 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTAG-Head: Time-Aligned Graph Head for Plug-and-Play Fine-grained Action Recognition
Apr 13, 2026Fine-grained human action recognition (FHAR) is challenging because visually similar actions differ by subtle spatio-temporal cues. Many recent systems enhance discriminability with extra modalities (e.g., pose, text, optical flow), but this increases annotation burden and computational cost. We introduce TAG-Head, a lightweight spatio-temporal graph head that upgrades standard 3D backbones (SlowFast, R(2+1)D-34, I3D, etc.) for FHAR using RGB only. Our pipeline first applies a Transformer encoder with learnable 3D positional encodings to the backbone tokens, capturing long-range dependencies across space and time. The resulting features are then refined by a graph in which (i) fully-connected intra-frame edges to resolve subtle appearance differences within frames, and (ii) time-aligned temporal edges that connect features at the same spatial location across frames to stabilise motion cues without over-smoothing. The head is compact (little parameter/FLOP overhead), plug-and-play across backbones, and trained end-to-end with the backbone. Extensive evaluations on FineGym (Gym99 and Gym288) and HAA500 show that TAG-Head sets a new state-of-the-art among RGB-only models and surpasses many recent multimodal approaches (video + pose + text) that rely on privileged information. Ablations disentangle the contributions of the Transformer and the graph topology, and complexity analyses confirm low latency. TAG-Head advances FHAR by explicitly coupling global context with high-resolution spatial interactions and low-variance temporal continuity inside a slim, composable graph head. The simplicity of the design enables straightforward adoption in practical systems that favour RGB-only sensors, while delivering performance gains typically associated with heavier or multimodal models. Code will be released on GitHub.
SR-GNN: Spatial Relation-aware Graph Neural Network for Fine-Grained Image Categorization
Sep 05, 2022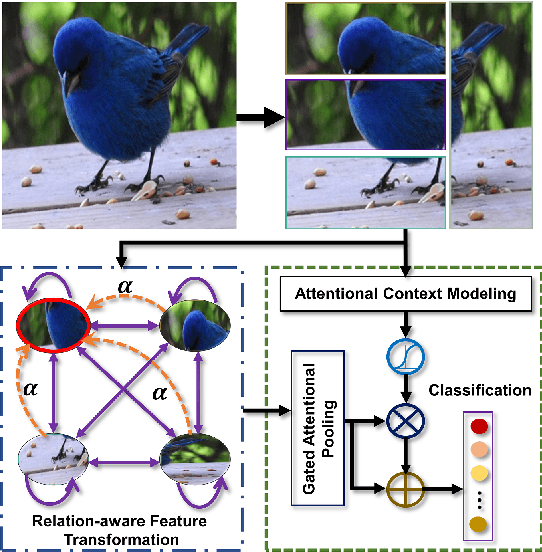
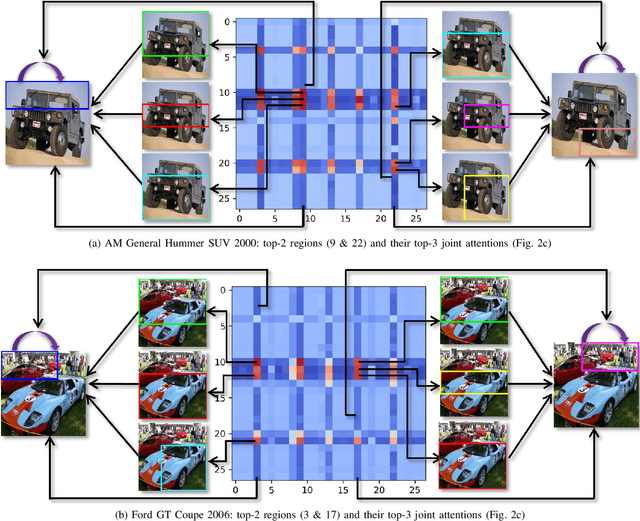
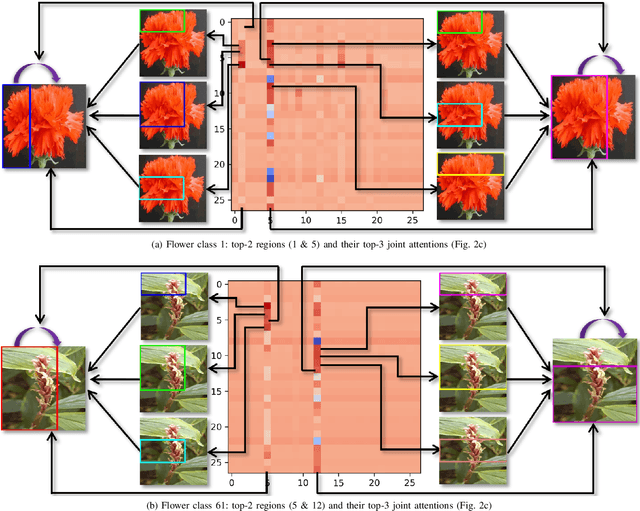
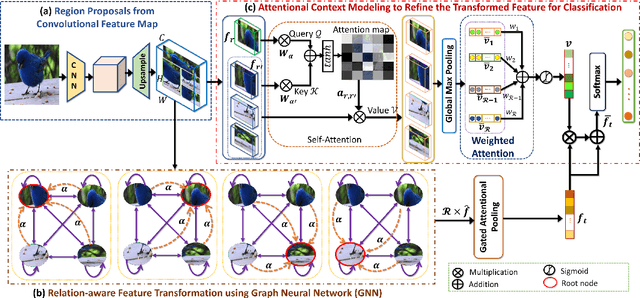
Over the past few years, a significant progress has been made in deep convolutional neural networks (CNNs)-based image recognition. This is mainly due to the strong ability of such networks in mining discriminative object pose and parts information from texture and shape. This is often inappropriate for fine-grained visual classification (FGVC) since it exhibits high intra-class and low inter-class variances due to occlusions, deformation, illuminations, etc. Thus, an expressive feature representation describing global structural information is a key to characterize an object/ scene. To this end, we propose a method that effectively captures subtle changes by aggregating context-aware features from most relevant image-regions and their importance in discriminating fine-grained categories avoiding the bounding-box and/or distinguishable part annotations. Our approach is inspired by the recent advancement in self-attention and graph neural networks (GNNs) approaches to include a simple yet effective relation-aware feature transformation and its refinement using a context-aware attention mechanism to boost the discriminability of the transformed feature in an end-to-end learning process. Our model is evaluated on eight benchmark datasets consisting of fine-grained objects and human-object interactions. It outperforms the state-of-the-art approaches by a significant margin in recognition accuracy.
Attend and Guide : A Keypoints-driven Attention-based Deep Network for Image Recognition
Oct 23, 2021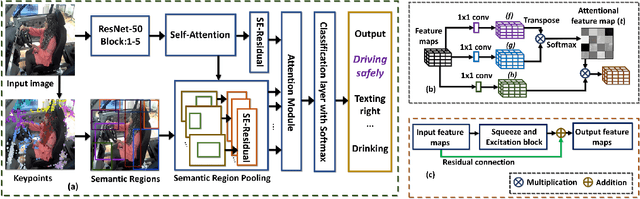
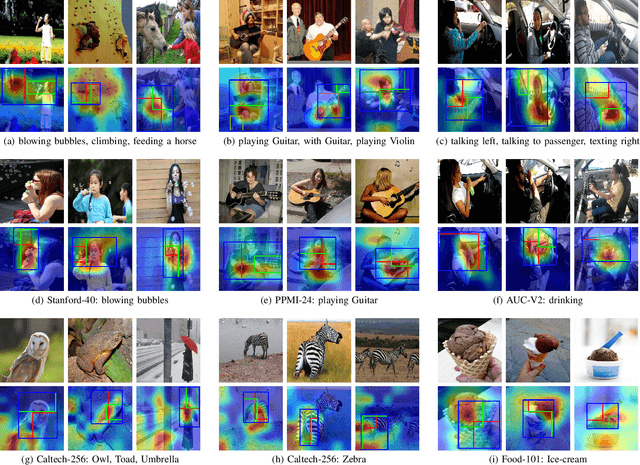


This paper presents a novel keypoints-based attention mechanism for visual recognition in still images. Deep Convolutional Neural Networks (CNNs) for recognizing images with distinctive classes have shown great success, but their performance in discriminating fine-grained changes is not at the same level. We address this by proposing an end-to-end CNN model, which learns meaningful features linking fine-grained changes using our novel attention mechanism. It captures the spatial structures in images by identifying semantic regions (SRs) and their spatial distributions, and is proved to be the key to modelling subtle changes in images. We automatically identify these SRs by grouping the detected keypoints in a given image. The ``usefulness'' of these SRs for image recognition is measured using our innovative attentional mechanism focusing on parts of the image that are most relevant to a given task. This framework applies to traditional and fine-grained image recognition tasks and does not require manually annotated regions (e.g. bounding-box of body parts, objects, etc.) for learning and prediction. Moreover, the proposed keypoints-driven attention mechanism can be easily integrated into the existing CNN models. The framework is evaluated on six diverse benchmark datasets. The model outperforms the state-of-the-art approaches by a considerable margin using Distracted Driver V1 (Acc: 3.39%), Distracted Driver V2 (Acc: 6.58%), Stanford-40 Actions (mAP: 2.15%), People Playing Musical Instruments (mAP: 16.05%), Food-101 (Acc: 6.30%) and Caltech-256 (Acc: 2.59%) datasets.
* Published in IEEE Transaction on Image Processing 2021, Vol. 30, pp. 3691 - 3704
Coarse Temporal Attention Network (CTA-Net) for Driver's Activity Recognition
Jan 17, 2021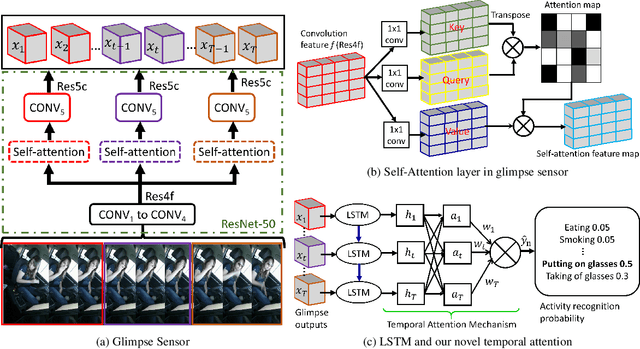
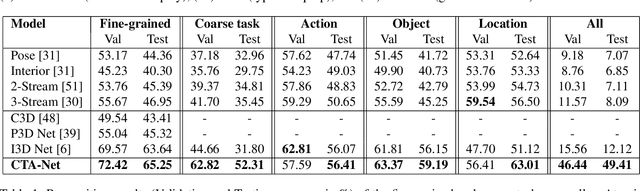

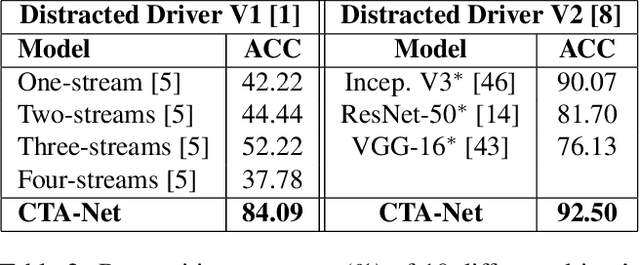
There is significant progress in recognizing traditional human activities from videos focusing on highly distinctive actions involving discriminative body movements, body-object and/or human-human interactions. Driver's activities are different since they are executed by the same subject with similar body parts movements, resulting in subtle changes. To address this, we propose a novel framework by exploiting the spatiotemporal attention to model the subtle changes. Our model is named Coarse Temporal Attention Network (CTA-Net), in which coarse temporal branches are introduced in a trainable glimpse network. The goal is to allow the glimpse to capture high-level temporal relationships, such as 'during', 'before' and 'after' by focusing on a specific part of a video. These branches also respect the topology of the temporal dynamics in the video, ensuring that different branches learn meaningful spatial and temporal changes. The model then uses an innovative attention mechanism to generate high-level action specific contextual information for activity recognition by exploring the hidden states of an LSTM. The attention mechanism helps in learning to decide the importance of each hidden state for the recognition task by weighing them when constructing the representation of the video. Our approach is evaluated on four publicly accessible datasets and significantly outperforms the state-of-the-art by a considerable margin with only RGB video as input.
* Extended version of the accepted WACV 2021
Regional Attention Network for Head Pose and Fine-grained Gesture Recognition
Jan 17, 2021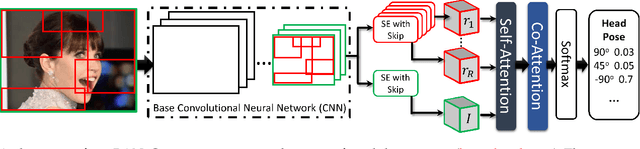
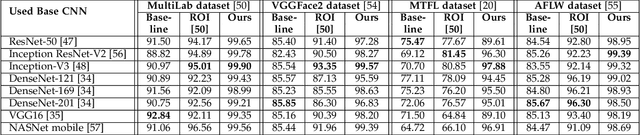
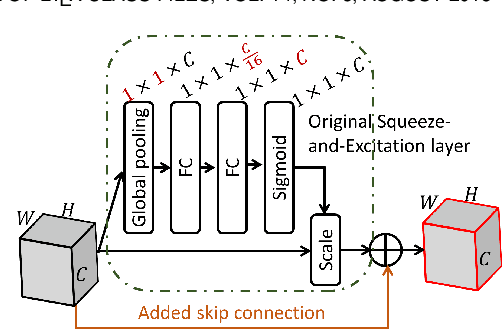
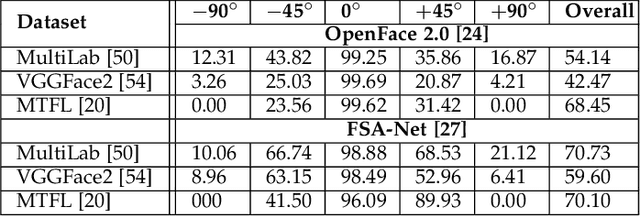
Affect is often expressed via non-verbal body language such as actions/gestures, which are vital indicators for human behaviors. Recent studies on recognition of fine-grained actions/gestures in monocular images have mainly focused on modeling spatial configuration of body parts representing body pose, human-objects interactions and variations in local appearance. The results show that this is a brittle approach since it relies on accurate body parts/objects detection. In this work, we argue that there exist local discriminative semantic regions, whose "informativeness" can be evaluated by the attention mechanism for inferring fine-grained gestures/actions. To this end, we propose a novel end-to-end \textbf{Regional Attention Network (RAN)}, which is a fully Convolutional Neural Network (CNN) to combine multiple contextual regions through attention mechanism, focusing on parts of the images that are most relevant to a given task. Our regions consist of one or more consecutive cells and are adapted from the strategies used in computing HOG (Histogram of Oriented Gradient) descriptor. The model is extensively evaluated on ten datasets belonging to 3 different scenarios: 1) head pose recognition, 2) drivers state recognition, and 3) human action and facial expression recognition. The proposed approach outperforms the state-of-the-art by a considerable margin in different metrics.
* This manuscript is the accepted version of the published paper in IEEE Transaction on Affective Computing