, we propose the quantized decentralized stochastic learning algorithm over directed graphs that is based on the push-sum algorithm in decentralized consensus optimization. More importantly, we prove that our algorithm achieves the same convergence rates of the decentralized stochastic learning algorithm with exact-communication for both convex and non-convex losses. A key technical challenge of the work is to prove exact convergence of the proposed decentralized learning algorithm in the presence of quantization noise with unbounded variance over directed graphs. We provide numerical evaluations that corroborate our main theoretical results and illustrate significant speed-up compared to the exact-communication methods.
Personalized Federated Learning: A Meta-Learning Approach
Feb 19, 2020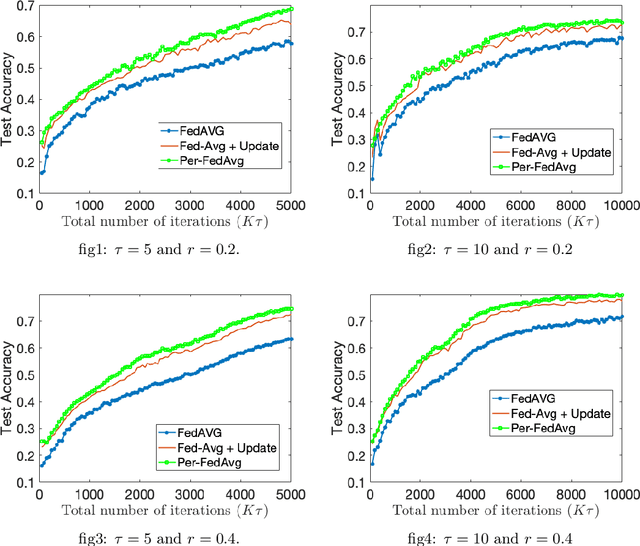
The goal of federated learning is to design algorithms in which several agents communicate with a central node, in a privacy-protecting manner, to minimize the average of their loss functions. In this approach, each node not only shares the required computational budget but also has access to a larger data set, which improves the quality of the resulting model. However, this method only develops a common output for all the agents, and therefore, does not adapt the model to each user data. This is an important missing feature especially given the heterogeneity of the underlying data distribution for various agents. In this paper, we study a personalized variant of the federated learning in which our goal is to find a shared initial model in a distributed manner that can be slightly updated by either a current or a new user by performing one or a few steps of gradient descent with respect to its own loss function. This approach keeps all the benefits of the federated learning architecture while leading to a more personalized model for each user. We show this problem can be studied within the Model-Agnostic Meta-Learning (MAML) framework. Inspired by this connection, we propose a personalized variant of the well-known Federated Averaging algorithm and evaluate its performance in terms of gradient norm for non-convex loss functions. Further, we characterize how this performance is affected by the closeness of underlying distributions of user data, measured in terms of distribution distances such as Total Variation and 1-Wasserstein metric.
Provably Convergent Policy Gradient Methods for Model-Agnostic Meta-Reinforcement Learning
Feb 12, 2020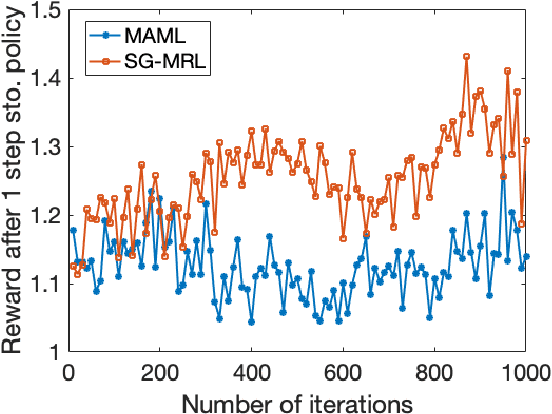
We consider Model-Agnostic Meta-Learning (MAML) methods for Reinforcement Learning (RL) problems where the goal is to find a policy (using data from several tasks represented by Markov Decision Processes (MDPs)) that can be updated by one step of stochastic policy gradient for the realized MDP. In particular, using stochastic gradients in MAML update step is crucial for RL problems since computation of exact gradients requires access to a large number of possible trajectories. For this formulation, we propose a variant of the MAML method, named Stochastic Gradient Meta-Reinforcement Learning (SG-MRL), and study its convergence properties. We derive the iteration and sample complexity of SG-MRL to find an $\epsilon$-first-order stationary point, which, to the best of our knowledge, provides the first convergence guarantee for model-agnostic meta-reinforcement learning algorithms. We further show how our results extend to the case where more than one step of stochastic policy gradient method is used in the update during the test time.
Distribution-Agnostic Model-Agnostic Meta-Learning
Feb 12, 2020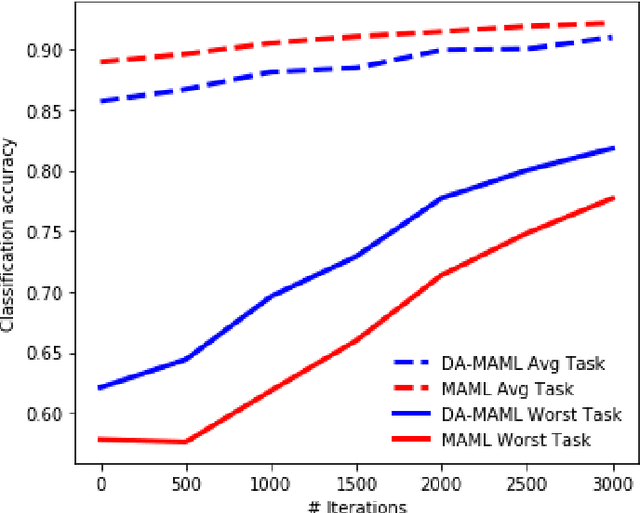
The Model-Agnostic Meta-Learning (MAML) algorithm \citep{finn2017model} has been celebrated for its efficiency and generality, as it has demonstrated success in quickly learning the parameters of an arbitrary learning model. However, MAML implicitly assumes that the tasks come from a particular distribution, and optimizes the expected (or sample average) loss over tasks drawn from this distribution. Here, we amend this limitation of MAML by reformulating the objective function as a min-max problem, where the maximization is over the set of possible distributions over tasks. Our proposed algorithm is the first distribution-agnostic and model-agnostic meta-learning method, and we show that it converges to an $\epsilon$-accurate point at the rate of $\mathcal{O}(1/\epsilon^2)$ in the convex setting and to an $(\epsilon, \delta)$-stationary point at the rate of $\mathcal{O}(\max\{1/\epsilon^5, 1/\delta^5\})$ in nonconvex settings. We also provide numerical experiments that demonstrate the worst-case superiority of our algorithm in comparison to MAML.
A Decentralized Proximal Point-type Method for Saddle Point Problems
Oct 31, 2019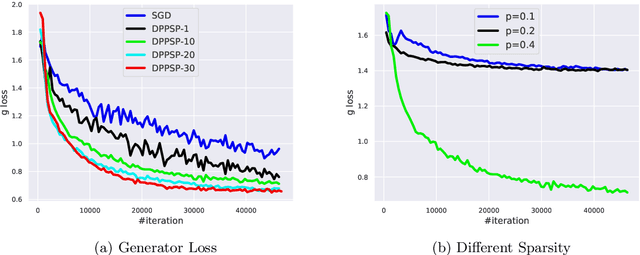

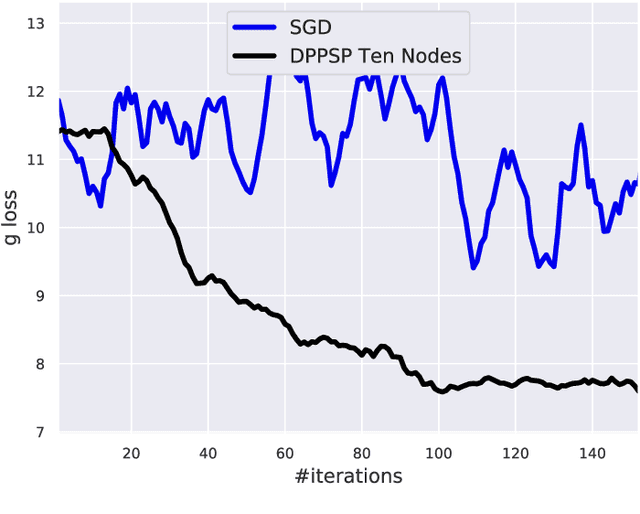
In this paper, we focus on solving a class of constrained non-convex non-concave saddle point problems in a decentralized manner by a group of nodes in a network. Specifically, we assume that each node has access to a summand of a global objective function and nodes are allowed to exchange information only with their neighboring nodes. We propose a decentralized variant of the proximal point method for solving this problem. We show that when the objective function is $\rho$-weakly convex-weakly concave the iterates converge to approximate stationarity with a rate of $\mathcal{O}(1/\sqrt{T})$ where the approximation error depends linearly on $\sqrt{\rho}$. We further show that when the objective function satisfies the Minty VI condition (which generalizes the convex-concave case) we obtain convergence to stationarity with a rate of $\mathcal{O}(1/\sqrt{T})$. To the best of our knowledge, our proposed method is the first decentralized algorithm with theoretical guarantees for solving a non-convex non-concave decentralized saddle point problem. Our numerical results for training a general adversarial network (GAN) in a decentralized manner match our theoretical guarantees.
FedPAQ: A Communication-Efficient Federated Learning Method with Periodic Averaging and Quantization
Oct 12, 2019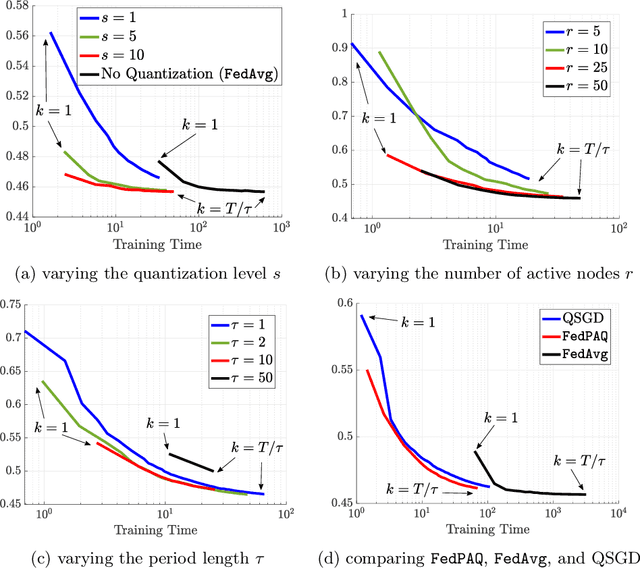
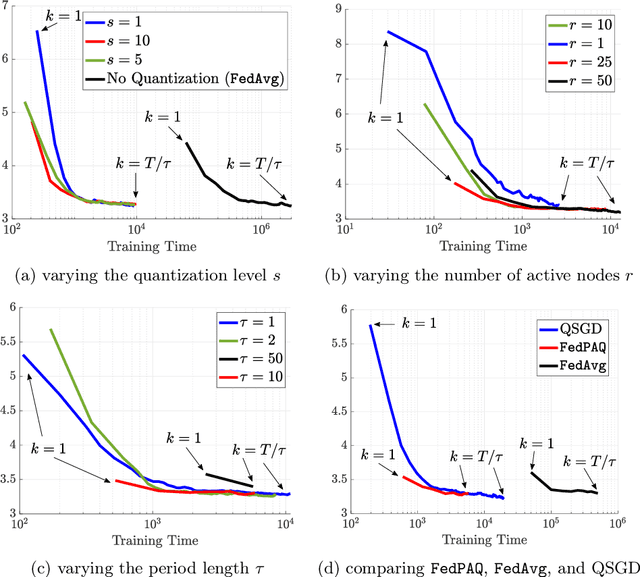
Federated learning is a distributed framework according to which a model is trained over a set of devices, while keeping data localized. This framework faces several systems-oriented challenges which include (i) communication bottleneck since a large number of devices upload their local updates to a parameter server, and (ii) scalability as the federated network consists of millions of devices. Due to these systems challenges as well as issues related to statistical heterogeneity of data and privacy concerns, designing a provably efficient federated learning method is of significant importance yet it remains challenging. In this paper, we present FedPAQ, a communication-efficient Federated Learning method with Periodic Averaging and Quantization. FedPAQ relies on three key features: (1) periodic averaging where models are updated locally at devices and only periodically averaged at the server; (2) partial device participation where only a fraction of devices participate in each round of the training; and (3) quantized message-passing where the edge nodes quantize their updates before uploading to the parameter server. These features address the communications and scalability challenges in federated learning. We also show that FedPAQ achieves near-optimal theoretical guarantees for strongly convex and non-convex loss functions and empirically demonstrate the communication-computation tradeoff provided by our method.