 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBabyVLM: Data-Efficient Pretraining of VLMs Inspired by Infant Learning
Apr 13, 2025



Human infants rapidly develop visual reasoning skills from minimal input, suggesting that developmentally inspired pretraining could significantly enhance the efficiency of vision-language models (VLMs). Although recent efforts have leveraged infant-inspired datasets like SAYCam, existing evaluation benchmarks remain misaligned--they are either too simplistic, narrowly scoped, or tailored for large-scale pretrained models. Additionally, training exclusively on infant data overlooks the broader, diverse input from which infants naturally learn. To address these limitations, we propose BabyVLM, a novel framework comprising comprehensive in-domain evaluation benchmarks and a synthetic training dataset created via child-directed transformations of existing datasets. We demonstrate that VLMs trained with our synthetic dataset achieve superior performance on BabyVLM tasks compared to models trained solely on SAYCam or general-purpose data of the SAYCam size. BabyVLM thus provides a robust, developmentally aligned evaluation tool and illustrates how compact models trained on carefully curated data can generalize effectively, opening pathways toward data-efficient vision-language learning paradigms.
PanoFree: Tuning-Free Holistic Multi-view Image Generation with Cross-view Self-Guidance
Aug 04, 2024



Immersive scene generation, notably panorama creation, benefits significantly from the adaptation of large pre-trained text-to-image (T2I) models for multi-view image generation. Due to the high cost of acquiring multi-view images, tuning-free generation is preferred. However, existing methods are either limited to simple correspondences or require extensive fine-tuning to capture complex ones. We present PanoFree, a novel method for tuning-free multi-view image generation that supports an extensive array of correspondences. PanoFree sequentially generates multi-view images using iterative warping and inpainting, addressing the key issues of inconsistency and artifacts from error accumulation without the need for fine-tuning. It improves error accumulation by enhancing cross-view awareness and refines the warping and inpainting processes via cross-view guidance, risky area estimation and erasing, and symmetric bidirectional guided generation for loop closure, alongside guidance-based semantic and density control for scene structure preservation. In experiments on Planar, 360{\deg}, and Full Spherical Panoramas, PanoFree demonstrates significant error reduction, improves global consistency, and boosts image quality without extra fine-tuning. Compared to existing methods, PanoFree is up to 5x more efficient in time and 3x more efficient in GPU memory usage, and maintains superior diversity of results (2x better in our user study). PanoFree offers a viable alternative to costly fine-tuning or the use of additional pre-trained models. Project website at https://panofree.github.io/.
Direct Differentiable Augmentation Search
Apr 09, 2021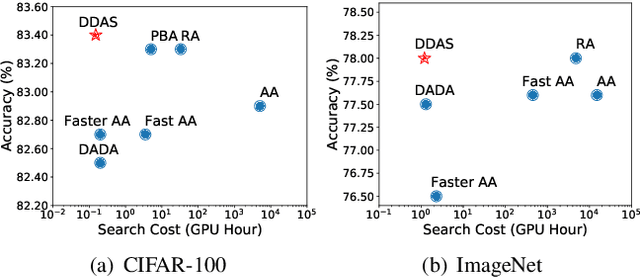

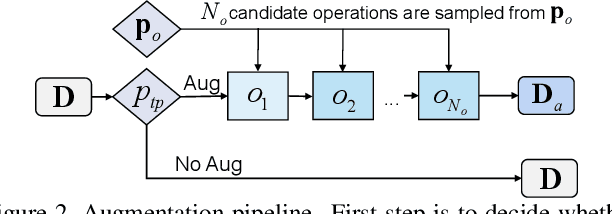
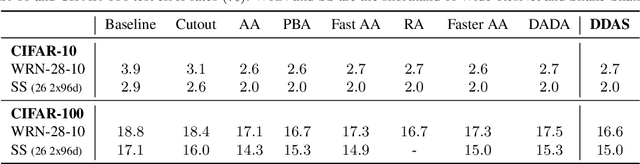
Data augmentation has been an indispensable tool to improve the performance of deep neural networks, however the augmentation can hardly transfer among different tasks and datasets. Consequently, a recent trend is to adopt AutoML technique to learn proper augmentation policy without extensive hand-crafted tuning. In this paper, we propose an efficient differentiable search algorithm called Direct Differentiable Augmentation Search (DDAS). It exploits meta-learning with one-step gradient update and continuous relaxation to the expected training loss for efficient search. Our DDAS can achieve efficient augmentation search without relying on approximations such as Gumbel Softmax or second order gradient approximation. To further reduce the adverse effect of improper augmentations, we organize the search space into a two level hierarchy, in which we first decide whether to apply augmentation, and then determine the specific augmentation policy. On standard image classification benchmarks, our DDAS achieves state-of-the-art performance and efficiency tradeoff while reducing the search cost dramatically, e.g. 0.15 GPU hours for CIFAR-10. In addition, we also use DDAS to search augmentation for object detection task and achieve comparable performance with AutoAugment, while being 1000x faster.
Neural Architecture Search as Sparse Supernet
Jul 31, 2020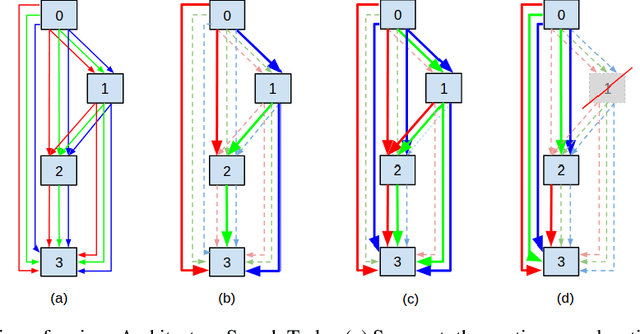
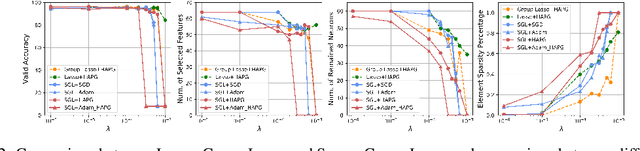
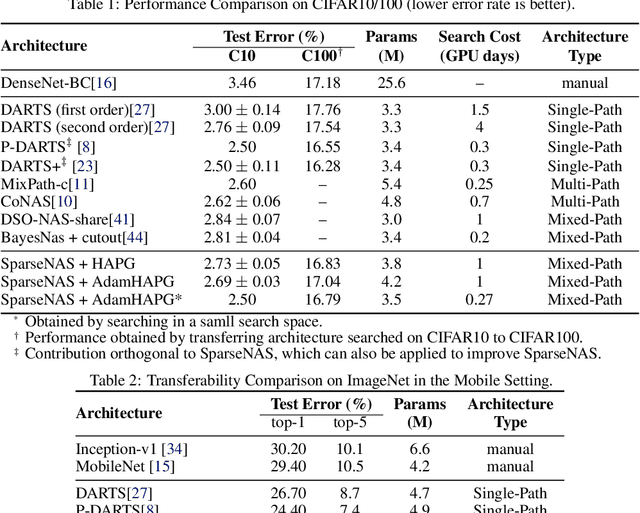
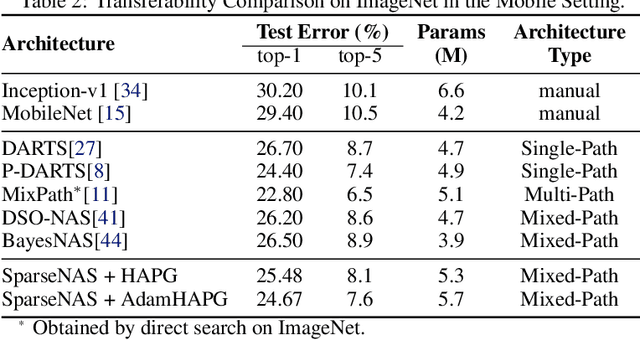
This paper aims at enlarging the problem of Neural Architecture Search from Single-Path and Multi-Path Search to automated Mixed-Path Search. In particular, we model the new problem as a sparse supernet with a new continuous architecture representation using a mixture of sparsity constraints, i.e., Sparse Group Lasso. The sparse supernet is expected to automatically achieve sparsely-mixed paths upon a compact set of nodes. To optimize the proposed sparse supernet, we exploit a hierarchical accelerated proximal gradient algorithm within a bi-level optimization framework. Extensive experiments on CIFAR-10, CIFAR-100, Tiny ImageNet and ImageNet demonstrate that the proposed methodology is capable of searching for compact, general and powerful neural architectures.