 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScore-Based Diffusion meets Annealed Importance Sampling
Aug 17, 2022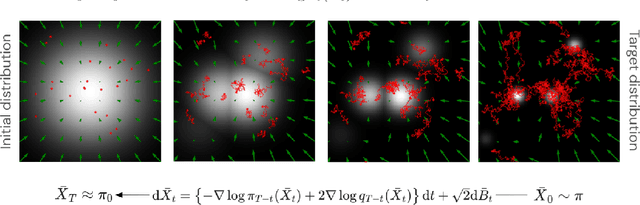
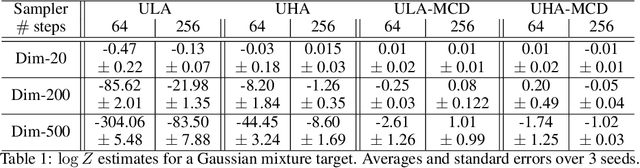
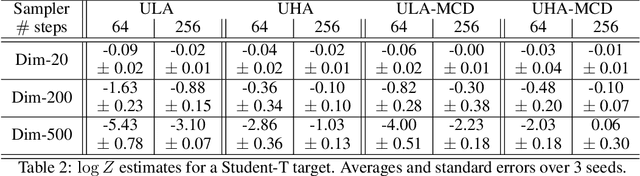
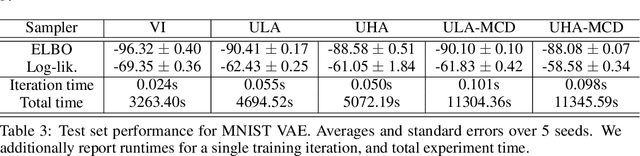
More than twenty years after its introduction, Annealed Importance Sampling (AIS) remains one of the most effective methods for marginal likelihood estimation. It relies on a sequence of distributions interpolating between a tractable initial distribution and the target distribution of interest which we simulate from approximately using a non-homogeneous Markov chain. To obtain an importance sampling estimate of the marginal likelihood, AIS introduces an extended target distribution to reweight the Markov chain proposal. While much effort has been devoted to improving the proposal distribution used by AIS, by changing the intermediate distributions and corresponding Markov kernels, an underappreciated issue is that AIS uses a convenient but suboptimal extended target distribution. This can hinder its performance. We here leverage recent progress in score-based generative modeling (SGM) to approximate the optimal extended target distribution for AIS proposals corresponding to the discretization of Langevin and Hamiltonian dynamics. We demonstrate these novel, differentiable, AIS procedures on a number of synthetic benchmark distributions and variational auto-encoders.
An Empirical Study of Implicit Regularization in Deep Offline RL
Jul 07, 2022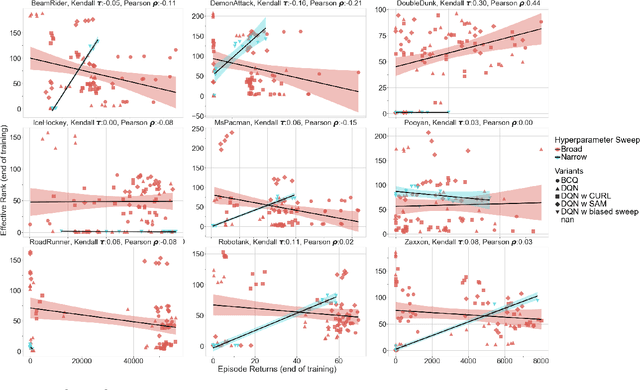

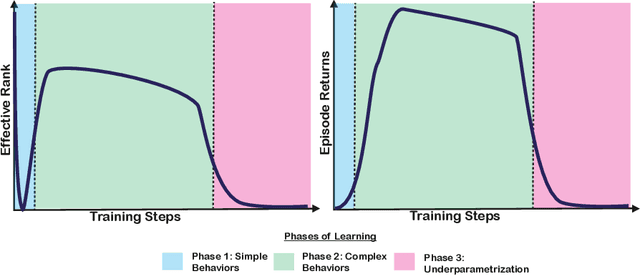

Deep neural networks are the most commonly used function approximators in offline reinforcement learning. Prior works have shown that neural nets trained with TD-learning and gradient descent can exhibit implicit regularization that can be characterized by under-parameterization of these networks. Specifically, the rank of the penultimate feature layer, also called \textit{effective rank}, has been observed to drastically collapse during the training. In turn, this collapse has been argued to reduce the model's ability to further adapt in later stages of learning, leading to the diminished final performance. Such an association between the effective rank and performance makes effective rank compelling for offline RL, primarily for offline policy evaluation. In this work, we conduct a careful empirical study on the relation between effective rank and performance on three offline RL datasets : bsuite, Atari, and DeepMind lab. We observe that a direct association exists only in restricted settings and disappears in the more extensive hyperparameter sweeps. Also, we empirically identify three phases of learning that explain the impact of implicit regularization on the learning dynamics and found that bootstrapping alone is insufficient to explain the collapse of the effective rank. Further, we show that several other factors could confound the relationship between effective rank and performance and conclude that studying this association under simplistic assumptions could be highly misleading.
Riemannian Diffusion Schrödinger Bridge
Jul 07, 2022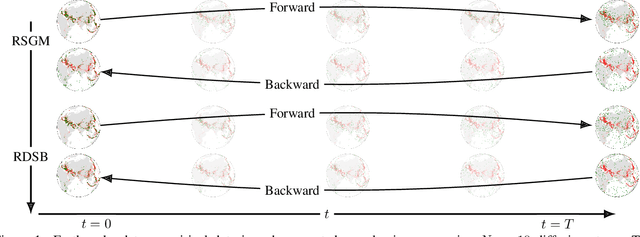
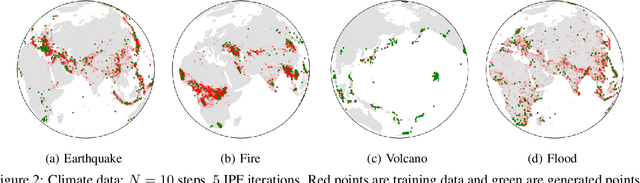

Score-based generative models exhibit state of the art performance on density estimation and generative modeling tasks. These models typically assume that the data geometry is flat, yet recent extensions have been developed to synthesize data living on Riemannian manifolds. Existing methods to accelerate sampling of diffusion models are typically not applicable in the Riemannian setting and Riemannian score-based methods have not yet been adapted to the important task of interpolation of datasets. To overcome these issues, we introduce \emph{Riemannian Diffusion Schr\"odinger Bridge}. Our proposed method generalizes Diffusion Schr\"odinger Bridge introduced in \cite{debortoli2021neurips} to the non-Euclidean setting and extends Riemannian score-based models beyond the first time reversal. We validate our proposed method on synthetic data and real Earth and climate data.
Ranking in Contextual Multi-Armed Bandits
Jun 30, 2022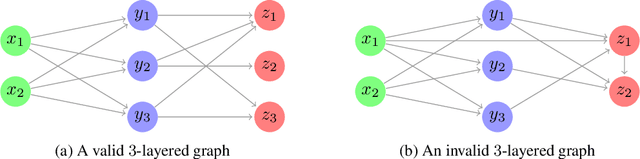
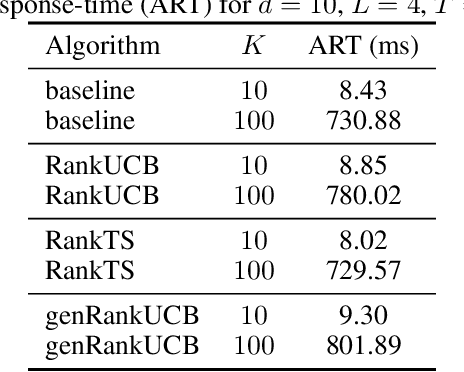
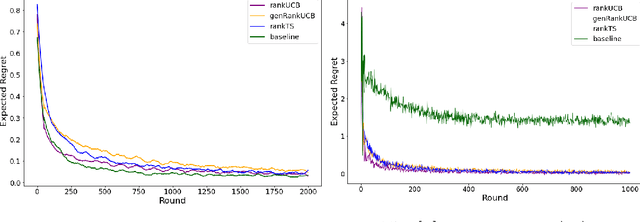
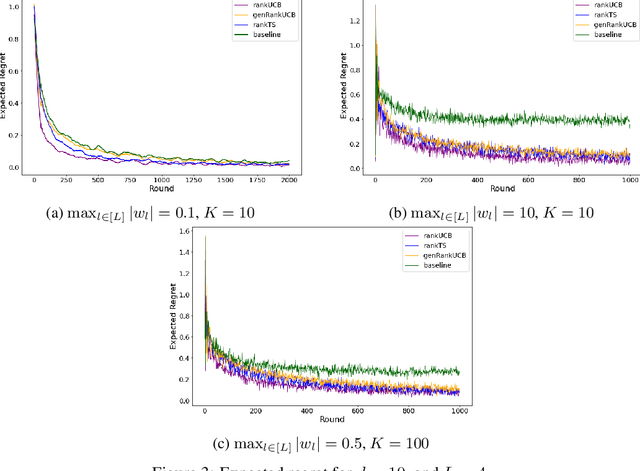
We study a ranking problem in the contextual multi-armed bandit setting. A learning agent selects an ordered list of items at each time step and observes stochastic outcomes for each position. In online recommendation systems, showing an ordered list of the most attractive items would not be the best choice since both position and item dependencies result in a complicated reward function. A very naive example is the lack of diversity when all the most attractive items are from the same category. We model position and item dependencies in the ordered list and design UCB and Thompson Sampling type algorithms for this problem. We prove that the regret bound over $T$ rounds and $L$ positions is $\Tilde{O}(L\sqrt{d T})$, which has the same order as the previous works with respect to $T$ and only increases linearly with $L$. Our work generalizes existing studies in several directions, including position dependencies where position discount is a particular case, and proposes a more general contextual bandit model.
Conformal Off-Policy Prediction in Contextual Bandits
Jun 09, 2022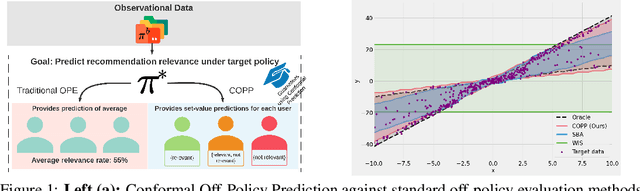

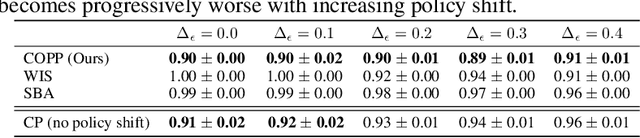
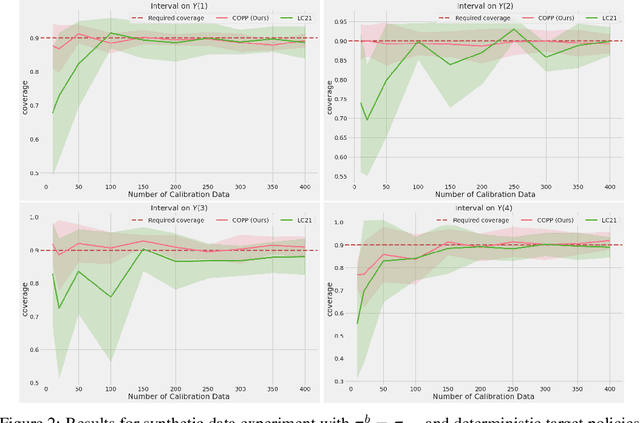
Most off-policy evaluation methods for contextual bandits have focused on the expected outcome of a policy, which is estimated via methods that at best provide only asymptotic guarantees. However, in many applications, the expectation may not be the best measure of performance as it does not capture the variability of the outcome. In addition, particularly in safety-critical settings, stronger guarantees than asymptotic correctness may be required. To address these limitations, we consider a novel application of conformal prediction to contextual bandits. Given data collected under a behavioral policy, we propose \emph{conformal off-policy prediction} (COPP), which can output reliable predictive intervals for the outcome under a new target policy. We provide theoretical finite-sample guarantees without making any additional assumptions beyond the standard contextual bandit setup, and empirically demonstrate the utility of COPP compared with existing methods on synthetic and real-world data.
A Continuous Time Framework for Discrete Denoising Models
May 30, 2022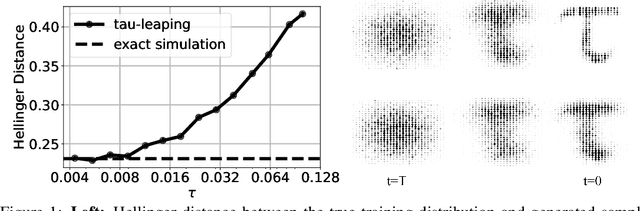
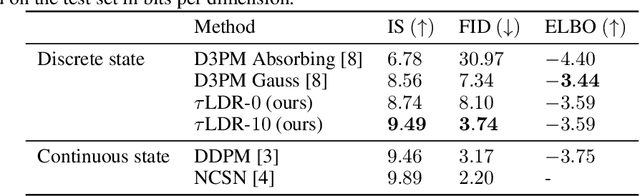


We provide the first complete continuous time framework for denoising diffusion models of discrete data. This is achieved by formulating the forward noising process and corresponding reverse time generative process as Continuous Time Markov Chains (CTMCs). The model can be efficiently trained using a continuous time version of the ELBO. We simulate the high dimensional CTMC using techniques developed in chemical physics and exploit our continuous time framework to derive high performance samplers that we show can outperform discrete time methods for discrete data. The continuous time treatment also enables us to derive a novel theoretical result bounding the error between the generated sample distribution and the true data distribution.
Towards Learning Universal Hyperparameter Optimizers with Transformers
May 26, 2022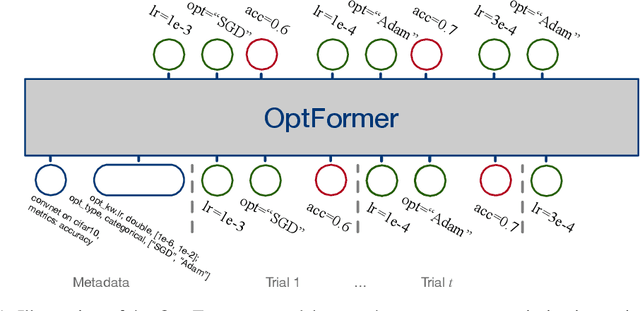


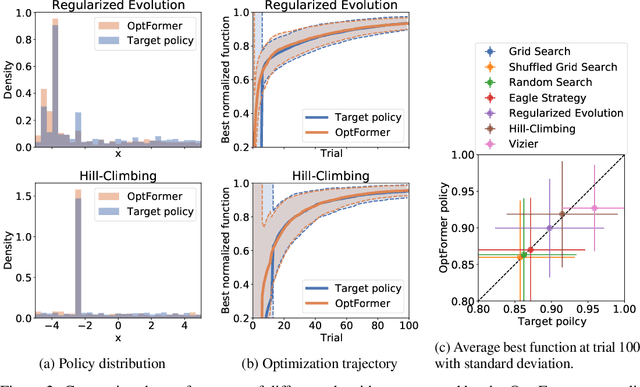
Meta-learning hyperparameter optimization (HPO) algorithms from prior experiments is a promising approach to improve optimization efficiency over objective functions from a similar distribution. However, existing methods are restricted to learning from experiments sharing the same set of hyperparameters. In this paper, we introduce the OptFormer, the first text-based Transformer HPO framework that provides a universal end-to-end interface for jointly learning policy and function prediction when trained on vast tuning data from the wild. Our extensive experiments demonstrate that the OptFormer can imitate at least 7 different HPO algorithms, which can be further improved via its function uncertainty estimates. Compared to a Gaussian Process, the OptFormer also learns a robust prior distribution for hyperparameter response functions, and can thereby provide more accurate and better calibrated predictions. This work paves the path to future extensions for training a Transformer-based model as a general HPO optimizer.
Chained Generalisation Bounds
Mar 02, 2022
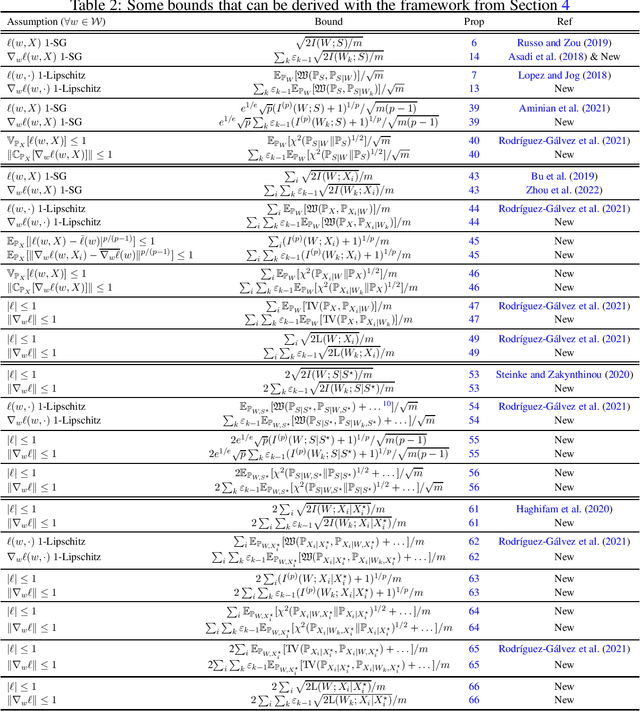
This work discusses how to derive upper bounds for the expected generalisation error of supervised learning algorithms by means of the chaining technique. By developing a general theoretical framework, we establish a duality between generalisation bounds based on the regularity of the loss function, and their chained counterparts, which can be obtained by lifting the regularity assumption from the loss onto its gradient. This allows us to re-derive the chaining mutual information bound from the literature, and to obtain novel chained information-theoretic generalisation bounds, based on the Wasserstein distance and other probability metrics. We show on some toy examples that the chained generalisation bound can be significantly tighter than its standard counterpart, particularly when the distribution of the hypotheses selected by the algorithm is very concentrated. Keywords: Generalisation bounds; Chaining; Information-theoretic bounds; Mutual information; Wasserstein distance; PAC-Bayes.
Conditional Simulation Using Diffusion Schrödinger Bridges
Feb 27, 2022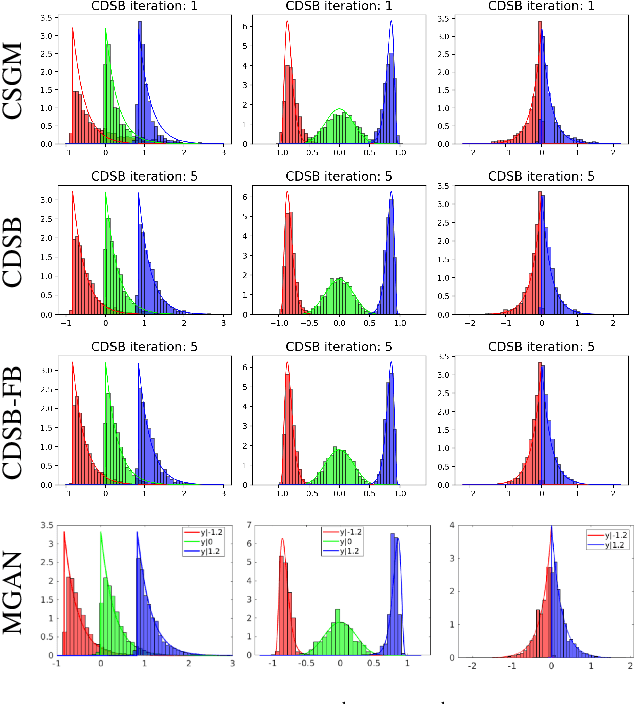
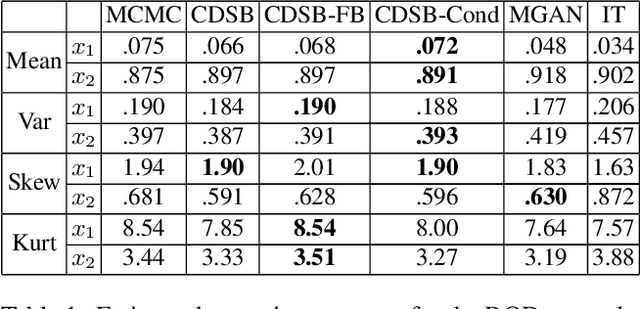


Denoising diffusion models have recently emerged as a powerful class of generative models. They provide state-of-the-art results, not only for unconditional simulation, but also when used to solve conditional simulation problems arising in a wide range of inverse problems such as image inpainting or deblurring. A limitation of these models is that they are computationally intensive at generation time as they require simulating a diffusion process over a long time horizon. When performing unconditional simulation, a Schr\"odinger bridge formulation of generative modeling leads to a theoretically grounded algorithm shortening generation time which is complementary to other proposed acceleration techniques. We extend here the Schr\"odinger bridge framework to conditional simulation. We demonstrate this novel methodology on various applications including image super-resolution and optimal filtering for state-space models.
On PAC-Bayesian reconstruction guarantees for VAEs
Feb 23, 2022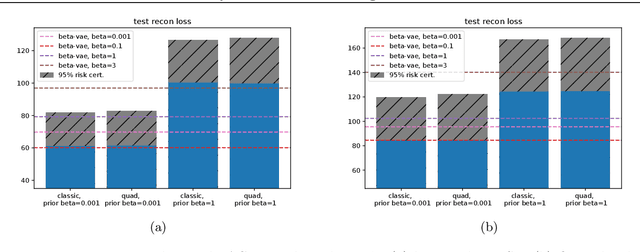
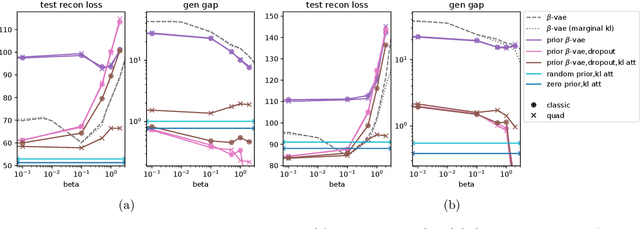
Despite its wide use and empirical successes, the theoretical understanding and study of the behaviour and performance of the variational autoencoder (VAE) have only emerged in the past few years. We contribute to this recent line of work by analysing the VAE's reconstruction ability for unseen test data, leveraging arguments from the PAC-Bayes theory. We provide generalisation bounds on the theoretical reconstruction error, and provide insights on the regularisation effect of VAE objectives. We illustrate our theoretical results with supporting experiments on classical benchmark datasets.
* 14 pages