 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLow-shot learning with large-scale diffusion
Jun 15, 2018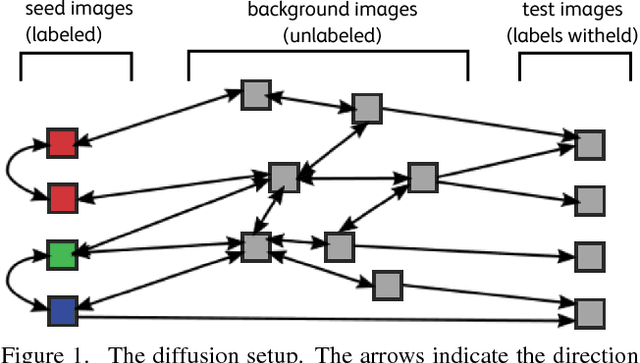
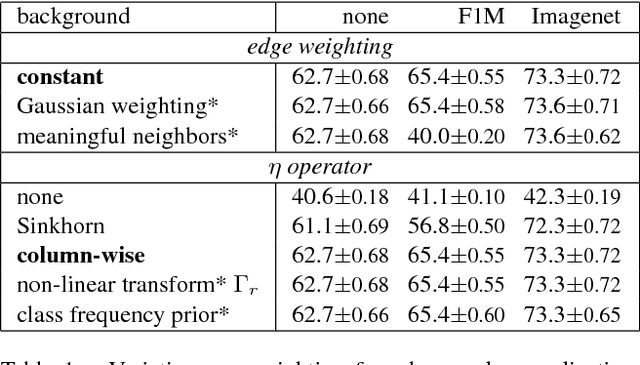
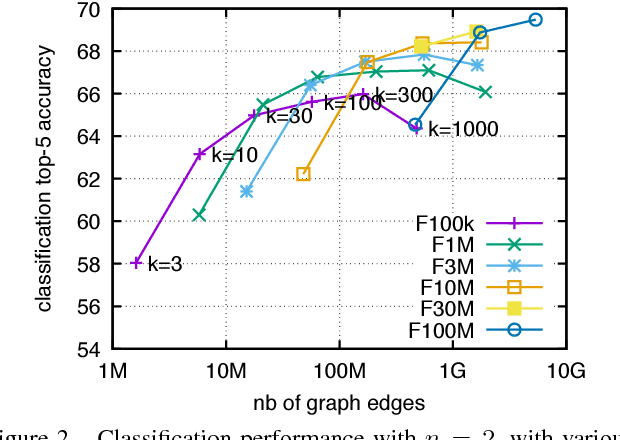

This paper considers the problem of inferring image labels from images when only a few annotated examples are available at training time. This setup is often referred to as low-shot learning, where a standard approach is to re-train the last few layers of a convolutional neural network learned on separate classes for which training examples are abundant. We consider a semi-supervised setting based on a large collection of images to support label propagation. This is possible by leveraging the recent advances on large-scale similarity graph construction. We show that despite its conceptual simplicity, scaling label propagation up to hundred millions of images leads to state of the art accuracy in the low-shot learning regime.
Intrinsic Motivation and Automatic Curricula via Asymmetric Self-Play
Apr 27, 2018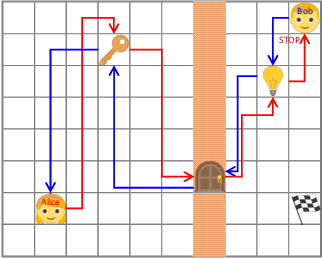
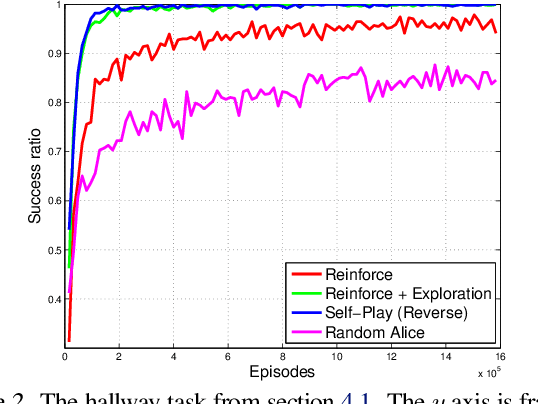
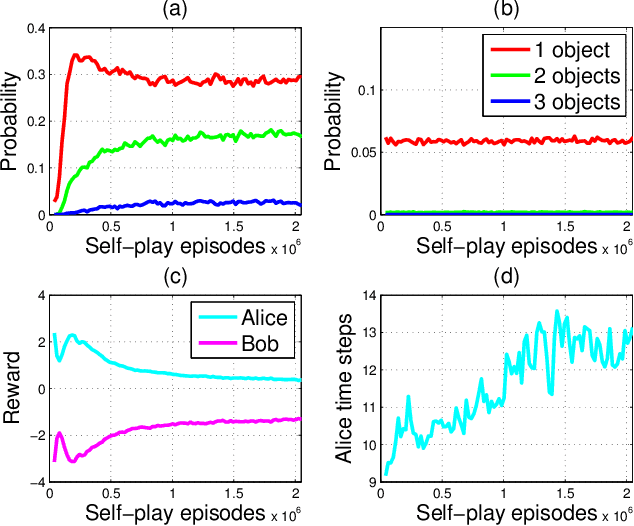
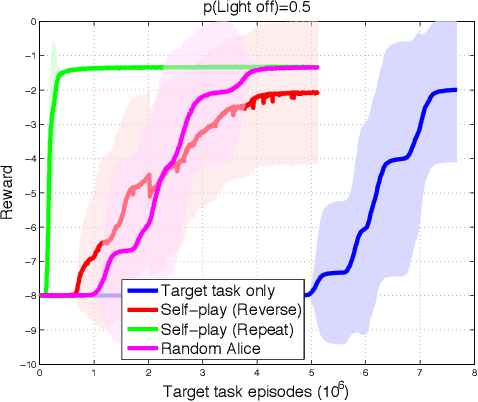
We describe a simple scheme that allows an agent to learn about its environment in an unsupervised manner. Our scheme pits two versions of the same agent, Alice and Bob, against one another. Alice proposes a task for Bob to complete; and then Bob attempts to complete the task. In this work we will focus on two kinds of environments: (nearly) reversible environments and environments that can be reset. Alice will "propose" the task by doing a sequence of actions and then Bob must undo or repeat them, respectively. Via an appropriate reward structure, Alice and Bob automatically generate a curriculum of exploration, enabling unsupervised training of the agent. When Bob is deployed on an RL task within the environment, this unsupervised training reduces the number of supervised episodes needed to learn, and in some cases converges to a higher reward.
Mastering the Dungeon: Grounded Language Learning by Mechanical Turker Descent
Apr 16, 2018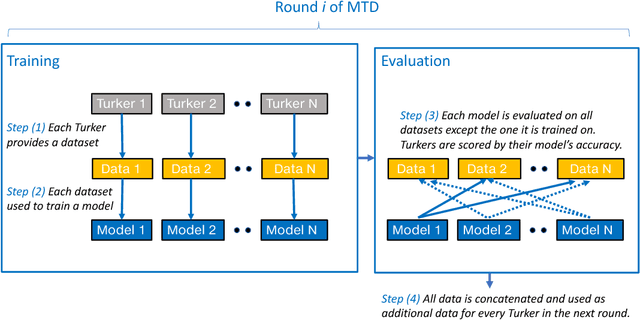
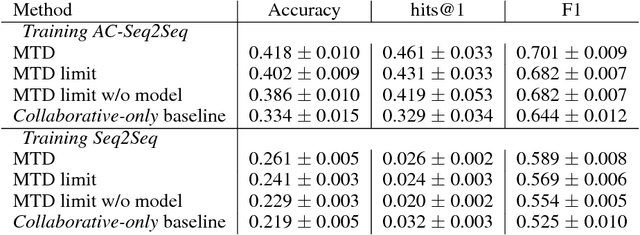

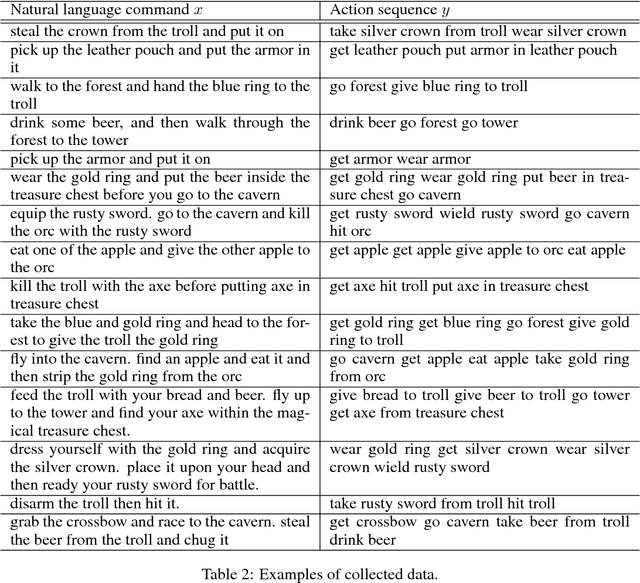
Contrary to most natural language processing research, which makes use of static datasets, humans learn language interactively, grounded in an environment. In this work we propose an interactive learning procedure called Mechanical Turker Descent (MTD) and use it to train agents to execute natural language commands grounded in a fantasy text adventure game. In MTD, Turkers compete to train better agents in the short term, and collaborate by sharing their agents' skills in the long term. This results in a gamified, engaging experience for the Turkers and a better quality teaching signal for the agents compared to static datasets, as the Turkers naturally adapt the training data to the agent's abilities.
Modeling Others using Oneself in Multi-Agent Reinforcement Learning
Mar 23, 2018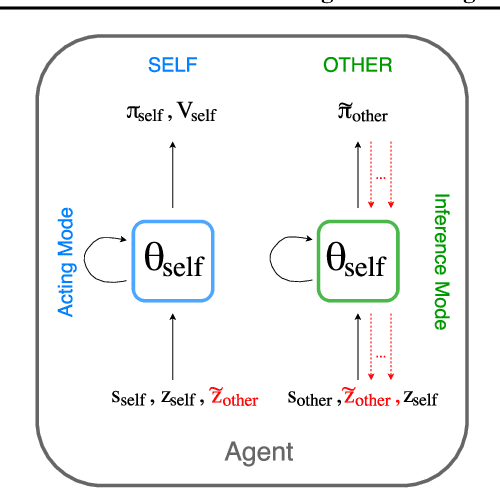
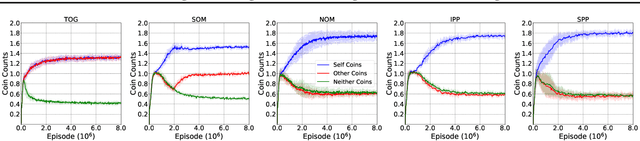
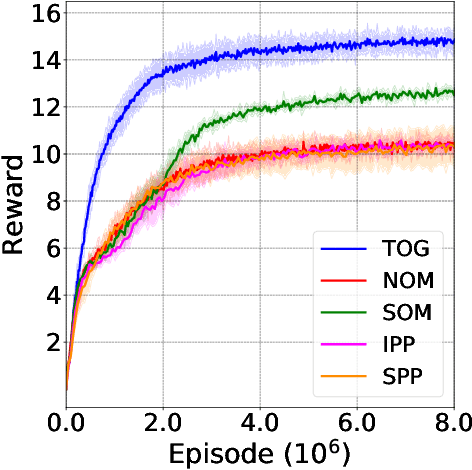
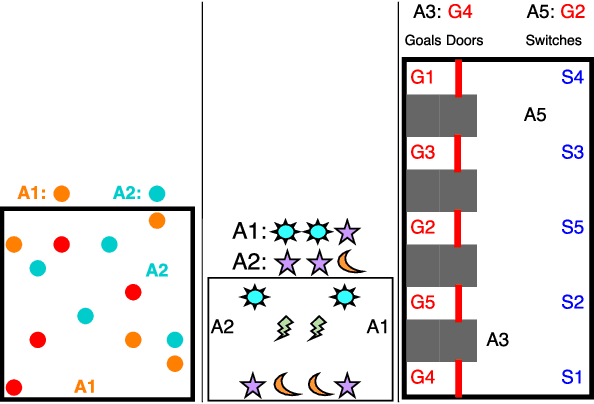
We consider the multi-agent reinforcement learning setting with imperfect information in which each agent is trying to maximize its own utility. The reward function depends on the hidden state (or goal) of both agents, so the agents must infer the other players' hidden goals from their observed behavior in order to solve the tasks. We propose a new approach for learning in these domains: Self Other-Modeling (SOM), in which an agent uses its own policy to predict the other agent's actions and update its belief of their hidden state in an online manner. We evaluate this approach on three different tasks and show that the agents are able to learn better policies using their estimate of the other players' hidden states, in both cooperative and adversarial settings.
Composable Planning with Attributes
Mar 01, 2018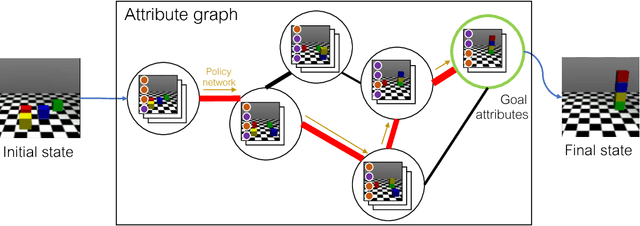
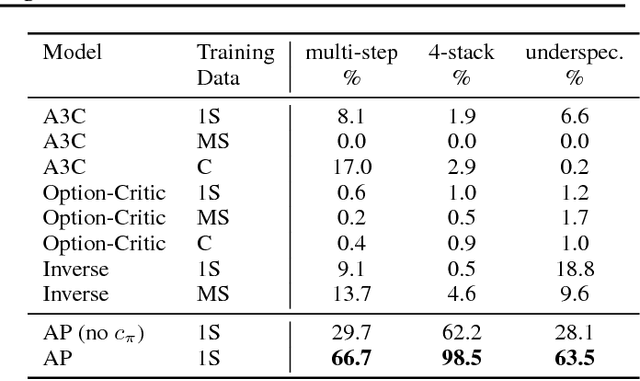
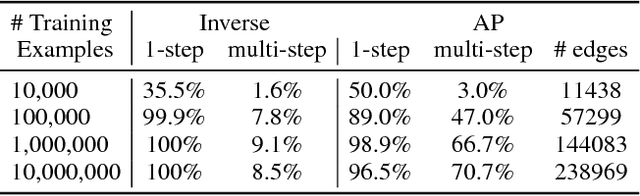
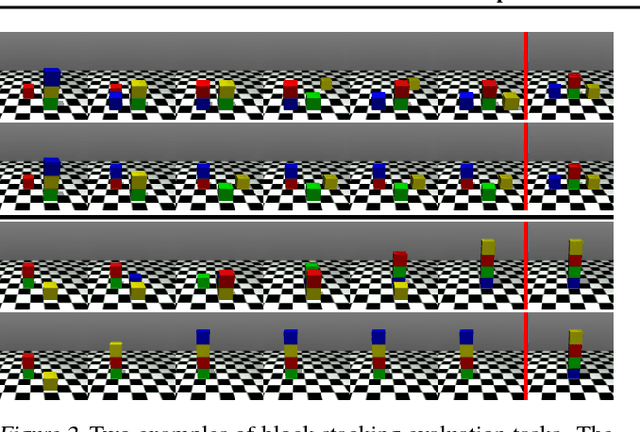
The tasks that an agent will need to solve often are not known during training. However, if the agent knows which properties of the environment are important then, after learning how its actions affect those properties, it may be able to use this knowledge to solve complex tasks without training specifically for them. Towards this end, we consider a setup in which an environment is augmented with a set of user defined attributes that parameterize the features of interest. We propose a method that learns a policy for transitioning between "nearby" sets of attributes, and maintains a graph of possible transitions. Given a task at test time that can be expressed in terms of a target set of attributes, and a current state, our model infers the attributes of the current state and searches over paths through attribute space to get a high level plan, and then uses its low level policy to execute the plan. We show in 3D block stacking, grid-world games, and StarCraft that our model is able to generalize to longer, more complex tasks at test time by composing simpler learned policies.
Optimizing the Latent Space of Generative Networks
Jul 18, 2017
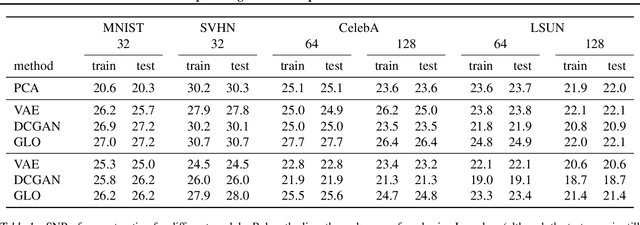


Generative Adversarial Networks (GANs) have been shown to be able to sample impressively realistic images. GAN training consists of a saddle point optimization problem that can be thought of as an adversarial game between a generator which produces the images, and a discriminator, which judges if the images are real. Both the generator and the discriminator are commonly parametrized as deep convolutional neural networks. The goal of this paper is to disentangle the contribution of the optimization procedure and the network parametrization to the success of GANs. To this end we introduce and study Generative Latent Optimization (GLO), a framework to train a generator without the need to learn a discriminator, thus avoiding challenging adversarial optimization problems. We show experimentally that GLO enjoys many of the desirable properties of GANs: learning from large data, synthesizing visually-appealing samples, interpolating meaningfully between samples, and performing linear arithmetic with noise vectors.
Tracking the World State with Recurrent Entity Networks
May 10, 2017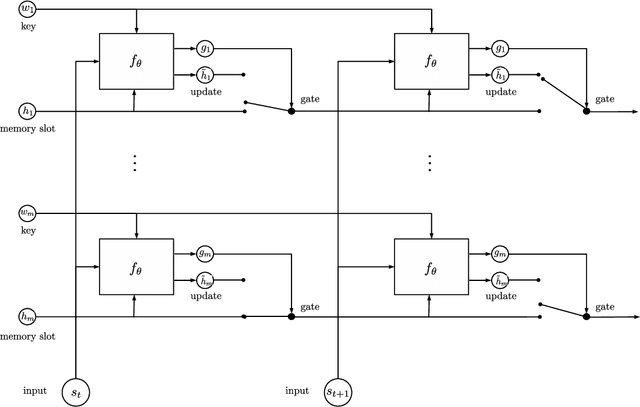

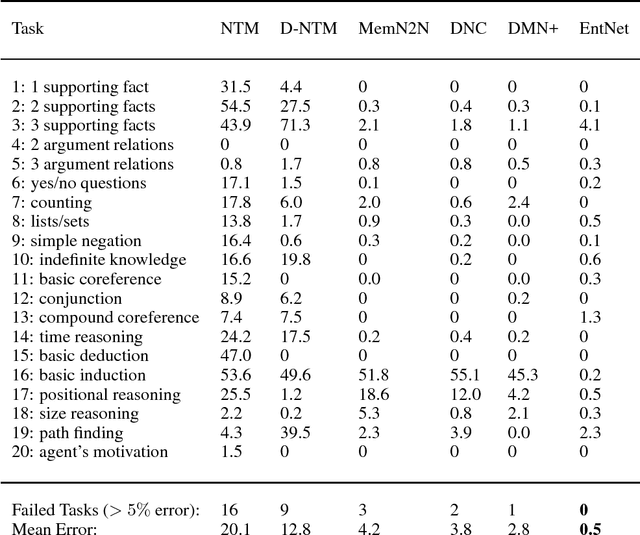
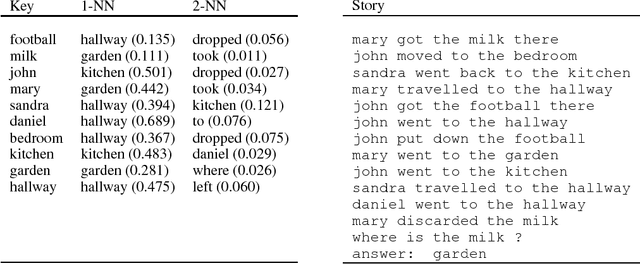
We introduce a new model, the Recurrent Entity Network (EntNet). It is equipped with a dynamic long-term memory which allows it to maintain and update a representation of the state of the world as it receives new data. For language understanding tasks, it can reason on-the-fly as it reads text, not just when it is required to answer a question or respond as is the case for a Memory Network (Sukhbaatar et al., 2015). Like a Neural Turing Machine or Differentiable Neural Computer (Graves et al., 2014; 2016) it maintains a fixed size memory and can learn to perform location and content-based read and write operations. However, unlike those models it has a simple parallel architecture in which several memory locations can be updated simultaneously. The EntNet sets a new state-of-the-art on the bAbI tasks, and is the first method to solve all the tasks in the 10k training examples setting. We also demonstrate that it can solve a reasoning task which requires a large number of supporting facts, which other methods are not able to solve, and can generalize past its training horizon. It can also be practically used on large scale datasets such as Children's Book Test, where it obtains competitive performance, reading the story in a single pass.
Geometric deep learning: going beyond Euclidean data
May 03, 2017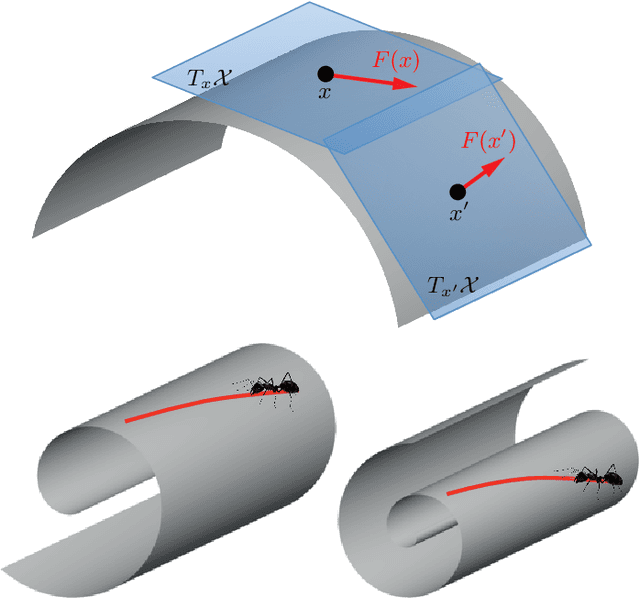
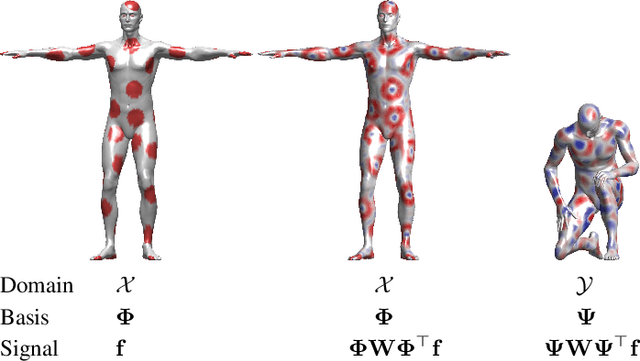
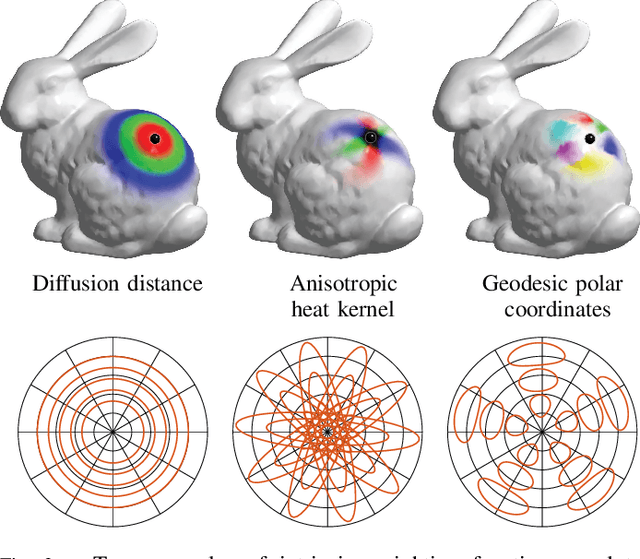
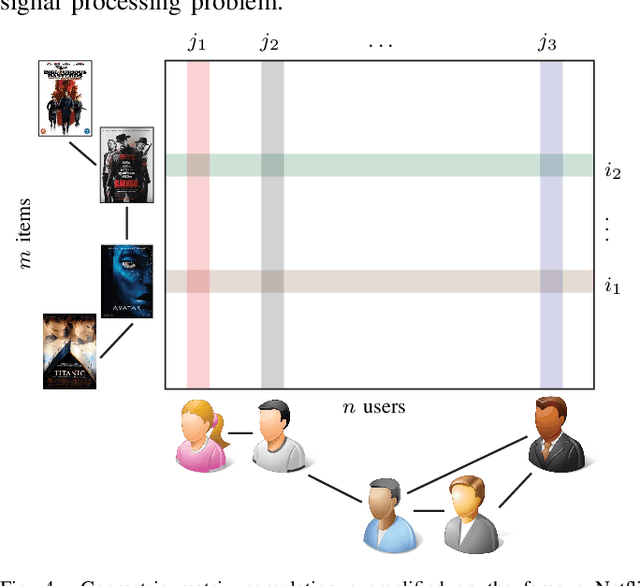
Many scientific fields study data with an underlying structure that is a non-Euclidean space. Some examples include social networks in computational social sciences, sensor networks in communications, functional networks in brain imaging, regulatory networks in genetics, and meshed surfaces in computer graphics. In many applications, such geometric data are large and complex (in the case of social networks, on the scale of billions), and are natural targets for machine learning techniques. In particular, we would like to use deep neural networks, which have recently proven to be powerful tools for a broad range of problems from computer vision, natural language processing, and audio analysis. However, these tools have been most successful on data with an underlying Euclidean or grid-like structure, and in cases where the invariances of these structures are built into networks used to model them. Geometric deep learning is an umbrella term for emerging techniques attempting to generalize (structured) deep neural models to non-Euclidean domains such as graphs and manifolds. The purpose of this paper is to overview different examples of geometric deep learning problems and present available solutions, key difficulties, applications, and future research directions in this nascent field.
Transformation-Based Models of Video Sequences
Apr 24, 2017

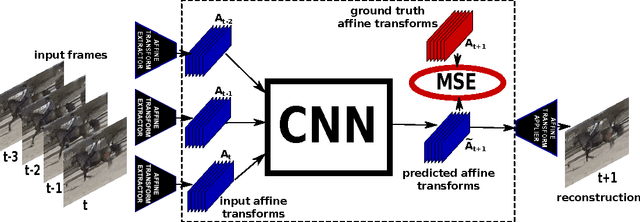
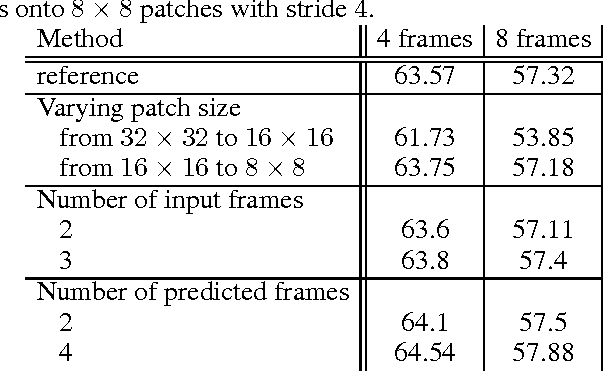
In this work we propose a simple unsupervised approach for next frame prediction in video. Instead of directly predicting the pixels in a frame given past frames, we predict the transformations needed for generating the next frame in a sequence, given the transformations of the past frames. This leads to sharper results, while using a smaller prediction model. In order to enable a fair comparison between different video frame prediction models, we also propose a new evaluation protocol. We use generated frames as input to a classifier trained with ground truth sequences. This criterion guarantees that models scoring high are those producing sequences which preserve discrim- inative features, as opposed to merely penalizing any deviation, plausible or not, from the ground truth. Our proposed approach compares favourably against more sophisticated ones on the UCF-101 data set, while also being more efficient in terms of the number of parameters and computational cost.
Hard Mixtures of Experts for Large Scale Weakly Supervised Vision
Apr 20, 2017
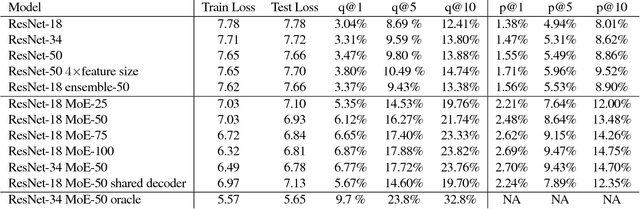

Training convolutional networks (CNN's) that fit on a single GPU with minibatch stochastic gradient descent has become effective in practice. However, there is still no effective method for training large CNN's that do not fit in the memory of a few GPU cards, or for parallelizing CNN training. In this work we show that a simple hard mixture of experts model can be efficiently trained to good effect on large scale hashtag (multilabel) prediction tasks. Mixture of experts models are not new (Jacobs et. al. 1991, Collobert et. al. 2003), but in the past, researchers have had to devise sophisticated methods to deal with data fragmentation. We show empirically that modern weakly supervised data sets are large enough to support naive partitioning schemes where each data point is assigned to a single expert. Because the experts are independent, training them in parallel is easy, and evaluation is cheap for the size of the model. Furthermore, we show that we can use a single decoding layer for all the experts, allowing a unified feature embedding space. We demonstrate that it is feasible (and in fact relatively painless) to train far larger models than could be practically trained with standard CNN architectures, and that the extra capacity can be well used on current datasets.