 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Access: Guided LLM Scaffolding for Independent Learning in Undergraduate Statistics
May 31, 2026Large language models (LLMs) are increasingly entering students' learning practices, but their educational value depends on whether they support reasoning or enable task completion without engagement. This study examines guided LLM use in an undergraduate Probability and Statistics course, focusing on the gap between assigned access and actual interaction quality. In a four-week quasi-experimental summer program, students were organized into three balanced conditions: no LLM access, unrestricted LLM access, and guided LLM access. The guided condition used the same LLM platform as the unrestricted condition, but students received explicit training and rules promoting reasoning-focused help-seeking, stepwise hints, verification, and ethical use. All quizzes and the delayed final exam were completed without LLM or external assistance, allowing us to distinguish AI-supported practice performance from independent learning. Results show that guided use was associated with clearer learning-oriented interaction patterns than unrestricted access, especially in prioritizing reasoning over final answers and requesting stepwise support. Guided-LLM students showed stronger no-help quiz performance during the intervention phase, whereas unrestricted access appeared more useful for assisted practice completion than for consistently improving independent performance. Available time measures did not support a simple duration-based explanation, and self-assessment calibration suggested better alignment between perceived and demonstrated understanding in the Guided-LLM condition. Overall, LLM access alone appears to be an incomplete educational intervention. For Artificial Intelligence in Education (AIED), the central design challenge is to scaffold how students use LLMs so that these systems function as partners in reasoning rather than answer-getting tools.
KNIGHT: Knowledge Graph-Driven Multiple-Choice Question Generation with Adaptive Hardness Calibration
Feb 23, 2026With the rise of large language models (LLMs), they have become instrumental in applications such as Retrieval-Augmented Generation (RAG). Yet evaluating these systems remains bottlenecked by the time and cost of building specialized assessment datasets. We introduce KNIGHT, an LLM-based, knowledge-graph-driven framework for generating multiple-choice question (MCQ) datasets from external sources. KNIGHT constructs a topic-specific knowledge graph, a structured and parsimonious summary of entities and relations, that can be reused to generate instructor-controlled difficulty levels, including multi-hop questions, without repeatedly re-feeding the full source text. This knowledge graph acts as a compressed, reusable state, making question generation a cheap read over the graph. We instantiate KNIGHT on Wikipedia/Wikidata while keeping the framework domain- and ontology-agnostic. As a case study, KNIGHT produces six MCQ datasets in History, Biology, and Mathematics. We evaluate quality on five criteria: fluency, unambiguity (single correct answer), topic relevance, option uniqueness, and answerability given the provided sources (as a proxy for hallucination). Results show that KNIGHT enables token- and cost-efficient generation from a reusable graph representation, achieves high quality across these criteria, and yields model rankings aligned with MMLU-style benchmarks, while supporting topic-specific and difficulty-controlled evaluation.
The Sufficiency-Conciseness Trade-off in LLM Self-Explanation from an Information Bottleneck Perspective
Feb 15, 2026Large Language Models increasingly rely on self-explanations, such as chain of thought reasoning, to improve performance on multi step question answering. While these explanations enhance accuracy, they are often verbose and costly to generate, raising the question of how much explanation is truly necessary. In this paper, we examine the trade-off between sufficiency, defined as the ability of an explanation to justify the correct answer, and conciseness, defined as the reduction in explanation length. Building on the information bottleneck principle, we conceptualize explanations as compressed representations that retain only the information essential for producing correct answers.To operationalize this view, we introduce an evaluation pipeline that constrains explanation length and assesses sufficiency using multiple language models on the ARC Challenge dataset. To broaden the scope, we conduct experiments in both English, using the original dataset, and Persian, as a resource-limited language through translation. Our experiments show that more concise explanations often remain sufficient, preserving accuracy while substantially reducing explanation length, whereas excessive compression leads to performance degradation.
A Hybrid TGN-SEAL Model for Dynamic Graph Link Prediction
Feb 15, 2026Predicting links in sparse, continuously evolving networks is a central challenge in network science. Conventional heuristic methods and deep learning models, including Graph Neural Networks (GNNs), are typically designed for static graphs and thus struggle to capture temporal dependencies. Snapshot-based techniques partially address this issue but often encounter data sparsity and class imbalance, particularly in networks with transient interactions such as telecommunication call detail records (CDRs). Temporal Graph Networks (TGNs) model dynamic graphs by updating node embeddings over time; however, their predictive accuracy under sparse conditions remains limited. In this study, we improve the TGN framework by extracting enclosing subgraphs around candidate links, enabling the model to jointly learn structural and temporal information. Experiments on a sparse CDR dataset show that our approach increases average precision by 2.6% over standard TGNs, demonstrating the advantages of integrating local topology for robust link prediction in dynamic networks.
MasalBench: A Benchmark for Contextual and Cross-Cultural Understanding of Persian Proverbs in LLMs
Jan 29, 2026In recent years, multilingual Large Language Models (LLMs) have become an inseparable part of daily life, making it crucial for them to master the rules of conversational language in order to communicate effectively with users. While previous work has evaluated LLMs' understanding of figurative language in high-resource languages, their performance in low-resource languages remains underexplored. In this paper, we introduce MasalBench, a comprehensive benchmark for assessing LLMs' contextual and cross-cultural understanding of Persian proverbs, which are a key component of conversation in this low-resource language. We evaluate eight state-of-the-art LLMs on MasalBench and find that they perform well in identifying Persian proverbs in context, achieving accuracies above 0.90. However, their performance drops considerably when tasked with identifying equivalent English proverbs, with the best model achieving 0.79 accuracy. Our findings highlight the limitations of current LLMs in cultural knowledge and analogical reasoning, and they provide a framework for assessing cross-cultural understanding in other low-resource languages. MasalBench is available at https://github.com/kalhorghazal/MasalBench.
ArtCognition: A Multimodal AI Framework for Affective State Sensing from Visual and Kinematic Drawing Cues
Jan 07, 2026The objective assessment of human affective and psychological states presents a significant challenge, particularly through non-verbal channels. This paper introduces digital drawing as a rich and underexplored modality for affective sensing. We present a novel multimodal framework, named ArtCognition, for the automated analysis of the House-Tree-Person (HTP) test, a widely used psychological instrument. ArtCognition uniquely fuses two distinct data streams: static visual features from the final artwork, captured by computer vision models, and dynamic behavioral kinematic cues derived from the drawing process itself, such as stroke speed, pauses, and smoothness. To bridge the gap between low-level features and high-level psychological interpretation, we employ a Retrieval-Augmented Generation (RAG) architecture. This grounds the analysis in established psychological knowledge, enhancing explainability and reducing the potential for model hallucination. Our results demonstrate that the fusion of visual and behavioral kinematic cues provides a more nuanced assessment than either modality alone. We show significant correlations between the extracted multimodal features and standardized psychological metrics, validating the framework's potential as a scalable tool to support clinicians. This work contributes a new methodology for non-intrusive affective state assessment and opens new avenues for technology-assisted mental healthcare.
A Large-Scale Analysis of Persian Tweets Regarding Covid-19 Vaccination
Feb 09, 2023The Covid-19 pandemic had an enormous effect on our lives, especially on people's interactions. By introducing Covid-19 vaccines, both positive and negative opinions were raised over the subject of taking vaccines or not. In this paper, using data gathered from Twitter, including tweets and user profiles, we offer a comprehensive analysis of public opinion in Iran about the Coronavirus vaccines. For this purpose, we applied a search query technique combined with a topic modeling approach to extract vaccine-related tweets. We utilized transformer-based models to classify the content of the tweets and extract themes revolving around vaccination. We also conducted an emotion analysis to evaluate the public happiness and anger around this topic. Our results demonstrate that Covid-19 vaccination has attracted considerable attention from different angles, such as governmental issues, safety or hesitancy, and side effects. Moreover, Coronavirus-relevant phenomena like public vaccination and the rate of infection deeply impacted public emotional status and users' interactions.
Persian Emotion Detection using ParsBERT and Imbalanced Data Handling Approaches
Nov 17, 2022



Emotion recognition is one of the machine learning applications which can be done using text, speech, or image data gathered from social media spaces. Detecting emotion can help us in different fields, including opinion mining. With the spread of social media, different platforms like Twitter have become data sources, and the language used in these platforms is informal, making the emotion detection task difficult. EmoPars and ArmanEmo are two new human-labeled emotion datasets for the Persian language. These datasets, especially EmoPars, are suffering from inequality between several samples between two classes. In this paper, we evaluate EmoPars and compare them with ArmanEmo. Throughout this analysis, we use data augmentation techniques, data re-sampling, and class-weights with Transformer-based Pretrained Language Models(PLMs) to handle the imbalance problem of these datasets. Moreover, feature selection is used to enhance the models' performance by emphasizing the text's specific features. In addition, we provide a new policy for selecting data from EmoPars, which selects the high-confidence samples; as a result, the model does not see samples that do not have specific emotion during training. Our model reaches a Macro-averaged F1-score of 0.81 and 0.76 on ArmanEmo and EmoPars, respectively, which are new state-of-the-art results in these benchmarks.
* 14 pages, 5 figures, 9 tables
UTNLP at SemEval-2022 Task 6: A Comparative Analysis of Sarcasm Detection using generative-based and mutation-based data augmentation
Apr 18, 2022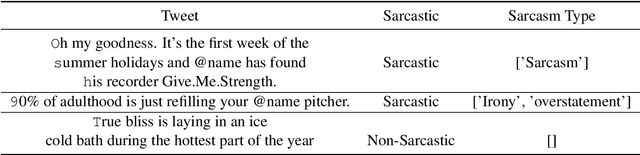
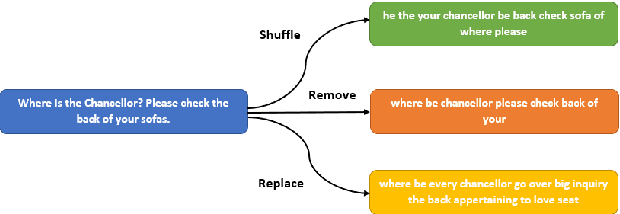
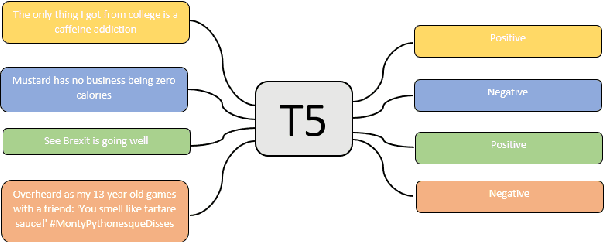
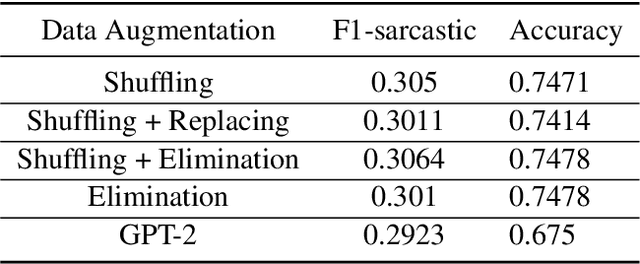
Sarcasm is a term that refers to the use of words to mock, irritate, or amuse someone. It is commonly used on social media. The metaphorical and creative nature of sarcasm presents a significant difficulty for sentiment analysis systems based on affective computing. The methodology and results of our team, UTNLP, in the SemEval-2022 shared task 6 on sarcasm detection are presented in this paper. We put different models, and data augmentation approaches to the test and report on which one works best. The tests begin with traditional machine learning models and progress to transformer-based and attention-based models. We employed data augmentation based on data mutation and data generation. Using RoBERTa and mutation-based data augmentation, our best approach achieved an F1-sarcastic of 0.38 in the competition's evaluation phase. After the competition, we fixed our model's flaws and achieved an F1-sarcastic of 0.414.
UTNLP at SemEval-2021 Task 5: A Comparative Analysis of Toxic Span Detection using Attention-based, Named Entity Recognition, and Ensemble Models
Apr 10, 2021
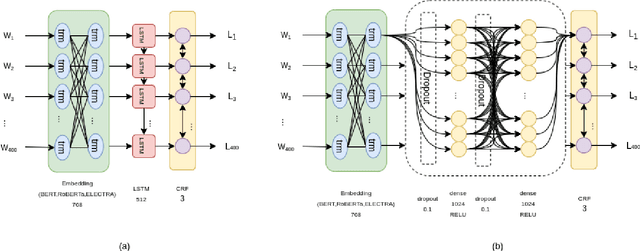
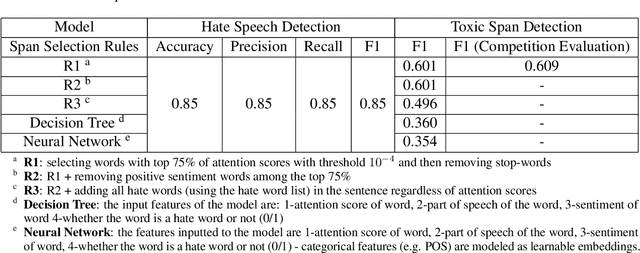
Detecting which parts of a sentence contribute to that sentence's toxicity -- rather than providing a sentence-level verdict of hatefulness -- would increase the interpretability of models and allow human moderators to better understand the outputs of the system. This paper presents our team's, UTNLP, methodology and results in the SemEval-2021 shared task 5 on toxic spans detection. We test multiple models and contextual embeddings and report the best setting out of all. The experiments start with keyword-based models and are followed by attention-based, named entity-based, transformers-based, and ensemble models. Our best approach, an ensemble model, achieves an F1 of 0.684 in the competition's evaluation phase.