 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTextual Data Bias Detection and Mitigation -- An Extensible Pipeline with Experimental Evaluation
Dec 12, 2025Textual data used to train large language models (LLMs) exhibits multifaceted bias manifestations encompassing harmful language and skewed demographic distributions. Regulations such as the European AI Act require identifying and mitigating biases against protected groups in data, with the ultimate goal of preventing unfair model outputs. However, practical guidance and operationalization are lacking. We propose a comprehensive data bias detection and mitigation pipeline comprising four components that address two data bias types, namely representation bias and (explicit) stereotypes for a configurable sensitive attribute. First, we leverage LLM-generated word lists created based on quality criteria to detect relevant group labels. Second, representation bias is quantified using the Demographic Representation Score. Third, we detect and mitigate stereotypes using sociolinguistically informed filtering. Finally, we compensate representation bias through Grammar- and Context-Aware Counterfactual Data Augmentation. We conduct a two-fold evaluation using the examples of gender, religion and age. First, the effectiveness of each individual component on data debiasing is evaluated through human validation and baseline comparison. The findings demonstrate that we successfully reduce representation bias and (explicit) stereotypes in a text dataset. Second, the effect of data debiasing on model bias reduction is evaluated by bias benchmarking of several models (0.6B-8B parameters), fine-tuned on the debiased text dataset. This evaluation reveals that LLMs fine-tuned on debiased data do not consistently show improved performance on bias benchmarks, exposing critical gaps in current evaluation methodologies and highlighting the need for targeted data manipulation to address manifested model bias.
Guideline for Trustworthy Artificial Intelligence -- AI Assessment Catalog
Jun 20, 2023Artificial Intelligence (AI) has made impressive progress in recent years and represents a key technology that has a crucial impact on the economy and society. However, it is clear that AI and business models based on it can only reach their full potential if AI applications are developed according to high quality standards and are effectively protected against new AI risks. For instance, AI bears the risk of unfair treatment of individuals when processing personal data e.g., to support credit lending or staff recruitment decisions. The emergence of these new risks is closely linked to the fact that the behavior of AI applications, particularly those based on Machine Learning (ML), is essentially learned from large volumes of data and is not predetermined by fixed programmed rules. Thus, the issue of the trustworthiness of AI applications is crucial and is the subject of numerous major publications by stakeholders in politics, business and society. In addition, there is mutual agreement that the requirements for trustworthy AI, which are often described in an abstract way, must now be made clear and tangible. One challenge to overcome here relates to the fact that the specific quality criteria for an AI application depend heavily on the application context and possible measures to fulfill them in turn depend heavily on the AI technology used. Lastly, practical assessment procedures are needed to evaluate whether specific AI applications have been developed according to adequate quality standards. This AI assessment catalog addresses exactly this point and is intended for two target groups: Firstly, it provides developers with a guideline for systematically making their AI applications trustworthy. Secondly, it guides assessors and auditors on how to examine AI applications for trustworthiness in a structured way.
Learning Syllogism with Euler Neural-Networks
Jul 20, 2020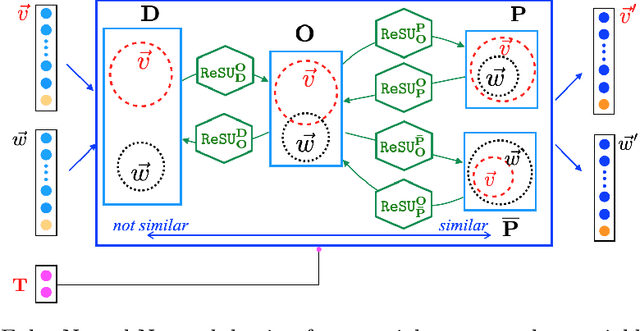
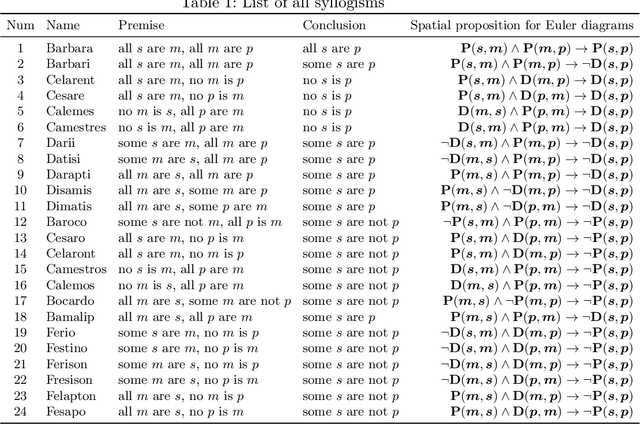
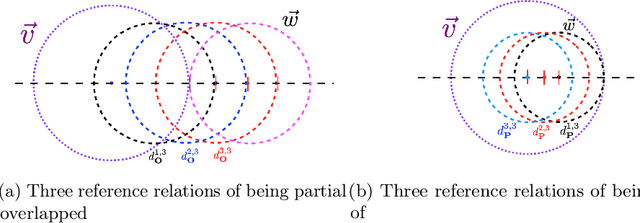

Traditional neural networks represent everything as a vector, and are able to approximate a subset of logical reasoning to a certain degree. As basic logic relations are better represented by topological relations between regions, we propose a novel neural network that represents everything as a ball and is able to learn topological configuration as an Euler diagram. So comes the name Euler Neural-Network (ENN). The central vector of a ball is a vector that can inherit representation power of traditional neural network. ENN distinguishes four spatial statuses between balls, namely, being disconnected, being partially overlapped, being part of, being inverse part of. Within each status, ideal values are defined for efficient reasoning. A novel back-propagation algorithm with six Rectified Spatial Units (ReSU) can optimize an Euler diagram representing logical premises, from which logical conclusion can be deduced. In contrast to traditional neural network, ENN can precisely represent all 24 different structures of Syllogism. Two large datasets are created: one extracted from WordNet-3.0 covers all types of Syllogism reasoning, the other extracted all family relations from DBpedia. Experiment results approve the superior power of ENN in logical representation and reasoning. Datasets and source code are available upon request.
Exploring Human Vision Driven Features for Pedestrian Detection
Jan 25, 2015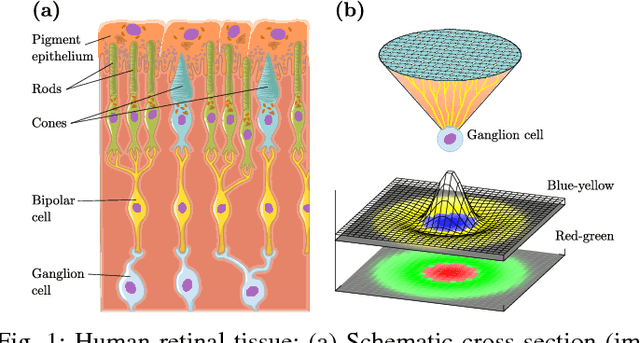
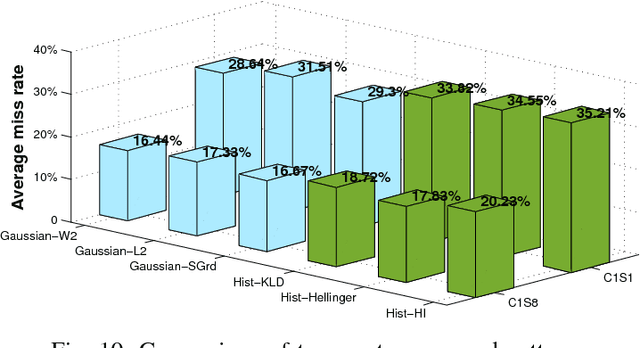
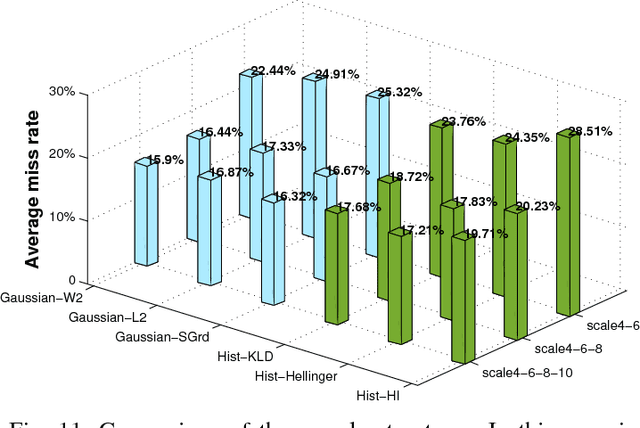
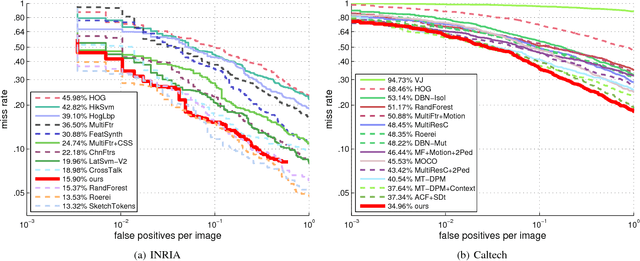
Motivated by the center-surround mechanism in the human visual attention system, we propose to use average contrast maps for the challenge of pedestrian detection in street scenes due to the observation that pedestrians indeed exhibit discriminative contrast texture. Our main contributions are first to design a local, statistical multi-channel descriptorin order to incorporate both color and gradient information. Second, we introduce a multi-direction and multi-scale contrast scheme based on grid-cells in order to integrate expressive local variations. Contributing to the issue of selecting most discriminative features for assessing and classification, we perform extensive comparisons w.r.t. statistical descriptors, contrast measurements, and scale structures. This way, we obtain reasonable results under various configurations. Empirical findings from applying our optimized detector on the INRIA and Caltech pedestrian datasets show that our features yield state-of-the-art performance in pedestrian detection.