 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen Do Data-Driven Systems Exhibit the Capability to Infer?
Jun 10, 2026The European AI Act is the first comprehensive regulation of artificial intelligence (AI), setting out extensive obligations, particularly for so-called high-risk and general-purpose AI systems. A key distinguishing feature of AI systems under the AI Act is the capability to infer. Since the AI Act does not clearly define what inference is, there is a gray area for certain data-driven systems. A specific example is credit scoring systems, which are listed by Annex III of the AI Act. At the same time, however, these are often implemented using statistical models for which it is unclear whether they have the capability to infer and thus fall under the AI definition of the AI Act at all. Motivated by statistical learning theory, this work develops a framework for grading different levels of the capability to infer. Based on the AI Act and the Commission Guidelines on the definition of an artificial intelligence system, we analyze which levels constitute sufficient capability to infer within the meaning of the AI Act and where further regulatory clarity is needed. We illustrate the framework by creating two realistic credit scoring workflows and show whether and where inference occurs in them. Our analysis illustrates that not only individual models but the entire data processing workflow must be considered. It also shows that the involvement of human experts during development can have significant influence on the capability to infer. Code can be found at https://github.com/fraunhofer-iais/inference-framework-creditscorecards.
Textual Data Bias Detection and Mitigation -- An Extensible Pipeline with Experimental Evaluation
Dec 12, 2025Textual data used to train large language models (LLMs) exhibits multifaceted bias manifestations encompassing harmful language and skewed demographic distributions. Regulations such as the European AI Act require identifying and mitigating biases against protected groups in data, with the ultimate goal of preventing unfair model outputs. However, practical guidance and operationalization are lacking. We propose a comprehensive data bias detection and mitigation pipeline comprising four components that address two data bias types, namely representation bias and (explicit) stereotypes for a configurable sensitive attribute. First, we leverage LLM-generated word lists created based on quality criteria to detect relevant group labels. Second, representation bias is quantified using the Demographic Representation Score. Third, we detect and mitigate stereotypes using sociolinguistically informed filtering. Finally, we compensate representation bias through Grammar- and Context-Aware Counterfactual Data Augmentation. We conduct a two-fold evaluation using the examples of gender, religion and age. First, the effectiveness of each individual component on data debiasing is evaluated through human validation and baseline comparison. The findings demonstrate that we successfully reduce representation bias and (explicit) stereotypes in a text dataset. Second, the effect of data debiasing on model bias reduction is evaluated by bias benchmarking of several models (0.6B-8B parameters), fine-tuned on the debiased text dataset. This evaluation reveals that LLMs fine-tuned on debiased data do not consistently show improved performance on bias benchmarks, exposing critical gaps in current evaluation methodologies and highlighting the need for targeted data manipulation to address manifested model bias.
LLMs and Memorization: On Quality and Specificity of Copyright Compliance
May 28, 2024



Memorization in large language models (LLMs) is a growing concern. LLMs have been shown to easily reproduce parts of their training data, including copyrighted work. This is an important problem to solve, as it may violate existing copyright laws as well as the European AI Act. In this work, we propose a systematic analysis to quantify the extent of potential copyright infringements in LLMs using European law as an example. Unlike previous work, we evaluate instruction-finetuned models in a realistic end-user scenario. Our analysis builds on a proposed threshold of 160 characters, which we borrow from the German Copyright Service Provider Act and a fuzzy text matching algorithm to identify potentially copyright-infringing textual reproductions. The specificity of countermeasures against copyright infringement is analyzed by comparing model behavior on copyrighted and public domain data. We investigate what behaviors models show instead of producing protected text (such as refusal or hallucination) and provide a first legal assessment of these behaviors. We find that there are huge differences in copyright compliance, specificity, and appropriate refusal among popular LLMs. Alpaca, GPT 4, GPT 3.5, and Luminous perform best in our comparison, with OpenGPT-X, Alpaca, and Luminous producing a particularly low absolute number of potential copyright violations. Code will be published soon.
Guideline for Trustworthy Artificial Intelligence -- AI Assessment Catalog
Jun 20, 2023Artificial Intelligence (AI) has made impressive progress in recent years and represents a key technology that has a crucial impact on the economy and society. However, it is clear that AI and business models based on it can only reach their full potential if AI applications are developed according to high quality standards and are effectively protected against new AI risks. For instance, AI bears the risk of unfair treatment of individuals when processing personal data e.g., to support credit lending or staff recruitment decisions. The emergence of these new risks is closely linked to the fact that the behavior of AI applications, particularly those based on Machine Learning (ML), is essentially learned from large volumes of data and is not predetermined by fixed programmed rules. Thus, the issue of the trustworthiness of AI applications is crucial and is the subject of numerous major publications by stakeholders in politics, business and society. In addition, there is mutual agreement that the requirements for trustworthy AI, which are often described in an abstract way, must now be made clear and tangible. One challenge to overcome here relates to the fact that the specific quality criteria for an AI application depend heavily on the application context and possible measures to fulfill them in turn depend heavily on the AI technology used. Lastly, practical assessment procedures are needed to evaluate whether specific AI applications have been developed according to adequate quality standards. This AI assessment catalog addresses exactly this point and is intended for two target groups: Firstly, it provides developers with a guideline for systematically making their AI applications trustworthy. Secondly, it guides assessors and auditors on how to examine AI applications for trustworthiness in a structured way.
A Survey on Uncertainty Toolkits for Deep Learning
May 02, 2022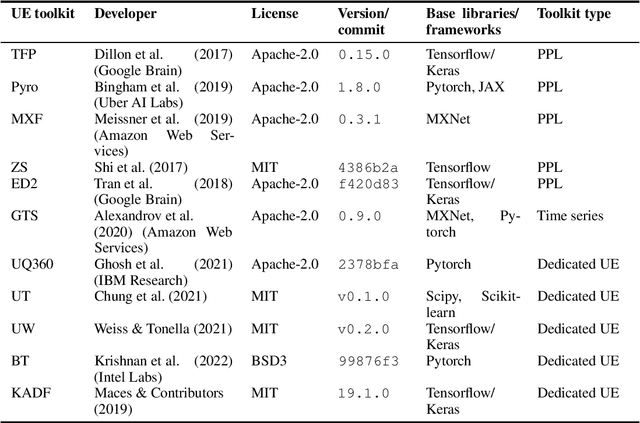
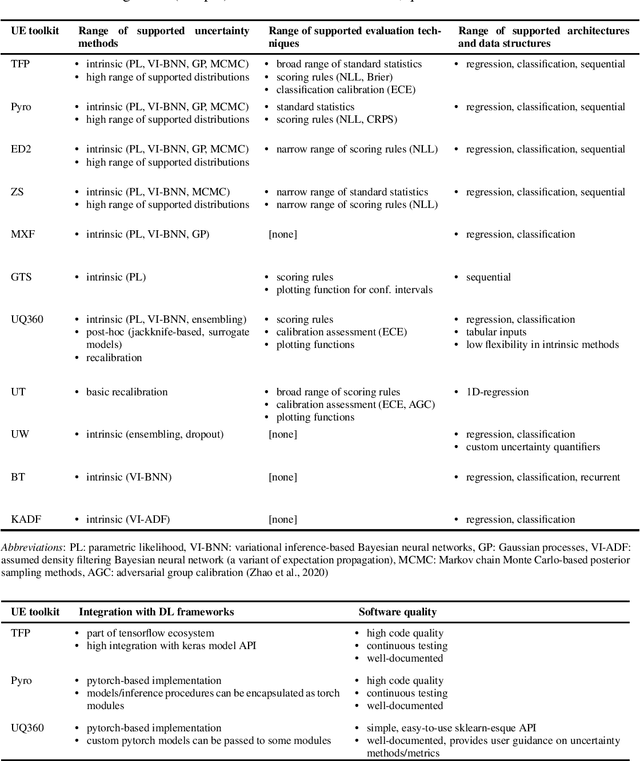
The success of deep learning (DL) fostered the creation of unifying frameworks such as tensorflow or pytorch as much as it was driven by their creation in return. Having common building blocks facilitates the exchange of, e.g., models or concepts and makes developments easier replicable. Nonetheless, robust and reliable evaluation and assessment of DL models has often proven challenging. This is at odds with their increasing safety relevance, which recently culminated in the field of "trustworthy ML". We believe that, among others, further unification of evaluation and safeguarding methodologies in terms of toolkits, i.e., small and specialized framework derivatives, might positively impact problems of trustworthiness as well as reproducibility. To this end, we present the first survey on toolkits for uncertainty estimation (UE) in DL, as UE forms a cornerstone in assessing model reliability. We investigate 11 toolkits with respect to modeling and evaluation capabilities, providing an in-depth comparison for the three most promising ones, namely Pyro, Tensorflow Probability, and Uncertainty Quantification 360. While the first two provide a large degree of flexibility and seamless integration into their respective framework, the last one has the larger methodological scope.
Inspect, Understand, Overcome: A Survey of Practical Methods for AI Safety
Apr 29, 2021The use of deep neural networks (DNNs) in safety-critical applications like mobile health and autonomous driving is challenging due to numerous model-inherent shortcomings. These shortcomings are diverse and range from a lack of generalization over insufficient interpretability to problems with malicious inputs. Cyber-physical systems employing DNNs are therefore likely to suffer from safety concerns. In recent years, a zoo of state-of-the-art techniques aiming to address these safety concerns has emerged. This work provides a structured and broad overview of them. We first identify categories of insufficiencies to then describe research activities aiming at their detection, quantification, or mitigation. Our paper addresses both machine learning experts and safety engineers: The former ones might profit from the broad range of machine learning topics covered and discussions on limitations of recent methods. The latter ones might gain insights into the specifics of modern ML methods. We moreover hope that our contribution fuels discussions on desiderata for ML systems and strategies on how to propel existing approaches accordingly.