 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBRUNO: A Deep Recurrent Model for Exchangeable Data
Oct 16, 2018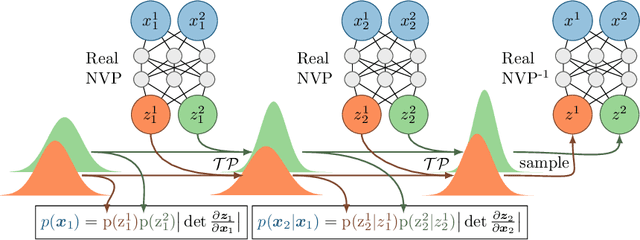
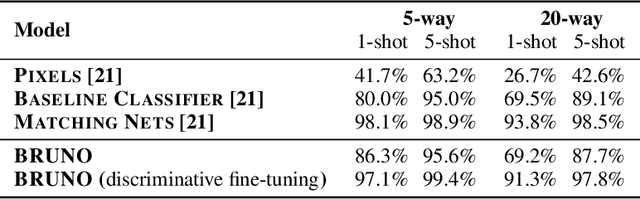

We present a novel model architecture which leverages deep learning tools to perform exact Bayesian inference on sets of high dimensional, complex observations. Our model is provably exchangeable, meaning that the joint distribution over observations is invariant under permutation: this property lies at the heart of Bayesian inference. The model does not require variational approximations to train, and new samples can be generated conditional on previous samples, with cost linear in the size of the conditioning set. The advantages of our architecture are demonstrated on learning tasks that require generalisation from short observed sequences while modelling sequence variability, such as conditional image generation, few-shot learning, and anomaly detection.
Antithetic and Monte Carlo kernel estimators for partial rankings
Jul 25, 2018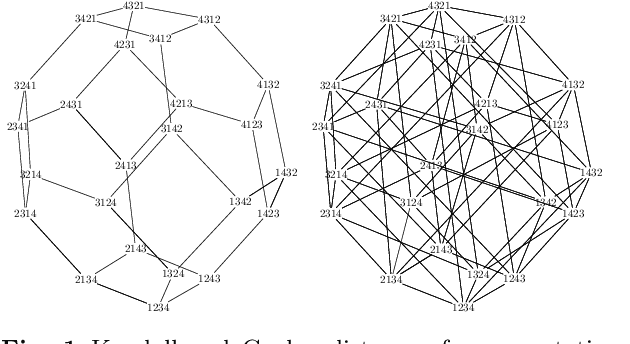
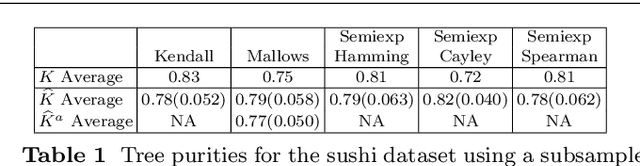
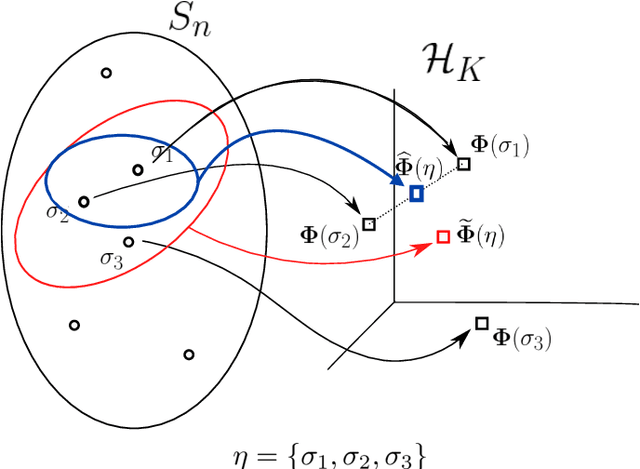
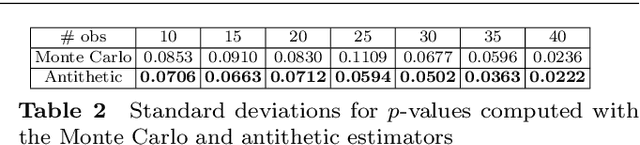
In the modern age, rankings data is ubiquitous and it is useful for a variety of applications such as recommender systems, multi-object tracking and preference learning. However, most rankings data encountered in the real world is incomplete, which prevents the direct application of existing modelling tools for complete rankings. Our contribution is a novel way to extend kernel methods for complete rankings to partial rankings, via consistent Monte Carlo estimators for Gram matrices: matrices of kernel values between pairs of observations. We also present a novel variance reduction scheme based on an antithetic variate construction between permutations to obtain an improved estimator for the Mallows kernel. The corresponding antithetic kernel estimator has lower variance and we demonstrate empirically that it has a better performance in a variety of Machine Learning tasks. Both kernel estimators are based on extending kernel mean embeddings to the embedding of a set of full rankings consistent with an observed partial ranking. They form a computationally tractable alternative to previous approaches for partial rankings data. An overview of the existing kernels and metrics for permutations is also provided.
Kernel Conditional Exponential Family
Apr 08, 2018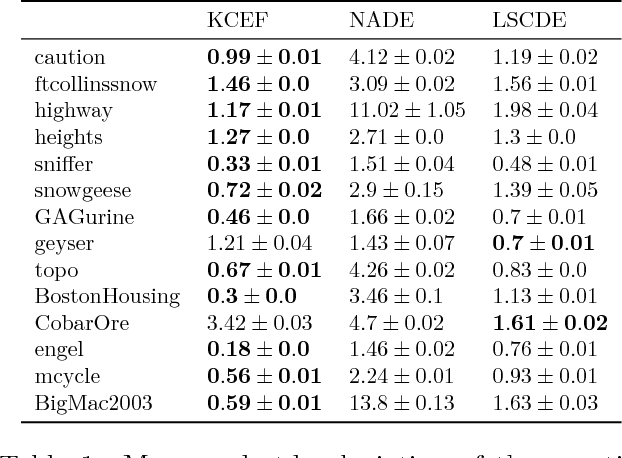
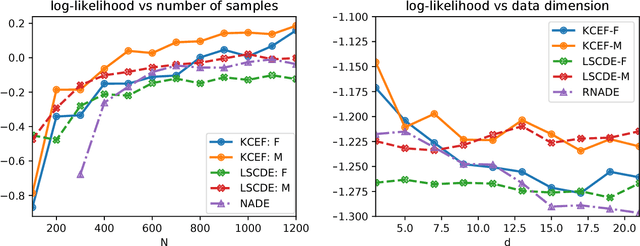
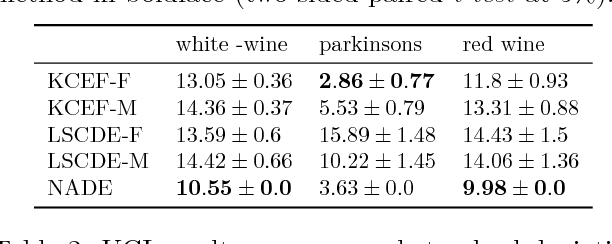
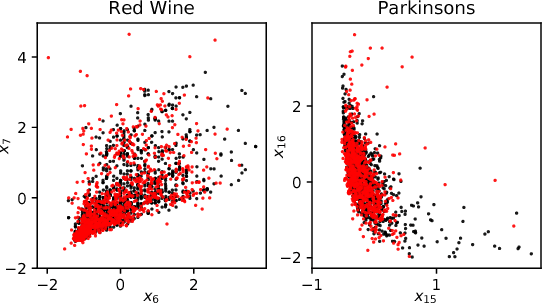
A nonparametric family of conditional distributions is introduced, which generalizes conditional exponential families using functional parameters in a suitable RKHS. An algorithm is provided for learning the generalized natural parameter, and consistency of the estimator is established in the well specified case. In experiments, the new method generally outperforms a competing approach with consistency guarantees, and is competitive with a deep conditional density model on datasets that exhibit abrupt transitions and heteroscedasticity.
Model-based Kernel Sum Rule: Kernel Bayesian Inference with Probabilistic Models
Apr 05, 2018
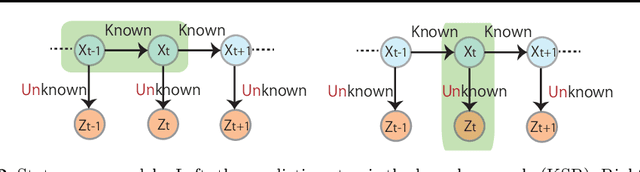
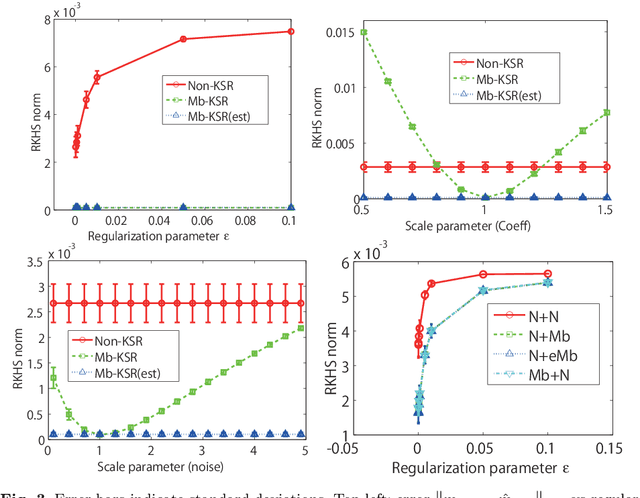
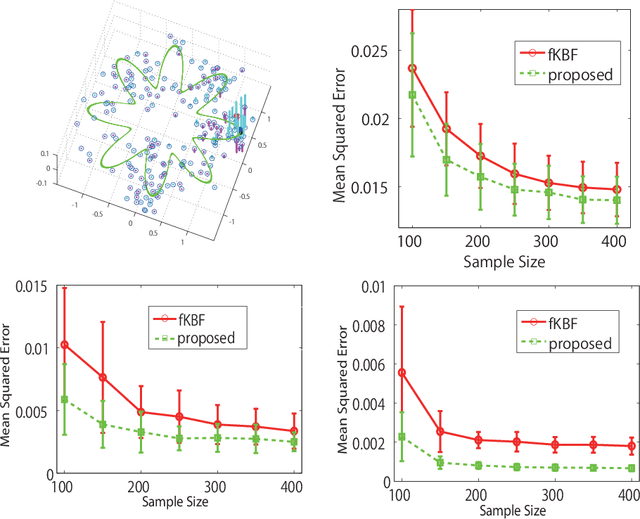
Kernel Bayesian inference is a powerful nonparametric approach to performing Bayesian inference in reproducing kernel Hilbert spaces or feature spaces. In this approach, kernel means are estimated instead of probability distributions, and these estimates can be used for subsequent probabilistic operations (as for inference in graphical models) or in computing the expectations of smooth functions, for instance. Various algorithms for kernel Bayesian inference have been obtained by combining basic rules such as the kernel sum rule (KSR), kernel chain rule, kernel product rule and kernel Bayes' rule. However, the current framework only deals with fully nonparametric inference (i.e., all conditional relations are learned nonparametrically), and it does not allow for flexible combinations of nonparametric and parametric inference, which are practically important. Our contribution is in providing a novel technique to realize such combinations. We introduce a new KSR referred to as the model-based KSR (Mb-KSR), which employs the sum rule in feature spaces under a parametric setting. Incorporating the Mb-KSR into existing kernel Bayesian framework provides a richer framework for hybrid (nonparametric and parametric) kernel Bayesian inference. As a practical application, we propose a novel filtering algorithm for state space models based on the Mb-KSR, which combines the nonparametric learning of an observation process using kernel mean embedding and the additive Gaussian noise model for a state transition process. While we focus on additive Gaussian noise models in this study, the idea can be extended to other noise models, such as the Cauchy and alpha-stable noise models.
Demystifying MMD GANs
Mar 21, 2018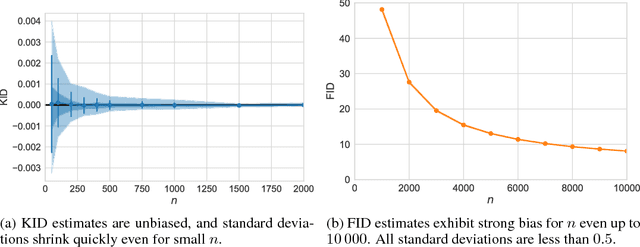
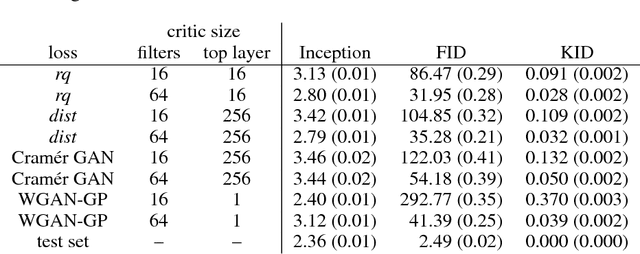
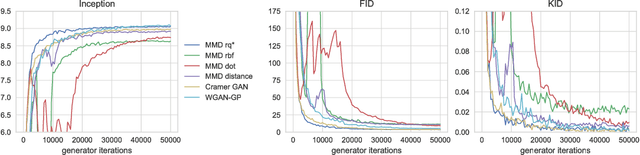

We investigate the training and performance of generative adversarial networks using the Maximum Mean Discrepancy (MMD) as critic, termed MMD GANs. As our main theoretical contribution, we clarify the situation with bias in GAN loss functions raised by recent work: we show that gradient estimators used in the optimization process for both MMD GANs and Wasserstein GANs are unbiased, but learning a discriminator based on samples leads to biased gradients for the generator parameters. We also discuss the issue of kernel choice for the MMD critic, and characterize the kernel corresponding to the energy distance used for the Cramer GAN critic. Being an integral probability metric, the MMD benefits from training strategies recently developed for Wasserstein GANs. In experiments, the MMD GAN is able to employ a smaller critic network than the Wasserstein GAN, resulting in a simpler and faster-training algorithm with matching performance. We also propose an improved measure of GAN convergence, the Kernel Inception Distance, and show how to use it to dynamically adapt learning rates during GAN training.
Efficient and principled score estimation with Nyström kernel exponential families
Mar 13, 2018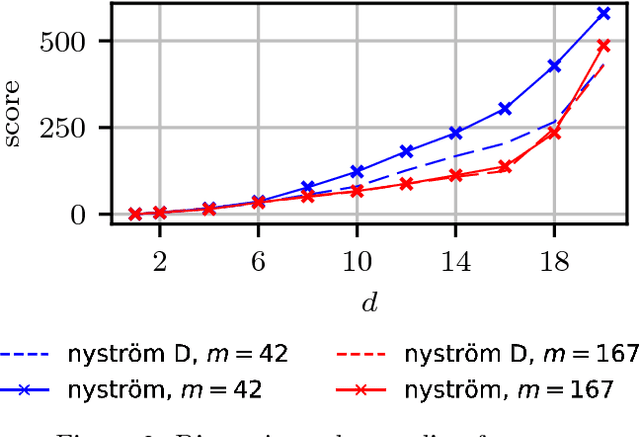
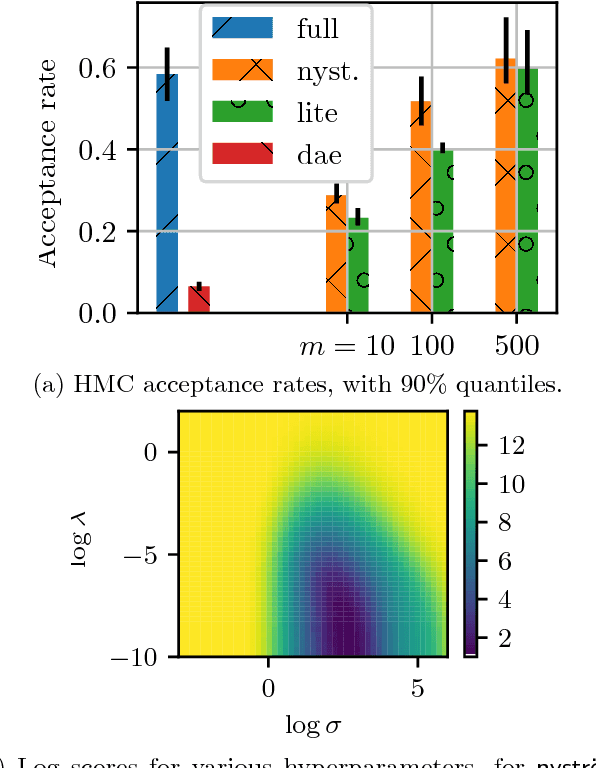
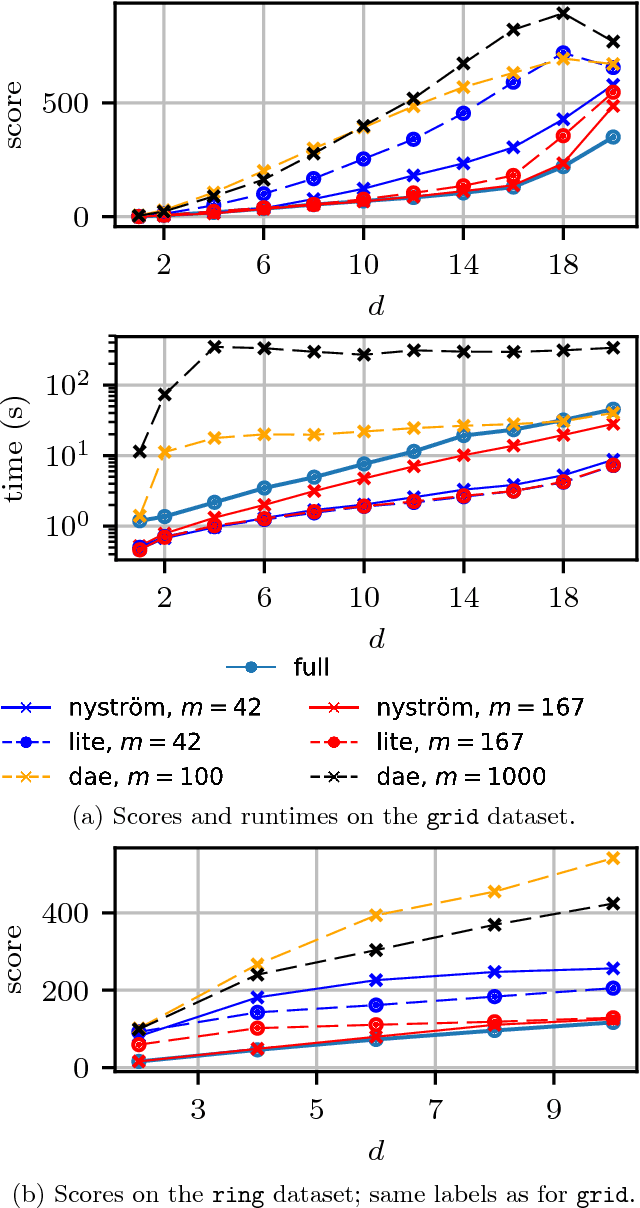
We propose a fast method with statistical guarantees for learning an exponential family density model where the natural parameter is in a reproducing kernel Hilbert space, and may be infinite-dimensional. The model is learned by fitting the derivative of the log density, the score, thus avoiding the need to compute a normalization constant. Our approach improves the computational efficiency of an earlier solution by using a low-rank, Nystr\"om-like solution. The new solution retains the consistency and convergence rates of the full-rank solution (exactly in Fisher distance, and nearly in other distances), with guarantees on the degree of cost and storage reduction. We evaluate the method in experiments on density estimation and in the construction of an adaptive Hamiltonian Monte Carlo sampler. Compared to an existing score learning approach using a denoising autoencoder, our estimator is empirically more data-efficient when estimating the score, runs faster, and has fewer parameters (which can be tuned in a principled and interpretable way), in addition to providing statistical guarantees.
A Linear-Time Kernel Goodness-of-Fit Test
Oct 24, 2017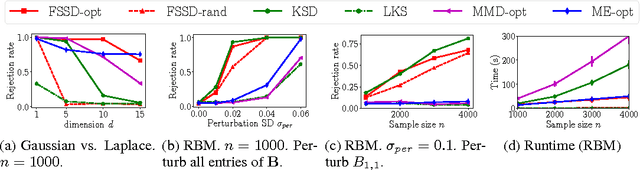
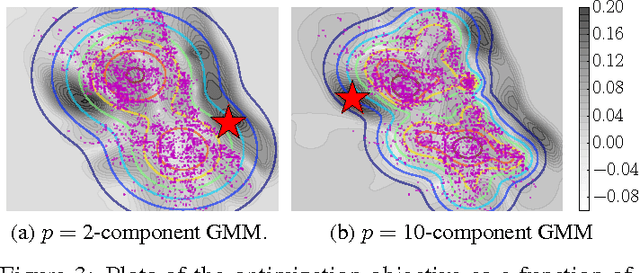
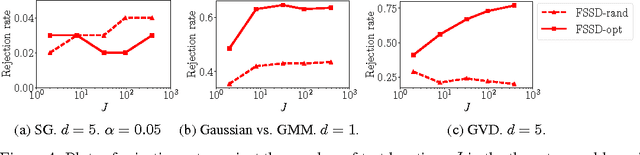
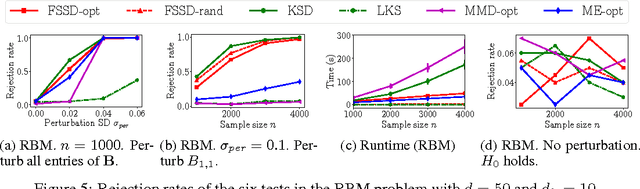
We propose a novel adaptive test of goodness-of-fit, with computational cost linear in the number of samples. We learn the test features that best indicate the differences between observed samples and a reference model, by minimizing the false negative rate. These features are constructed via Stein's method, meaning that it is not necessary to compute the normalising constant of the model. We analyse the asymptotic Bahadur efficiency of the new test, and prove that under a mean-shift alternative, our test always has greater relative efficiency than a previous linear-time kernel test, regardless of the choice of parameters for that test. In experiments, the performance of our method exceeds that of the earlier linear-time test, and matches or exceeds the power of a quadratic-time kernel test. In high dimensions and where model structure may be exploited, our goodness of fit test performs far better than a quadratic-time two-sample test based on the Maximum Mean Discrepancy, with samples drawn from the model.
Density Estimation in Infinite Dimensional Exponential Families
May 26, 2017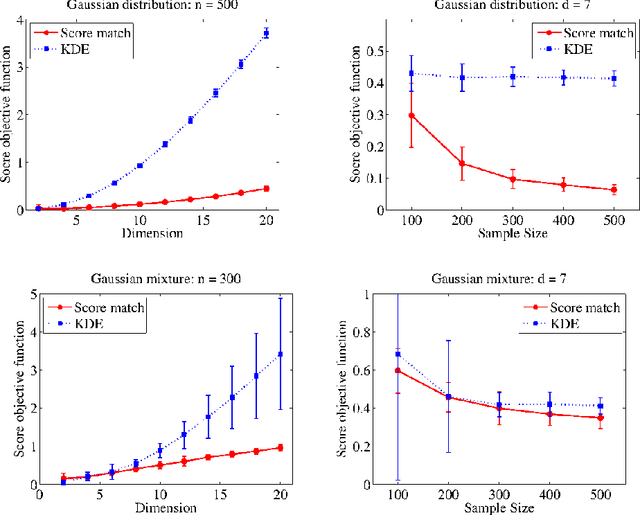
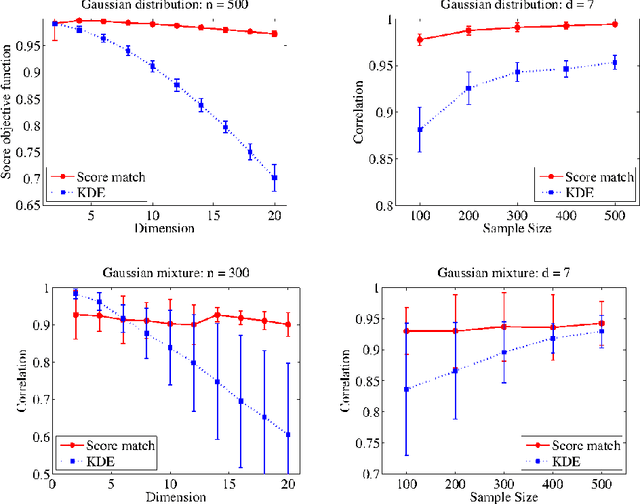
In this paper, we consider an infinite dimensional exponential family, $\mathcal{P}$ of probability densities, which are parametrized by functions in a reproducing kernel Hilbert space, $H$ and show it to be quite rich in the sense that a broad class of densities on $\mathbb{R}^d$ can be approximated arbitrarily well in Kullback-Leibler (KL) divergence by elements in $\mathcal{P}$. The main goal of the paper is to estimate an unknown density, $p_0$ through an element in $\mathcal{P}$. Standard techniques like maximum likelihood estimation (MLE) or pseudo MLE (based on the method of sieves), which are based on minimizing the KL divergence between $p_0$ and $\mathcal{P}$, do not yield practically useful estimators because of their inability to efficiently handle the log-partition function. Instead, we propose an estimator, $\hat{p}_n$ based on minimizing the \emph{Fisher divergence}, $J(p_0\Vert p)$ between $p_0$ and $p\in \mathcal{P}$, which involves solving a simple finite-dimensional linear system. When $p_0\in\mathcal{P}$, we show that the proposed estimator is consistent, and provide a convergence rate of $n^{-\min\left\{\frac{2}{3},\frac{2\beta+1}{2\beta+2}\right\}}$ in Fisher divergence under the smoothness assumption that $\log p_0\in\mathcal{R}(C^\beta)$ for some $\beta\ge 0$, where $C$ is a certain Hilbert-Schmidt operator on $H$ and $\mathcal{R}(C^\beta)$ denotes the image of $C^\beta$. We also investigate the misspecified case of $p_0\notin\mathcal{P}$ and show that $J(p_0\Vert\hat{p}_n)\rightarrow \inf_{p\in\mathcal{P}}J(p_0\Vert p)$ as $n\rightarrow\infty$, and provide a rate for this convergence under a similar smoothness condition as above. Through numerical simulations we demonstrate that the proposed estimator outperforms the non-parametric kernel density estimator, and that the advantage with the proposed estimator grows as $d$ increases.
Generative Models and Model Criticism via Optimized Maximum Mean Discrepancy
Feb 10, 2017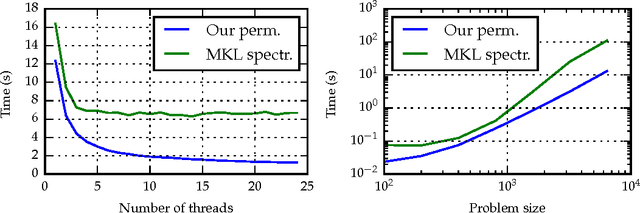
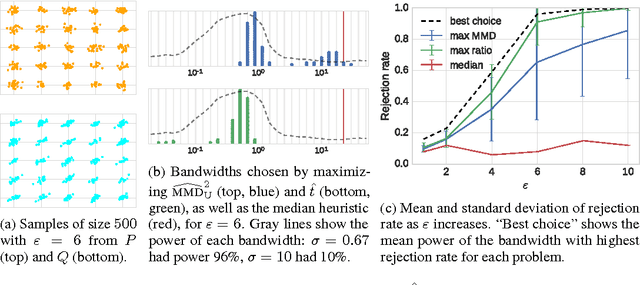
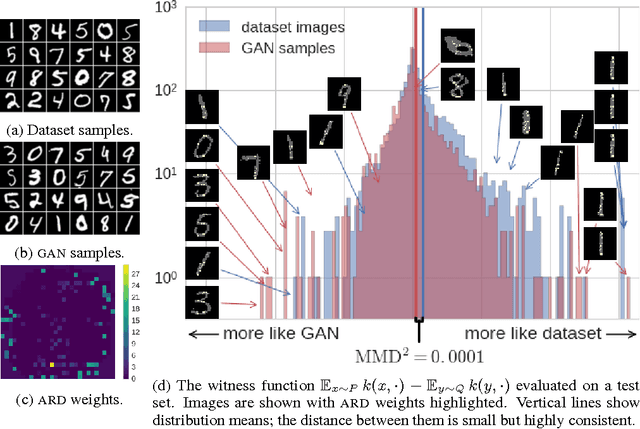

We propose a method to optimize the representation and distinguishability of samples from two probability distributions, by maximizing the estimated power of a statistical test based on the maximum mean discrepancy (MMD). This optimized MMD is applied to the setting of unsupervised learning by generative adversarial networks (GAN), in which a model attempts to generate realistic samples, and a discriminator attempts to tell these apart from data samples. In this context, the MMD may be used in two roles: first, as a discriminator, either directly on the samples, or on features of the samples. Second, the MMD can be used to evaluate the performance of a generative model, by testing the model's samples against a reference data set. In the latter role, the optimized MMD is particularly helpful, as it gives an interpretable indication of how the model and data distributions differ, even in cases where individual model samples are not easily distinguished either by eye or by classifier.
Fast Non-Parametric Tests of Relative Dependency and Similarity
Nov 17, 2016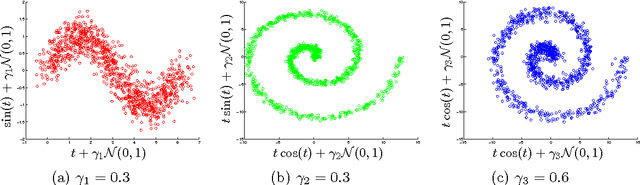
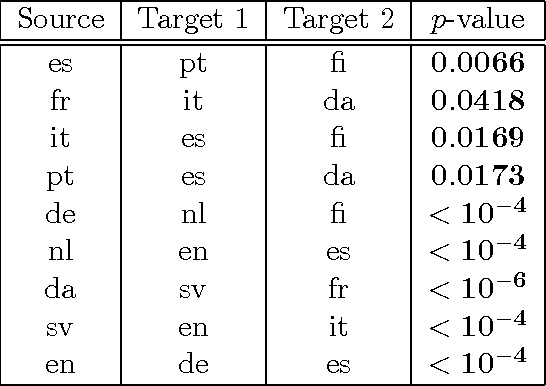
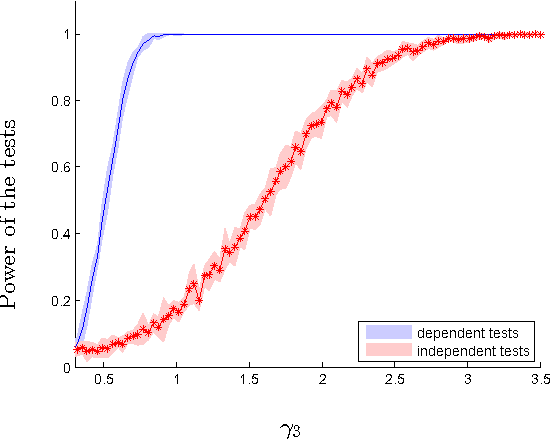
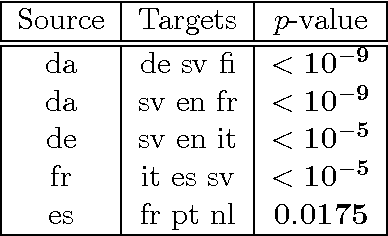
We introduce two novel non-parametric statistical hypothesis tests. The first test, called the relative test of dependency, enables us to determine whether one source variable is significantly more dependent on a first target variable or a second. Dependence is measured via the Hilbert-Schmidt Independence Criterion (HSIC). The second test, called the relative test of similarity, is use to determine which of the two samples from arbitrary distributions is significantly closer to a reference sample of interest and the relative measure of similarity is based on the Maximum Mean Discrepancy (MMD). To construct these tests, we have used as our test statistics the difference of HSIC statistics and of MMD statistics, respectively. The resulting tests are consistent and unbiased, and have favorable convergence properties. The effectiveness of the relative dependency test is demonstrated on several real-world problems: we identify languages groups from a multilingual parallel corpus, and we show that tumor location is more dependent on gene expression than chromosome imbalance. We also demonstrate the performance of the relative test of similarity over a broad selection of model comparisons problems in deep generative models.