 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImplicit SVD for Graph Representation Learning
Nov 11, 2021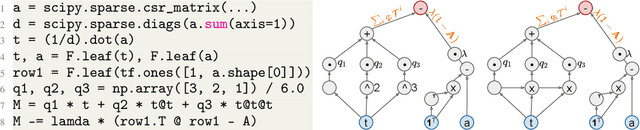
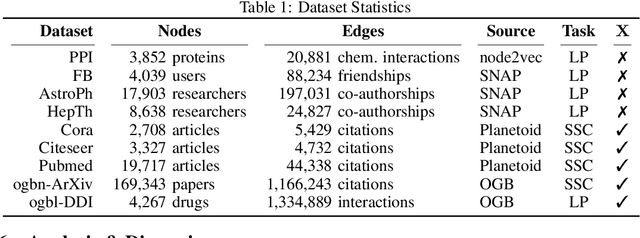
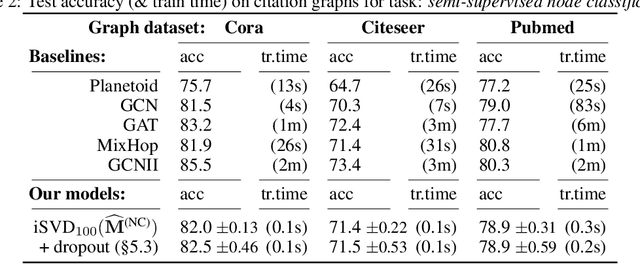
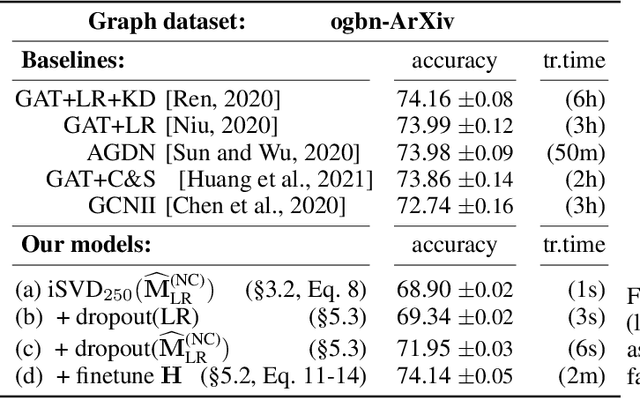
Recent improvements in the performance of state-of-the-art (SOTA) methods for Graph Representational Learning (GRL) have come at the cost of significant computational resource requirements for training, e.g., for calculating gradients via backprop over many data epochs. Meanwhile, Singular Value Decomposition (SVD) can find closed-form solutions to convex problems, using merely a handful of epochs. In this paper, we make GRL more computationally tractable for those with modest hardware. We design a framework that computes SVD of \textit{implicitly} defined matrices, and apply this framework to several GRL tasks. For each task, we derive linear approximation of a SOTA model, where we design (expensive-to-store) matrix $\mathbf{M}$ and train the model, in closed-form, via SVD of $\mathbf{M}$, without calculating entries of $\mathbf{M}$. By converging to a unique point in one step, and without calculating gradients, our models show competitive empirical test performance over various graphs such as article citation and biological interaction networks. More importantly, SVD can initialize a deeper model, that is architected to be non-linear almost everywhere, though behaves linearly when its parameters reside on a hyperplane, onto which SVD initializes. The deeper model can then be fine-tuned within only a few epochs. Overall, our procedure trains hundreds of times faster than state-of-the-art methods, while competing on empirical test performance. We open-source our implementation at: https://github.com/samihaija/isvd
Hamiltonian Dynamics with Non-Newtonian Momentum for Rapid Sampling
Nov 03, 2021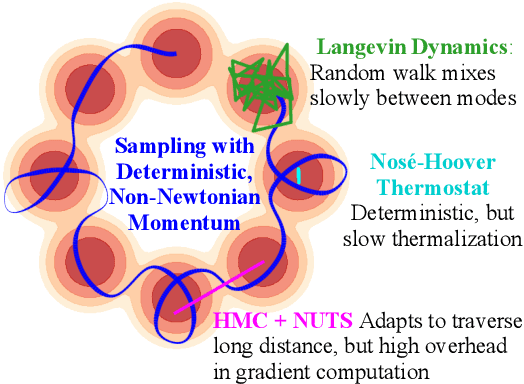
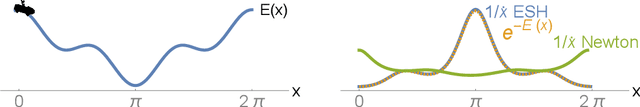
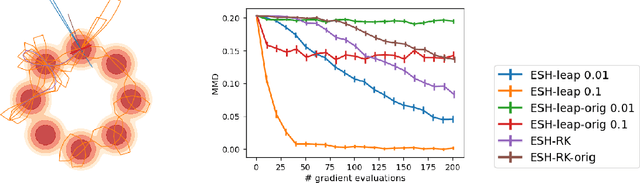
Sampling from an unnormalized probability distribution is a fundamental problem in machine learning with applications including Bayesian modeling, latent factor inference, and energy-based model training. After decades of research, variations of MCMC remain the default approach to sampling despite slow convergence. Auxiliary neural models can learn to speed up MCMC, but the overhead for training the extra model can be prohibitive. We propose a fundamentally different approach to this problem via a new Hamiltonian dynamics with a non-Newtonian momentum. In contrast to MCMC approaches like Hamiltonian Monte Carlo, no stochastic step is required. Instead, the proposed deterministic dynamics in an extended state space exactly sample the target distribution, specified by an energy function, under an assumption of ergodicity. Alternatively, the dynamics can be interpreted as a normalizing flow that samples a specified energy model without training. The proposed Energy Sampling Hamiltonian (ESH) dynamics have a simple form that can be solved with existing ODE solvers, but we derive a specialized solver that exhibits much better performance. ESH dynamics converge faster than their MCMC competitors enabling faster, more stable training of neural network energy models.
Cognitively Inspired Learning of Incremental Drifting Concepts
Oct 09, 2021
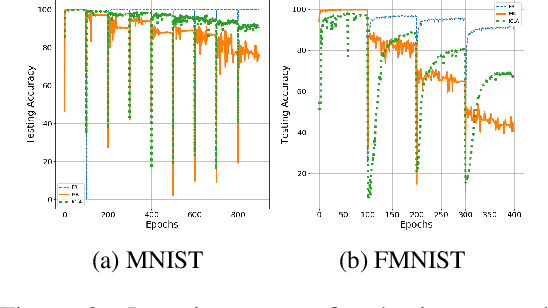
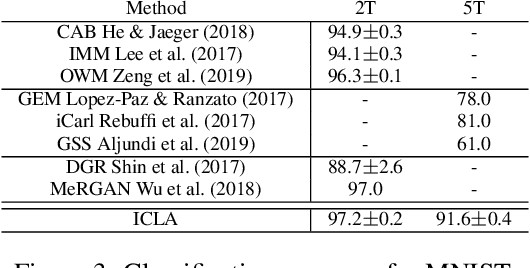
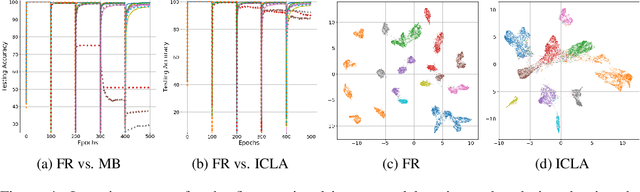
Humans continually expand their learned knowledge to new domains and learn new concepts without any interference with past learned experiences. In contrast, machine learning models perform poorly in a continual learning setting, where input data distribution changes over time. Inspired by the nervous system learning mechanisms, we develop a computational model that enables a deep neural network to learn new concepts and expand its learned knowledge to new domains incrementally in a continual learning setting. We rely on the Parallel Distributed Processing theory to encode abstract concepts in an embedding space in terms of a multimodal distribution. This embedding space is modeled by internal data representations in a hidden network layer. We also leverage the Complementary Learning Systems theory to equip the model with a memory mechanism to overcome catastrophic forgetting through implementing pseudo-rehearsal. Our model can generate pseudo-data points for experience replay and accumulate new experiences to past learned experiences without causing cross-task interference.
Information-theoretic generalization bounds for black-box learning algorithms
Oct 05, 2021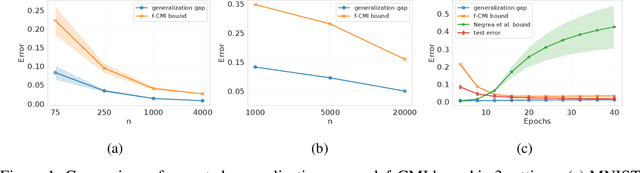

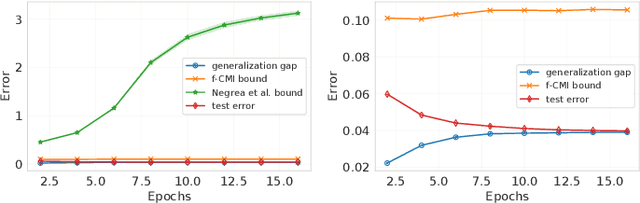

We derive information-theoretic generalization bounds for supervised learning algorithms based on the information contained in predictions rather than in the output of the training algorithm. These bounds improve over the existing information-theoretic bounds, are applicable to a wider range of algorithms, and solve two key challenges: (a) they give meaningful results for deterministic algorithms and (b) they are significantly easier to estimate. We show experimentally that the proposed bounds closely follow the generalization gap in practical scenarios for deep learning.
Partner-Assisted Learning for Few-Shot Image Classification
Sep 15, 2021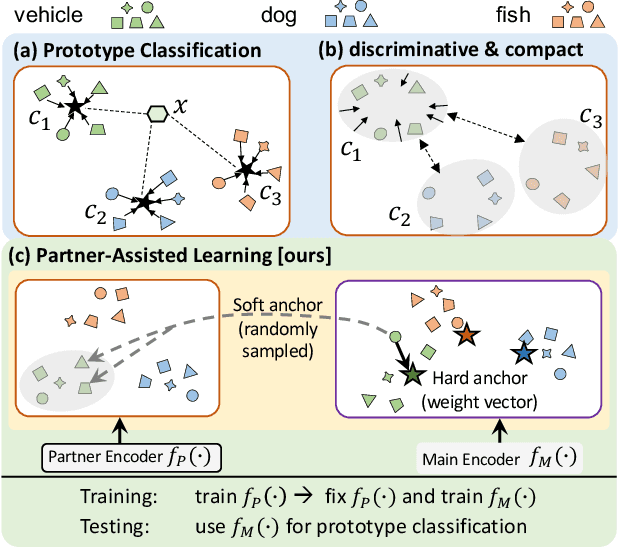
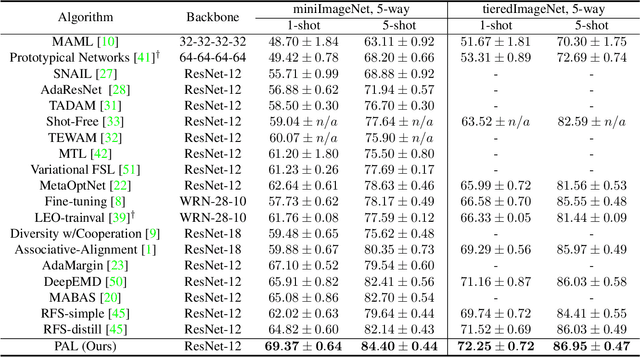
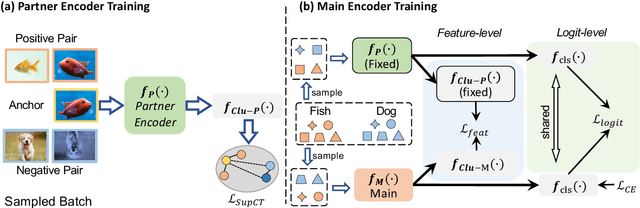
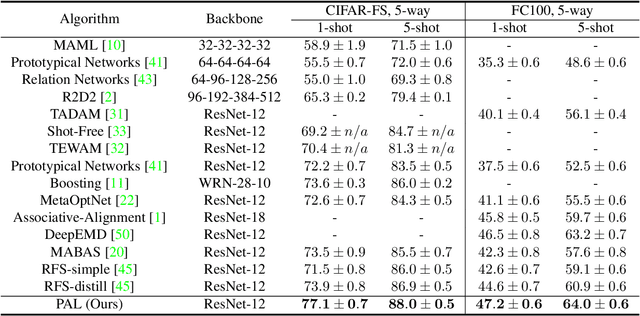
Few-shot Learning has been studied to mimic human visual capabilities and learn effective models without the need of exhaustive human annotation. Even though the idea of meta-learning for adaptation has dominated the few-shot learning methods, how to train a feature extractor is still a challenge. In this paper, we focus on the design of training strategy to obtain an elemental representation such that the prototype of each novel class can be estimated from a few labeled samples. We propose a two-stage training scheme, Partner-Assisted Learning (PAL), which first trains a partner encoder to model pair-wise similarities and extract features serving as soft-anchors, and then trains a main encoder by aligning its outputs with soft-anchors while attempting to maximize classification performance. Two alignment constraints from logit-level and feature-level are designed individually. For each few-shot task, we perform prototype classification. Our method consistently outperforms the state-of-the-art method on four benchmarks. Detailed ablation studies of PAL are provided to justify the selection of each component involved in training.
Attributing Fair Decisions with Attention Interventions
Sep 08, 2021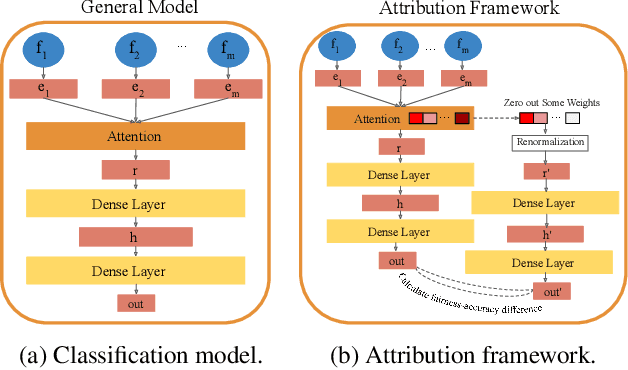

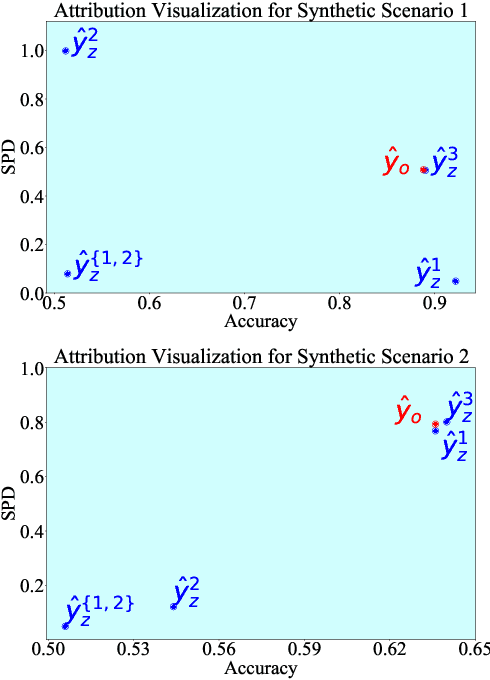

The widespread use of Artificial Intelligence (AI) in consequential domains, such as healthcare and parole decision-making systems, has drawn intense scrutiny on the fairness of these methods. However, ensuring fairness is often insufficient as the rationale for a contentious decision needs to be audited, understood, and defended. We propose that the attention mechanism can be used to ensure fair outcomes while simultaneously providing feature attributions to account for how a decision was made. Toward this goal, we design an attention-based model that can be leveraged as an attribution framework. It can identify features responsible for both performance and fairness of the model through attention interventions and attention weight manipulation. Using this attribution framework, we then design a post-processing bias mitigation strategy and compare it with a suite of baselines. We demonstrate the versatility of our approach by conducting experiments on two distinct data types, tabular and textual.
Domain Adaptation for Sentiment Analysis Using Increased Intraclass Separation
Jul 04, 2021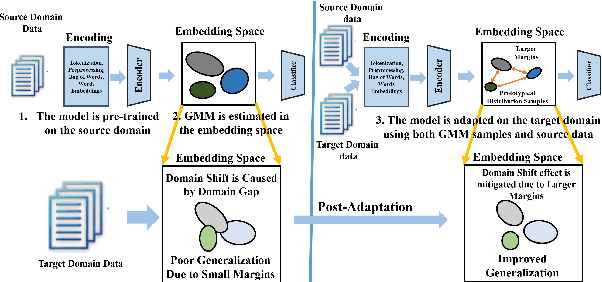
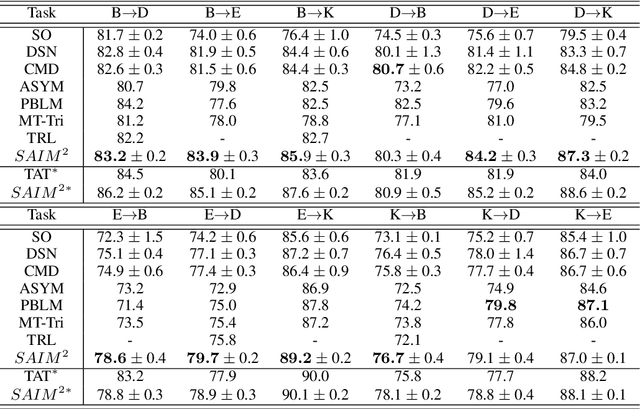
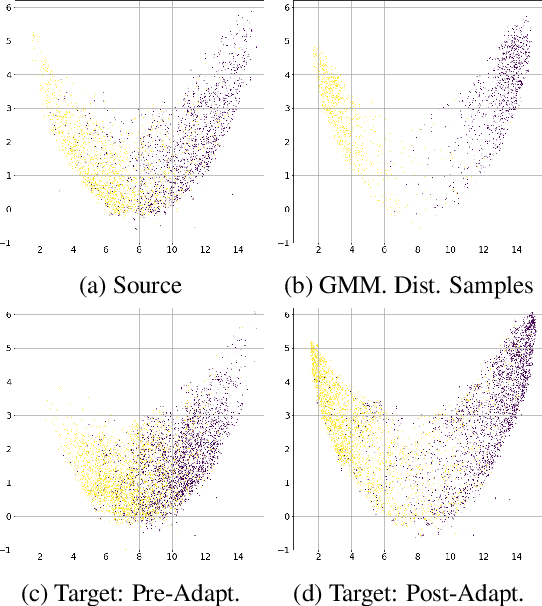
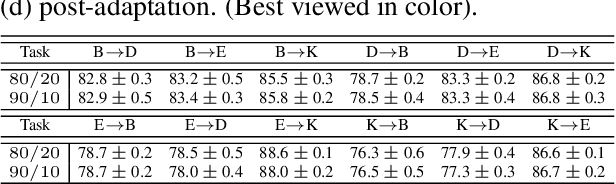
Sentiment analysis is a costly yet necessary task for enterprises to study the opinions of their customers to improve their products and to determine optimal marketing strategies. Due to the existence of a wide range of domains across different products and services, cross-domain sentiment analysis methods have received significant attention. These methods mitigate the domain gap between different applications by training cross-domain generalizable classifiers which help to relax the need for data annotation for each domain. Most existing methods focus on learning domain-agnostic representations that are invariant with respect to both the source and the target domains. As a result, a classifier that is trained using the source domain annotated data would generalize well in a related target domain. We introduce a new domain adaptation method which induces large margins between different classes in an embedding space. This embedding space is trained to be domain-agnostic by matching the data distributions across the domains. Large intraclass margins in the source domain help to reduce the effect of "domain shift" on the classifier performance in the target domain. Theoretical and empirical analysis are provided to demonstrate that the proposed method is effective.
q-Paths: Generalizing the Geometric Annealing Path using Power Means
Jul 01, 2021
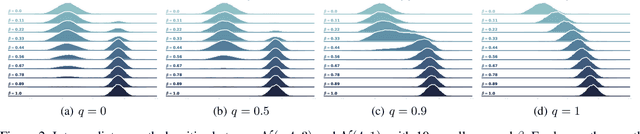
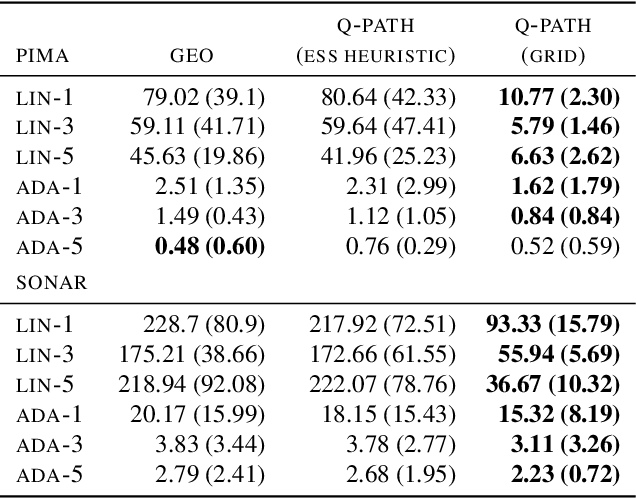

Many common machine learning methods involve the geometric annealing path, a sequence of intermediate densities between two distributions of interest constructed using the geometric average. While alternatives such as the moment-averaging path have demonstrated performance gains in some settings, their practical applicability remains limited by exponential family endpoint assumptions and a lack of closed form energy function. In this work, we introduce $q$-paths, a family of paths which is derived from a generalized notion of the mean, includes the geometric and arithmetic mixtures as special cases, and admits a simple closed form involving the deformed logarithm function from nonextensive thermodynamics. Following previous analysis of the geometric path, we interpret our $q$-paths as corresponding to a $q$-exponential family of distributions, and provide a variational representation of intermediate densities as minimizing a mixture of $\alpha$-divergences to the endpoints. We show that small deviations away from the geometric path yield empirical gains for Bayesian inference using Sequential Monte Carlo and generative model evaluation using Annealed Importance Sampling.
Plot-guided Adversarial Example Construction for Evaluating Open-domain Story Generation
Apr 12, 2021
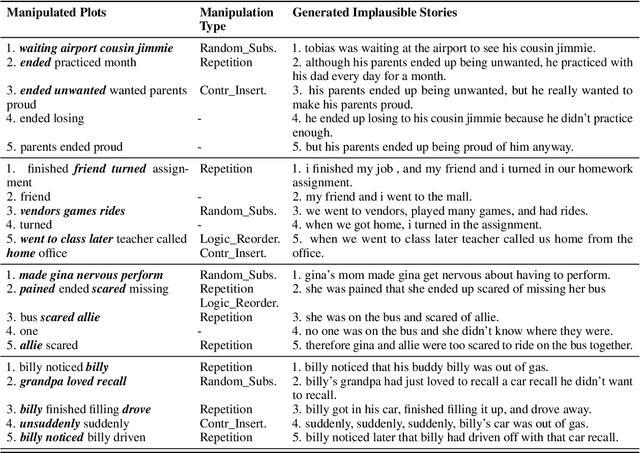
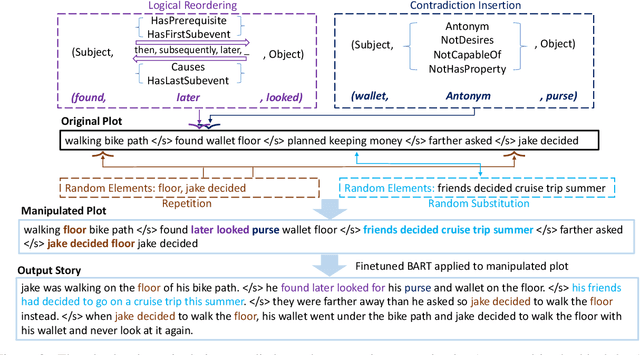
With the recent advances of open-domain story generation, the lack of reliable automatic evaluation metrics becomes an increasingly imperative issue that hinders the fast development of story generation. According to conducted researches in this regard, learnable evaluation metrics have promised more accurate assessments by having higher correlations with human judgments. A critical bottleneck of obtaining a reliable learnable evaluation metric is the lack of high-quality training data for classifiers to efficiently distinguish plausible and implausible machine-generated stories. Previous works relied on \textit{heuristically manipulated} plausible examples to mimic possible system drawbacks such as repetition, contradiction, or irrelevant content in the text level, which can be \textit{unnatural} and \textit{oversimplify} the characteristics of implausible machine-generated stories. We propose to tackle these issues by generating a more comprehensive set of implausible stories using {\em plots}, which are structured representations of controllable factors used to generate stories. Since these plots are compact and structured, it is easier to manipulate them to generate text with targeted undesirable properties, while at the same time maintain the grammatical correctness and naturalness of the generated sentences. To improve the quality of generated implausible stories, we further apply the adversarial filtering procedure presented by \citet{zellers2018swag} to select a more nuanced set of implausible texts. Experiments show that the evaluation metrics trained on our generated data result in more reliable automatic assessments that correlate remarkably better with human judgments compared to the baselines.
Lawyers are Dishonest? Quantifying Representational Harms in Commonsense Knowledge Resources
Mar 21, 2021

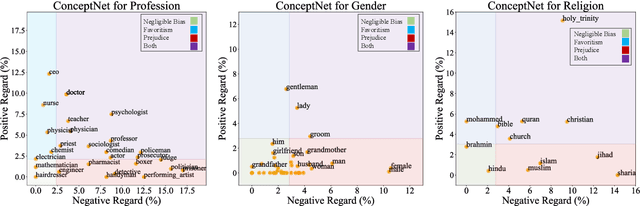

Warning: this paper contains content that may be offensive or upsetting. Numerous natural language processing models have tried injecting commonsense by using the ConceptNet knowledge base to improve performance on different tasks. ConceptNet, however, is mostly crowdsourced from humans and may reflect human biases such as "lawyers are dishonest." It is important that these biases are not conflated with the notion of commonsense. We study this missing yet important problem by first defining and quantifying biases in ConceptNet as two types of representational harms: overgeneralization of polarized perceptions and representation disparity. We find that ConceptNet contains severe biases and disparities across four demographic categories. In addition, we analyze two downstream models that use ConceptNet as a source for commonsense knowledge and find the existence of biases in those models as well. We further propose a filtered-based bias-mitigation approach and examine its effectiveness. We show that our mitigation approach can reduce the issues in both resource and models but leads to a performance drop, leaving room for future work to build fairer and stronger commonsense models.