 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOverview of MWE history, challenges, and horizons: standing at the 20th anniversary of the MWE workshop series via MWE-UD2024
Dec 25, 2024Starting in 2003 when the first MWE workshop was held with ACL in Sapporo, Japan, this year, the joint workshop of MWE-UD co-located with the LREC-COLING 2024 conference marked the 20th anniversary of MWE workshop events over the past nearly two decades. Standing at this milestone, we look back to this workshop series and summarise the research topics and methodologies researchers have carried out over the years. We also discuss the current challenges that we are facing and the broader impacts/synergies of MWE research within the CL and NLP fields. Finally, we give future research perspectives. We hope this position paper can help researchers, students, and industrial practitioners interested in MWE get a brief but easy understanding of its history, current, and possible future.
UCxn: Typologically Informed Annotation of Constructions Atop Universal Dependencies
Mar 26, 2024



The Universal Dependencies (UD) project has created an invaluable collection of treebanks with contributions in over 140 languages. However, the UD annotations do not tell the full story. Grammatical constructions that convey meaning through a particular combination of several morphosyntactic elements -- for example, interrogative sentences with special markers and/or word orders -- are not labeled holistically. We argue for (i) augmenting UD annotations with a 'UCxn' annotation layer for such meaning-bearing grammatical constructions, and (ii) approaching this in a typologically informed way so that morphosyntactic strategies can be compared across languages. As a case study, we consider five construction families in ten languages, identifying instances of each construction in UD treebanks through the use of morphosyntactic patterns. In addition to findings regarding these particular constructions, our study yields important insights on methodology for describing and identifying constructions in language-general and language-particular ways, and lays the foundation for future constructional enrichment of UD treebanks.
Learning to Plan and Realize Separately for Open-Ended Dialogue Systems
Oct 04, 2020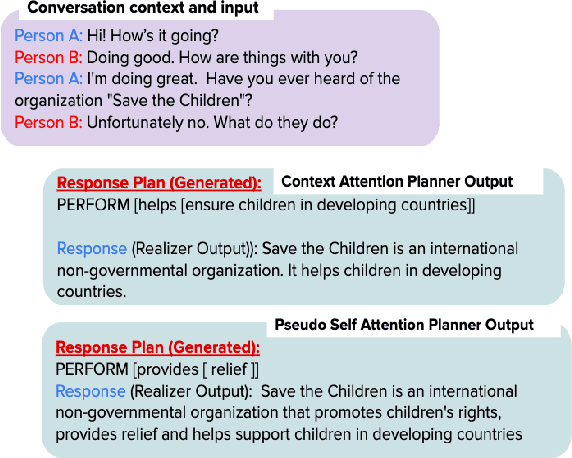

Achieving true human-like ability to conduct a conversation remains an elusive goal for open-ended dialogue systems. We posit this is because extant approaches towards natural language generation (NLG) are typically construed as end-to-end architectures that do not adequately model human generation processes. To investigate, we decouple generation into two separate phases: planning and realization. In the planning phase, we train two planners to generate plans for response utterances. The realization phase uses response plans to produce an appropriate response. Through rigorous evaluations, both automated and human, we demonstrate that decoupling the process into planning and realization performs better than an end-to-end approach.
From Spatial Relations to Spatial Configurations
Jul 19, 2020
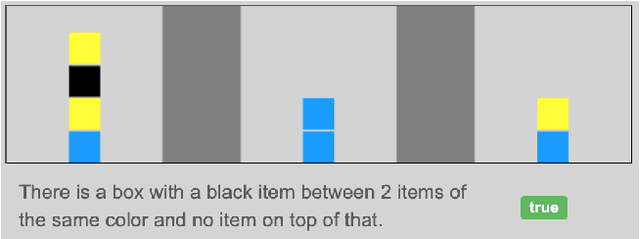
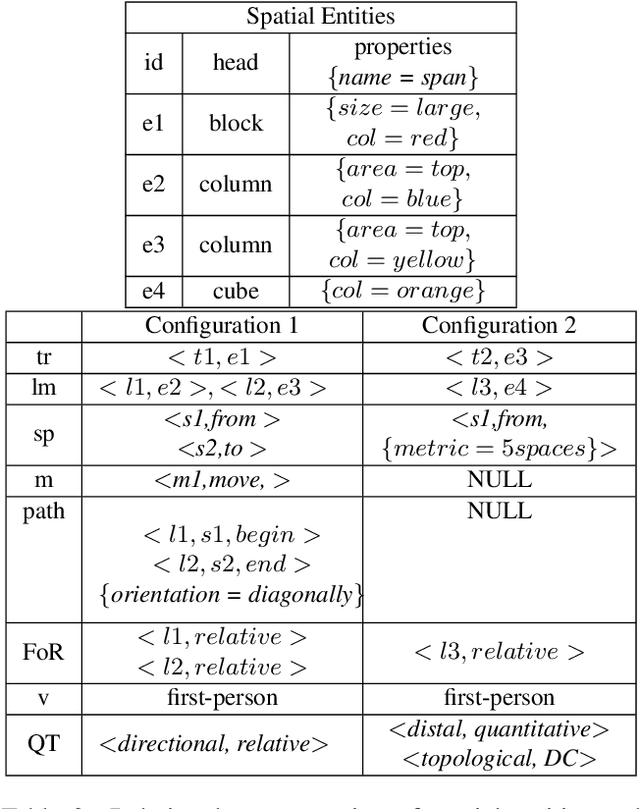
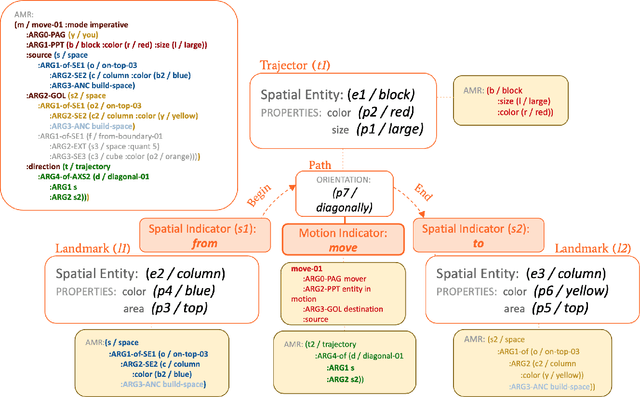
Spatial Reasoning from language is essential for natural language understanding. Supporting it requires a representation scheme that can capture spatial phenomena encountered in language as well as in images and videos. Existing spatial representations are not sufficient for describing spatial configurations used in complex tasks. This paper extends the capabilities of existing spatial representation languages and increases coverage of the semantic aspects that are needed to ground the spatial meaning of natural language text in the world. Our spatial relation language is able to represent a large, comprehensive set of spatial concepts crucial for reasoning and is designed to support the composition of static and dynamic spatial configurations. We integrate this language with the Abstract Meaning Representation(AMR) annotation schema and present a corpus annotated by this extended AMR. To exhibit the applicability of our representation scheme, we annotate text taken from diverse datasets and show how we extend the capabilities of existing spatial representation languages with the fine-grained decomposition of semantics and blend it seamlessly with AMRs of sentences and discourse representations as a whole.
The Panacea Threat Intelligence and Active Defense Platform
Apr 20, 2020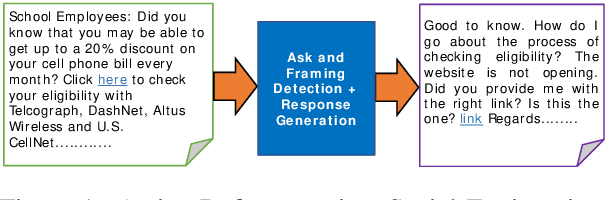
We describe Panacea, a system that supports natural language processing (NLP) components for active defenses against social engineering attacks. We deploy a pipeline of human language technology, including Ask and Framing Detection, Named Entity Recognition, Dialogue Engineering, and Stylometry. Panacea processes modern message formats through a plug-in architecture to accommodate innovative approaches for message analysis, knowledge representation and dialogue generation. The novelty of the Panacea system is that uses NLP for cyber defense and engages the attacker using bots to elicit evidence to attribute to the attacker and to waste the attacker's time and resources.
Adaptation of a Lexical Organization for Social Engineering Detection and Response Generation
Apr 20, 2020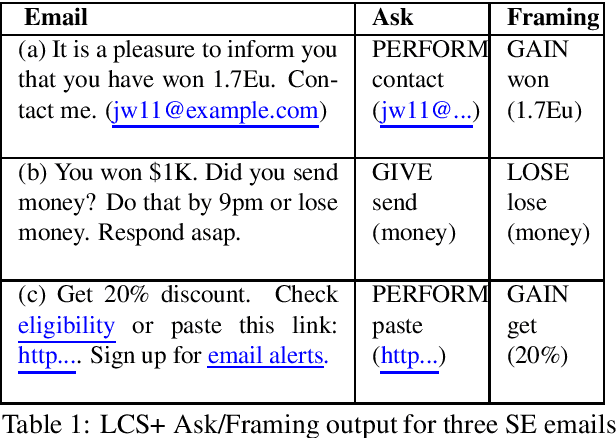

We present a paradigm for extensible lexicon development based on Lexical Conceptual Structure to support social engineering detection and response generation. We leverage the central notions of ask (elicitation of behaviors such as providing access to money) and framing (risk/reward implied by the ask). We demonstrate improvements in ask/framing detection through refinements to our lexical organization and show that response generation qualitatively improves as ask/framing detection performance improves. The paradigm presents a systematic and efficient approach to resource adaptation for improved task-specific performance.
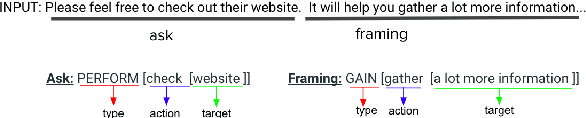
Detecting Asks in SE attacks: Impact of Linguistic and Structural Knowledge
Feb 25, 2020
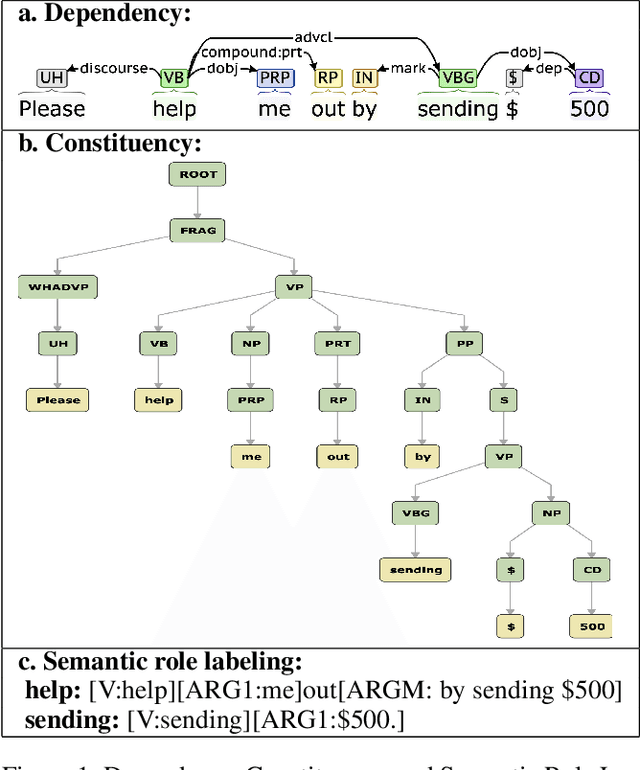
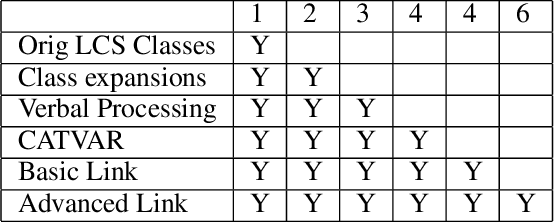
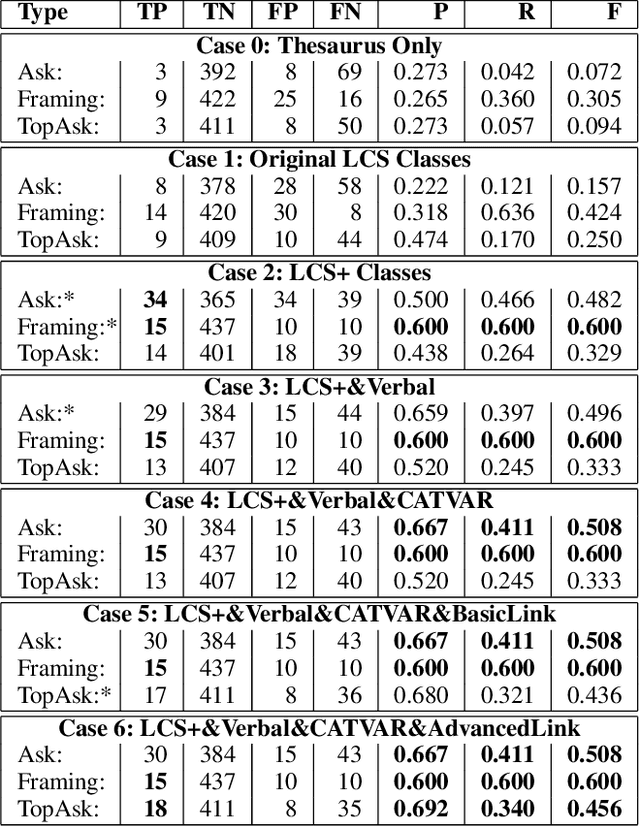
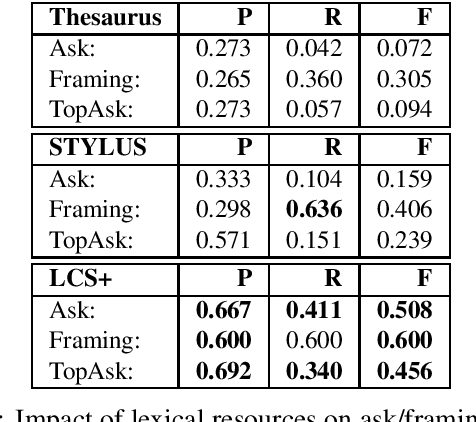
Social engineers attempt to manipulate users into undertaking actions such as downloading malware by clicking links or providing access to money or sensitive information. Natural language processing, computational sociolinguistics, and media-specific structural clues provide a means for detecting both the ask (e.g., buy gift card) and the risk/reward implied by the ask, which we call framing (e.g., lose your job, get a raise). We apply linguistic resources such as Lexical Conceptual Structure to tackle ask detection and also leverage structural clues such as links and their proximity to identified asks to improve confidence in our results. Our experiments indicate that the performance of ask detection, framing detection, and identification of the top ask is improved by linguistically motivated classes coupled with structural clues such as links. Our approach is implemented in a system that informs users about social engineering risk situations.
Adposition and Case Supersenses v2: Guidelines for English
Jul 02, 2018This document offers a detailed linguistic description of SNACS (Semantic Network of Adposition and Case Supersenses; Schneider et al., 2018), an inventory of 50 semantic labels ("supersenses") that characterize the use of adpositions and case markers at a somewhat coarse level of granularity, as demonstrated in the STREUSLE 4.1 corpus (https://github.com/nert-gu/streusle/). Though the SNACS inventory aspires to be universal, this document is specific to English; documentation for other languages will be published separately. Version 2 is a revision of the supersense inventory proposed for English by Schneider et al. (2015, 2016) (henceforth "v1"), which in turn was based on previous schemes. The present inventory was developed after extensive review of the v1 corpus annotations for English, plus previously unanalyzed genitive case possessives (Blodgett and Schneider, 2018), as well as consideration of adposition and case phenomena in Hebrew, Hindi, Korean, and German. Hwang et al. (2017) present the theoretical underpinnings of the v2 scheme. Schneider et al. (2018) summarize the scheme, its application to English corpus data, and an automatic disambiguation task.
Coping with Construals in Broad-Coverage Semantic Annotation of Adpositions
Mar 10, 2017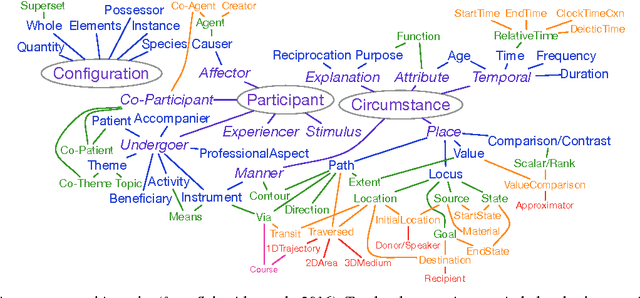
We consider the semantics of prepositions, revisiting a broad-coverage annotation scheme used for annotating all 4,250 preposition tokens in a 55,000 word corpus of English. Attempts to apply the scheme to adpositions and case markers in other languages, as well as some problematic cases in English, have led us to reconsider the assumption that a preposition's lexical contribution is equivalent to the role/relation that it mediates. Our proposal is to embrace the potential for construal in adposition use, expressing such phenomena directly at the token level to manage complexity and avoid sense proliferation. We suggest a framework to represent both the scene role and the adposition's lexical function so they can be annotated at scale---supporting automatic, statistical processing of domain-general language---and sketch how this representation would inform a constructional analysis.