 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeObjects as Spatio-Temporal 2.5D points
Dec 07, 2022



Determining accurate bird's eye view (BEV) positions of objects and tracks in a scene is vital for various perception tasks including object interactions mapping, scenario extraction etc., however, the level of supervision required to accomplish that is extremely challenging to procure. We propose a light-weight, weakly supervised method to estimate 3D position of objects by jointly learning to regress the 2D object detections and scene's depth prediction in a single feed-forward pass of a network. Our proposed method extends a center-point based single-shot object detector, and introduces a novel object representation where each object is modeled as a BEV point spatio-temporally, without the need of any 3D or BEV annotations for training and LiDAR data at query time. The approach leverages readily available 2D object supervision along with LiDAR point clouds (used only during training) to jointly train a single network, that learns to predict 2D object detection alongside the whole scene's depth, to spatio-temporally model object tracks as points in BEV. The proposed method is computationally over $\sim$10x efficient compared to recent SOTA approaches while achieving comparable accuracies on KITTI tracking benchmark.
Technology Pipeline for Large Scale Cross-Lingual Dubbing of Lecture Videos into Multiple Indian Languages
Nov 01, 2022

Cross-lingual dubbing of lecture videos requires the transcription of the original audio, correction and removal of disfluencies, domain term discovery, text-to-text translation into the target language, chunking of text using target language rhythm, text-to-speech synthesis followed by isochronous lipsyncing to the original video. This task becomes challenging when the source and target languages belong to different language families, resulting in differences in generated audio duration. This is further compounded by the original speaker's rhythm, especially for extempore speech. This paper describes the challenges in regenerating English lecture videos in Indian languages semi-automatically. A prototype is developed for dubbing lectures into 9 Indian languages. A mean-opinion-score (MOS) is obtained for two languages, Hindi and Tamil, on two different courses. The output video is compared with the original video in terms of MOS (1-5) and lip synchronisation with scores of 4.09 and 3.74, respectively. The human effort also reduces by 75%.
Hydra: A System for Large Multi-Model Deep Learning
Oct 23, 2021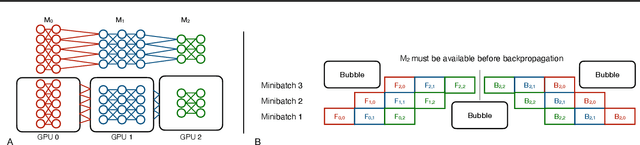

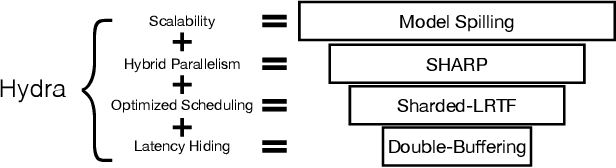
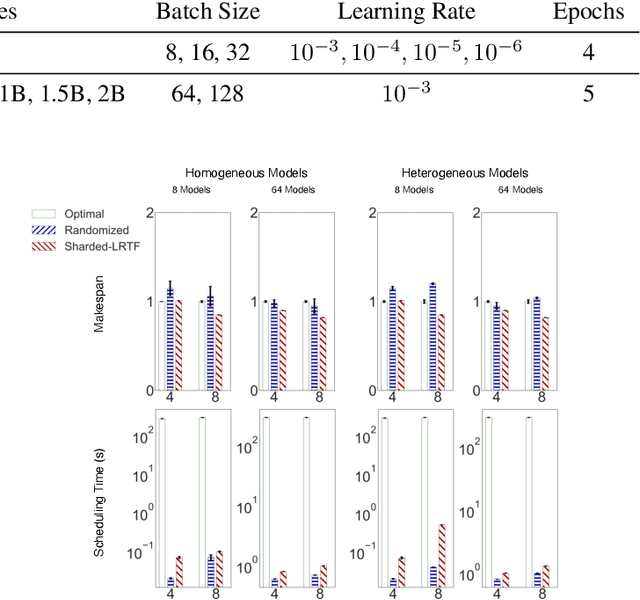
Training deep learning (DL) models that do not fit into the memory of a single GPU is a vexed process, forcing users to procure multiple GPUs to adopt model-parallel execution. Unfortunately, sequential dependencies in neural architectures often block efficient multi-device training, leading to suboptimal performance. We present 'model spilling', a technique aimed at models such as Transformers and CNNs to move groups of layers, or shards, between DRAM and GPU memory, thus enabling arbitrarily large models to be trained even on just one GPU. We then present a set of novel techniques leveraging spilling to raise efficiency for multi-model training workloads such as model selection: a new hybrid of task- and model-parallelism, a new shard scheduling heuristic, and 'double buffering' to hide latency. We prototype our ideas into a system we call HYDRA to support seamless single-model and multi-model training of large DL models. Experiments with real benchmark workloads show that HYDRA is over 7x faster than regular model parallelism and over 50% faster than state-of-the-art industrial tools for pipeline parallelism.
A novel method of fuzzy time series forecasting based on interval index number and membership value using support vector machine
Oct 20, 2020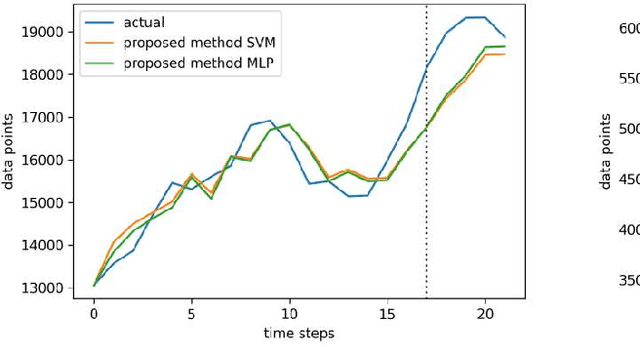

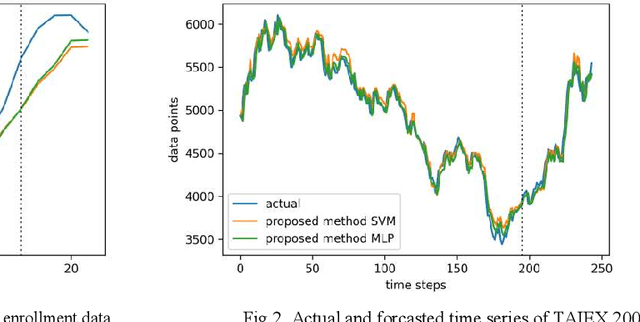
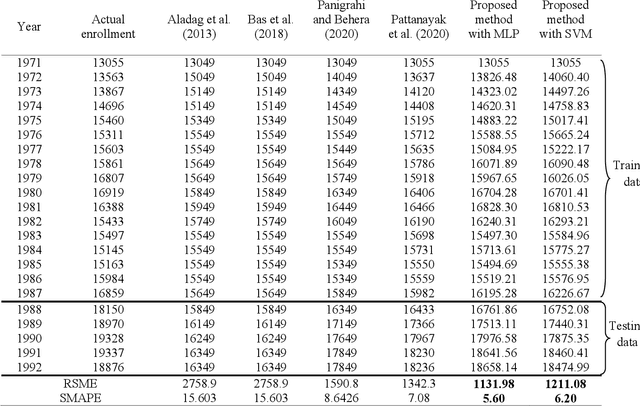
Fuzzy time series forecasting methods are very popular among researchers for predicting future values as they are not based on the strict assumptions of traditional time series forecasting methods. Non-stochastic methods of fuzzy time series forecasting are preferred by the researchers as they provide more significant forecasting results. There are generally, four factors that determine the performance of the forecasting method (1) number of intervals (NOIs) and length of intervals to partition universe of discourse (UOD) (2) fuzzification rules or feature representation of crisp time series (3) method of establishing fuzzy logic rule (FLRs) between input and target values (4) defuzzification rule to get crisp forecasted value. Considering the first two factors to improve the forecasting accuracy, we proposed a novel non-stochastic method fuzzy time series forecasting in which interval index number and membership value are used as input features to predict future value. We suggested a simple rounding-off range and suitable step size method to find the optimal number of intervals (NOIs) and used fuzzy c-means clustering process to divide UOD into intervals of unequal length. We implement support vector machine (SVM) to establish FLRs. To test our proposed method we conduct a simulated study on five widely used real time series and compare the performance with some recently developed models. We also examine the performance of the proposed model by using multi-layer perceptron (MLP) instead of SVM. Two performance measures RSME and SMAPE are used for performance analysis and observed better forecasting accuracy by the proposed model.
A Methodology to Assess the Human Factors Associated with Lunar Teleoperated Assembly Tasks
May 16, 2020
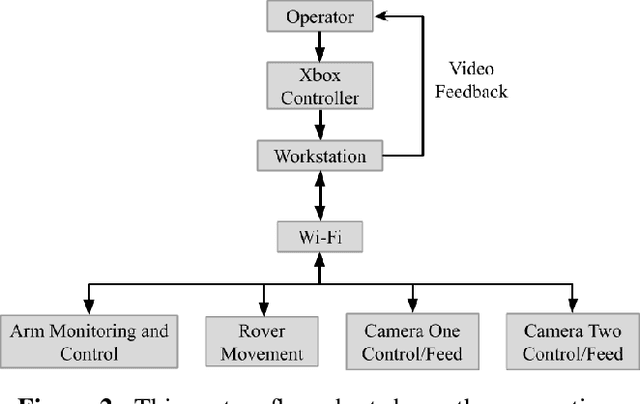
Low-latency telerobotics can enable more intricate surface tasks on extraterrestrial planetary bodies than has ever been attempted. For humanity to create a sustainable lunar presence, well-developed collaboration between humans and robots is necessary to perform complex tasks. This paper presents a methodology to assess the human factors, situational awareness (SA) and cognitive load (CL), associated with teleoperated assembly tasks. Currently, telerobotic assembly on an extraterrestrial body has never been attempted, and a valid methodology to assess the associated human factors has not been developed. The Telerobotics Laboratory at the University of Colorado-Boulder created the Telerobotic Simulation System (TSS) which enables remote operation of a rover and a robotic arm. The TSS was used in a laboratory experiment designed as an analog to a lunar mission. The operator's task was to assemble a radio interferometer. Each participant completed this task under two conditions, remote teleoperation (limited SA) and local operation (optimal SA). The goal of the experiment was to establish a methodology to accurately measure the operator's SA and CL while performing teleoperated assembly tasks. A successful methodology would yield results showing greater SA and lower CL while operating locally. Performance metrics showed greater SA and lower CL in the local environment, supported by a 27% increase in the mean time to completion of the assembly task when operating remotely. Subjective measurements of SA and CL did not align with the performance metrics. Results from this experiment will guide future work attempting to accurately quantify the human factors associated with telerobotic assembly. Once an accurate methodology has been developed, we will be able to measure how new variables affect an operator's SA and CL to optimize the efficiency and effectiveness of telerobotic assembly tasks.
Morphological Segmentation Inside-Out
Nov 12, 2019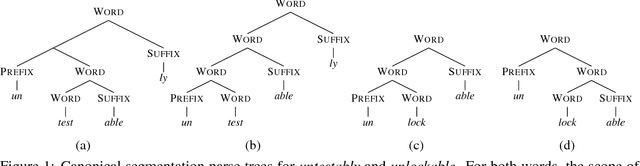
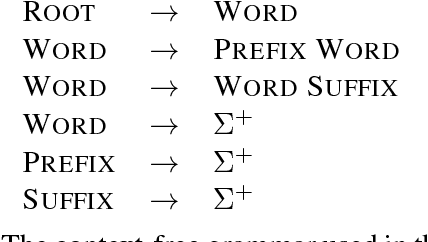

Morphological segmentation has traditionally been modeled with non-hierarchical models, which yield flat segmentations as output. In many cases, however, proper morphological analysis requires hierarchical structure -- especially in the case of derivational morphology. In this work, we introduce a discriminative, joint model of morphological segmentation along with the orthographic changes that occur during word formation. To the best of our knowledge, this is the first attempt to approach discriminative segmentation with a context-free model. Additionally, we release an annotated treebank of 7454 English words with constituency parses, encouraging future research in this area.
Predicting Eating Events in Free Living Individuals -- A Technical Report
Aug 14, 2019
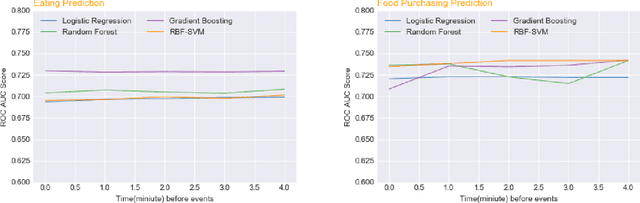
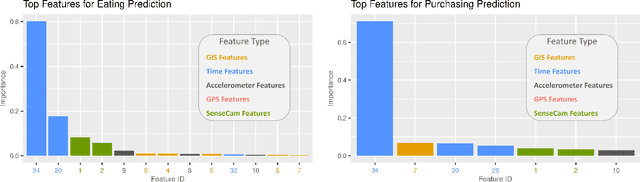
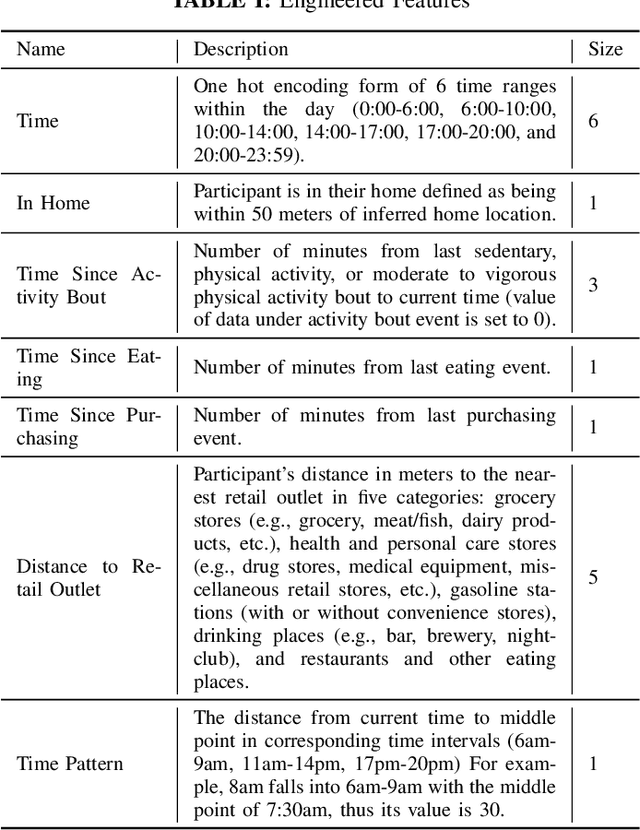
This technical report records the experiments of applying multiple machine learning algorithms for predicting eating and food purchasing behaviors of free-living individuals. Data was collected with accelerometer, global positioning system (GPS), and body-worn cameras called SenseCam over a one week period in 81 individuals from a variety of ages and demographic backgrounds. These data were turned into minute-level features from sensors as well as engineered features that included time (e.g., time since last eating) and environmental context (e.g., distance to nearest grocery store). Algorithms include Logistic Regression, RBF-SVM, Random Forest, and Gradient Boosting. Our results show that the Gradient Boosting model has the highest mean accuracy score (0.7289) for predicting eating events before 0 to 4 minutes. For predicting food purchasing events, the RBF-SVM model (0.7395) outperforms others. For both prediction models, temporal and spatial features were important contributors to predicting eating and food purchasing events.
SysML: The New Frontier of Machine Learning Systems
May 01, 2019Machine learning (ML) techniques are enjoying rapidly increasing adoption. However, designing and implementing the systems that support ML models in real-world deployments remains a significant obstacle, in large part due to the radically different development and deployment profile of modern ML methods, and the range of practical concerns that come with broader adoption. We propose to foster a new systems machine learning research community at the intersection of the traditional systems and ML communities, focused on topics such as hardware systems for ML, software systems for ML, and ML optimized for metrics beyond predictive accuracy. To do this, we describe a new conference, SysML, that explicitly targets research at the intersection of systems and machine learning with a program committee split evenly between experts in systems and ML, and an explicit focus on topics at the intersection of the two.
Belief dynamics extraction
Feb 02, 2019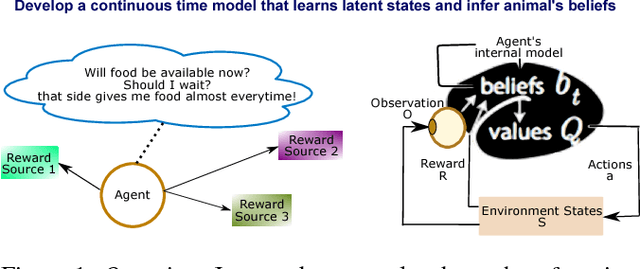
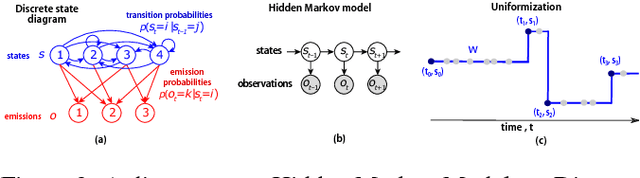
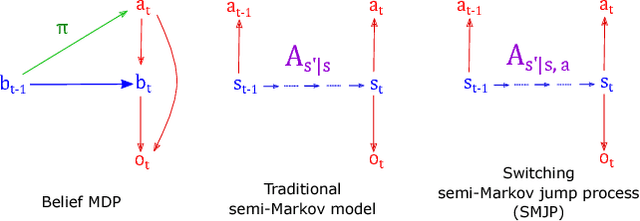

Animal behavior is not driven simply by its current observations, but is strongly influenced by internal states. Estimating the structure of these internal states is crucial for understanding the neural basis of behavior. In principle, internal states can be estimated by inverting behavior models, as in inverse model-based Reinforcement Learning. However, this requires careful parameterization and risks model-mismatch to the animal. Here we take a data-driven approach to infer latent states directly from observations of behavior, using a partially observable switching semi-Markov process. This process has two elements critical for capturing animal behavior: it captures non-exponential distribution of times between observations, and transitions between latent states depend on the animal's actions, features that require more complex non-markovian models to represent. To demonstrate the utility of our approach, we apply it to the observations of a simulated optimal agent performing a foraging task, and find that latent dynamics extracted by the model has correspondences with the belief dynamics of the agent. Finally, we apply our model to identify latent states in the behaviors of monkey performing a foraging task, and find clusters of latent states that identify periods of time consistent with expectant waiting. This data-driven behavioral model will be valuable for inferring latent cognitive states, and thereby for measuring neural representations of those states.
Document Structure Measure for Hypernym discovery
Nov 30, 2018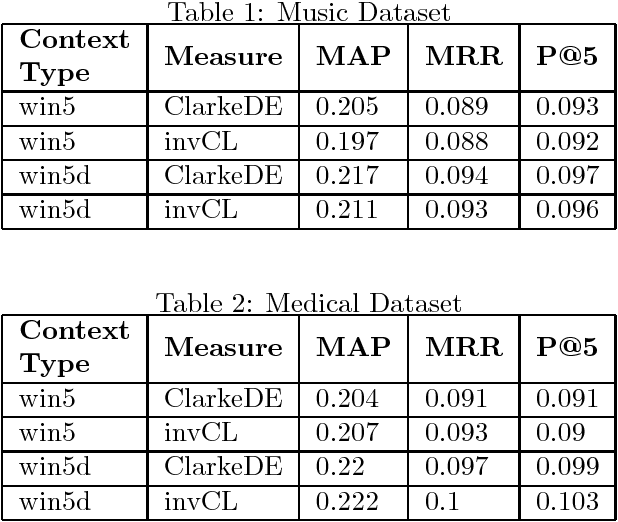
Hypernym discovery is the problem of finding terms that have is-a relationship with a given term. We introduce a new context type, and a relatedness measure to differentiate hypernyms from other types of semantic relationships. Our Document Structure measure is based on hierarchical position of terms in a document, and their presence or otherwise in definition text. This measure quantifies the document structure using multiple attributes, and classes of weighted distance functions.