 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAsymptotics of Ridge Regression in Convolutional Models
Mar 08, 2021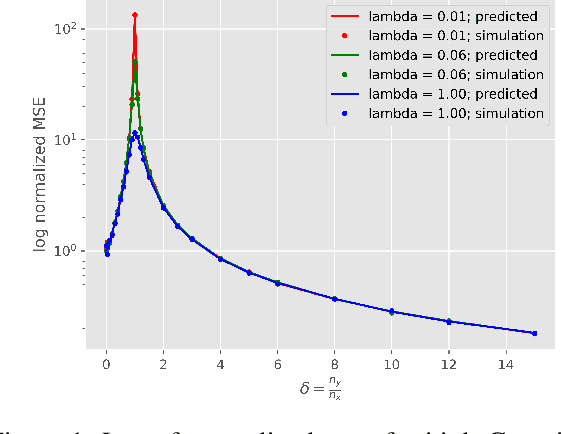
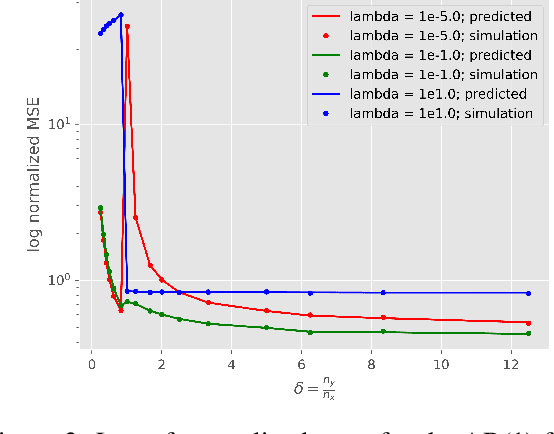
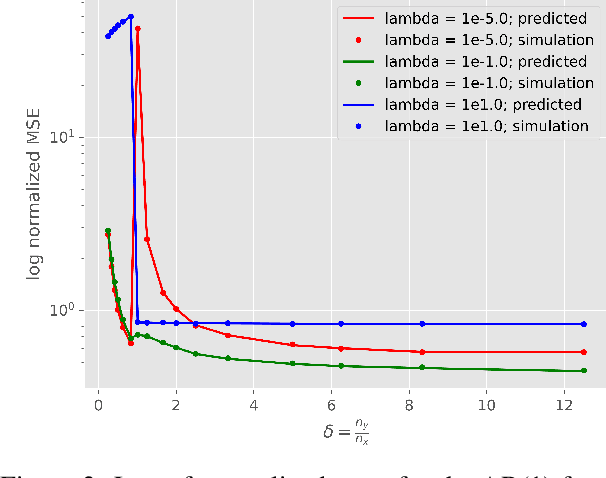
Understanding generalization and estimation error of estimators for simple models such as linear and generalized linear models has attracted a lot of attention recently. This is in part due to an interesting observation made in machine learning community that highly over-parameterized neural networks achieve zero training error, and yet they are able to generalize well over the test samples. This phenomenon is captured by the so called double descent curve, where the generalization error starts decreasing again after the interpolation threshold. A series of recent works tried to explain such phenomenon for simple models. In this work, we analyze the asymptotics of estimation error in ridge estimators for convolutional linear models. These convolutional inverse problems, also known as deconvolution, naturally arise in different fields such as seismology, imaging, and acoustics among others. Our results hold for a large class of input distributions that include i.i.d. features as a special case. We derive exact formulae for estimation error of ridge estimators that hold in a certain high-dimensional regime. We show the double descent phenomenon in our experiments for convolutional models and show that our theoretical results match the experiments.
Machine Unlearning via Algorithmic Stability
Feb 25, 2021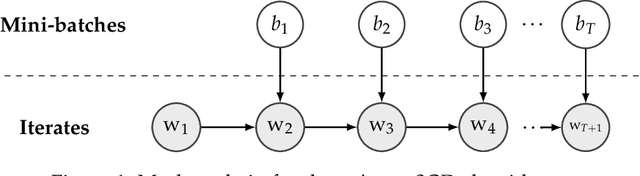
We study the problem of machine unlearning and identify a notion of algorithmic stability, Total Variation (TV) stability, which we argue, is suitable for the goal of exact unlearning. For convex risk minimization problems, we design TV-stable algorithms based on noisy Stochastic Gradient Descent (SGD). Our key contribution is the design of corresponding efficient unlearning algorithms, which are based on constructing a (maximal) coupling of Markov chains for the noisy SGD procedure. To understand the trade-offs between accuracy and unlearning efficiency, we give upper and lower bounds on excess empirical and populations risk of TV stable algorithms for convex risk minimization. Our techniques generalize to arbitrary non-convex functions, and our algorithms are differentially private as well.
Fundamental Tradeoffs in Distributionally Adversarial Training
Jan 15, 2021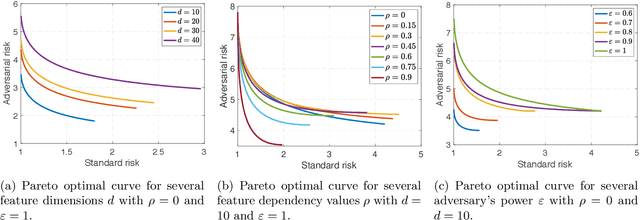
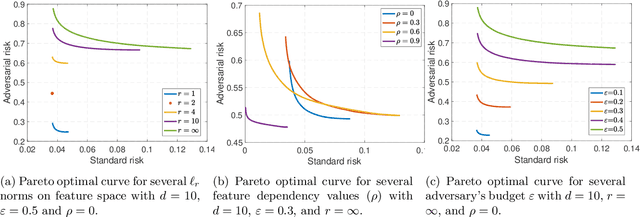
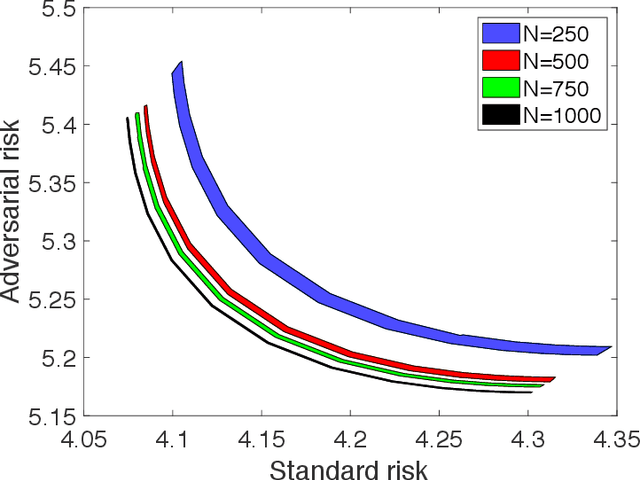
Adversarial training is among the most effective techniques to improve the robustness of models against adversarial perturbations. However, the full effect of this approach on models is not well understood. For example, while adversarial training can reduce the adversarial risk (prediction error against an adversary), it sometimes increase standard risk (generalization error when there is no adversary). Even more, such behavior is impacted by various elements of the learning problem, including the size and quality of training data, specific forms of adversarial perturbations in the input, model overparameterization, and adversary's power, among others. In this paper, we focus on \emph{distribution perturbing} adversary framework wherein the adversary can change the test distribution within a neighborhood of the training data distribution. The neighborhood is defined via Wasserstein distance between distributions and the radius of the neighborhood is a measure of adversary's manipulative power. We study the tradeoff between standard risk and adversarial risk and derive the Pareto-optimal tradeoff, achievable over specific classes of models, in the infinite data limit with features dimension kept fixed. We consider three learning settings: 1) Regression with the class of linear models; 2) Binary classification under the Gaussian mixtures data model, with the class of linear classifiers; 3) Regression with the class of random features model (which can be equivalently represented as two-layer neural network with random first-layer weights). We show that a tradeoff between standard and adversarial risk is manifested in all three settings. We further characterize the Pareto-optimal tradeoff curves and discuss how a variety of factors, such as features correlation, adversary's power or the width of two-layer neural network would affect this tradeoff.
Heterogeneous Graphlets
Oct 23, 2020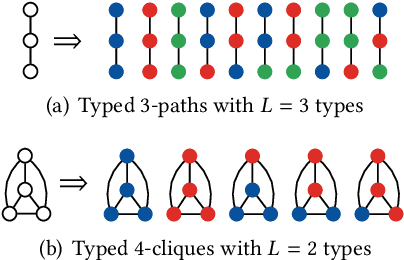


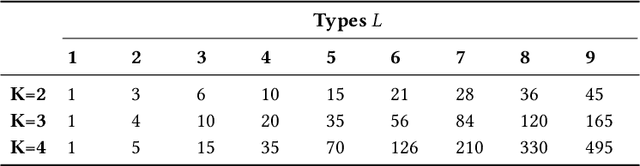
In this paper, we introduce a generalization of graphlets to heterogeneous networks called typed graphlets. Informally, typed graphlets are small typed induced subgraphs. Typed graphlets generalize graphlets to rich heterogeneous networks as they explicitly capture the higher-order typed connectivity patterns in such networks. To address this problem, we describe a general framework for counting the occurrences of such typed graphlets. The proposed algorithms leverage a number of combinatorial relationships for different typed graphlets. For each edge, we count a few typed graphlets, and with these counts along with the combinatorial relationships, we obtain the exact counts of the other typed graphlets in o(1) constant time. Notably, the worst-case time complexity of the proposed approach matches the time complexity of the best known untyped algorithm. In addition, the approach lends itself to an efficient lock-free and asynchronous parallel implementation. While there are no existing methods for typed graphlets, there has been some work that focused on computing a different and much simpler notion called colored graphlet. The experiments confirm that our proposed approach is orders of magnitude faster and more space-efficient than methods for computing the simpler notion of colored graphlet. Unlike these methods that take hours on small networks, the proposed approach takes only seconds on large networks with millions of edges. Notably, since typed graphlet is more general than colored graphlet (and untyped graphlets), the counts of various typed graphlets can be combined to obtain the counts of the much simpler notion of colored graphlets. The proposed methods give rise to new opportunities and applications for typed graphlets.
Efficient Balanced Treatment Assignments for Experimentation
Oct 21, 2020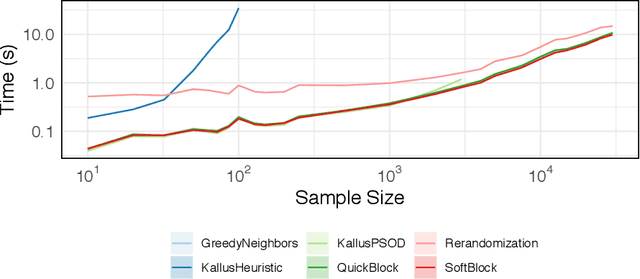
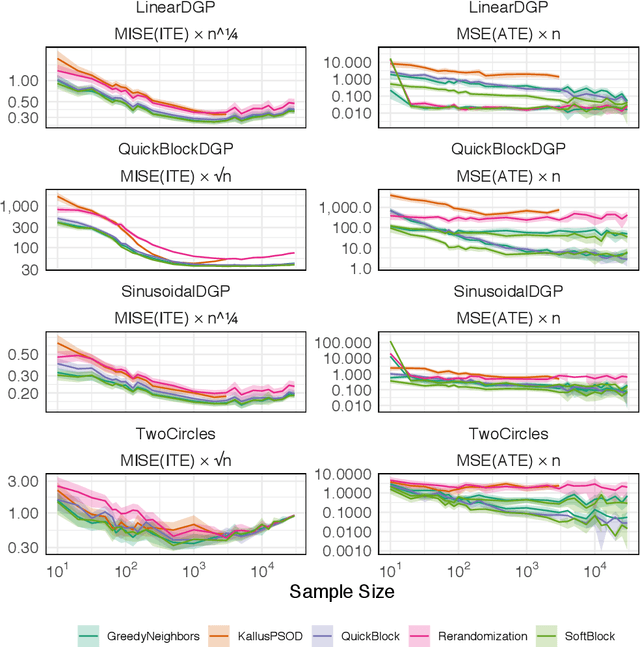
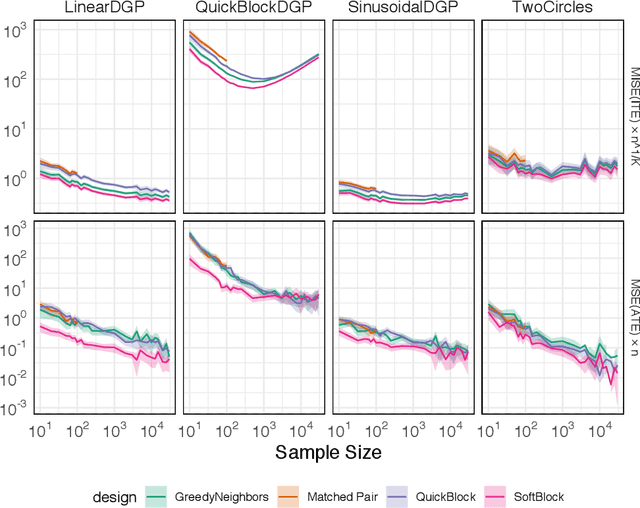
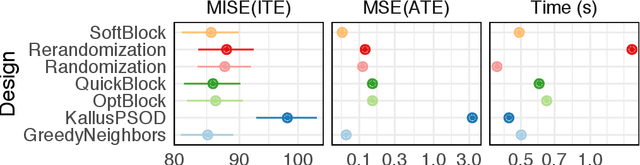
In this work, we reframe the problem of balanced treatment assignment as optimization of a two-sample test between test and control units. Using this lens we provide an assignment algorithm that is optimal with respect to the minimum spanning tree test of Friedman and Rafsky (1979). This assignment to treatment groups may be performed exactly in polynomial time. We provide a probabilistic interpretation of this process in terms of the most probable element of designs drawn from a determinantal point process which admits a probabilistic interpretation of the design. We provide a novel formulation of estimation as transductive inference and show how the tree structures used in design can also be used in an adjustment estimator. We conclude with a simulation study demonstrating the improved efficacy of our method.
Graph Neural Networks with Heterophily
Sep 28, 2020Graph Neural Networks (GNNs) have proven to be useful for many different practical applications. However, most existing GNN models have an implicit assumption of homophily among the nodes connected in the graph, and therefore have largely overlooked the important setting of heterophily. In this work, we propose a novel framework called CPGNN that generalizes GNNs for graphs with either homophily or heterophily. The proposed framework incorporates an interpretable compatibility matrix for modeling the heterophily or homophily level in the graph, which can be learned in an end-to-end fashion, enabling it to go beyond the assumption of strong homophily. Theoretically, we show that replacing the compatibility matrix in our framework with the identity (which represents pure homophily) reduces to GCN. Our extensive experiments demonstrate the effectiveness of our approach in more realistic and challenging experimental settings with significantly less training data compared to previous works: CPGNN variants achieve state-of-the-art results in heterophily settings with or without contextual node features, while maintaining comparable performance in homophily settings.
Sample Efficient Graph-Based Optimization with Noisy Observations
Jun 04, 2020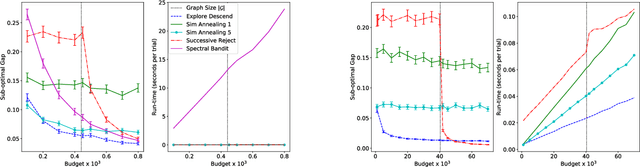
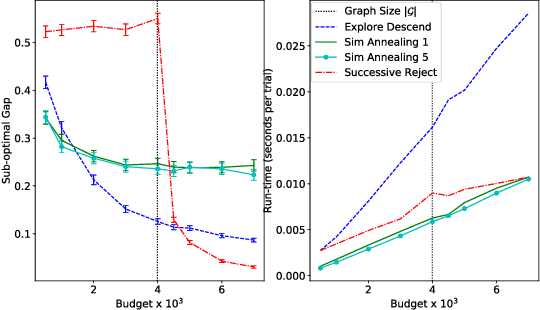
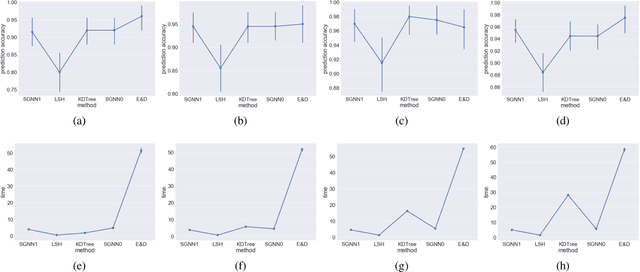
We study sample complexity of optimizing "hill-climbing friendly" functions defined on a graph under noisy observations. We define a notion of convexity, and we show that a variant of best-arm identification can find a near-optimal solution after a small number of queries that is independent of the size of the graph. For functions that have local minima and are nearly convex, we show a sample complexity for the classical simulated annealing under noisy observations. We show effectiveness of the greedy algorithm with restarts and the simulated annealing on problems of graph-based nearest neighbor classification as well as a web document re-ranking application.
* The first version of this paper appeared in AISTATS 2019. Thank to community feedback, some typos and a minor issue have been identified. Specifically, on page 4, column 2, line 18, the statement $\Delta_{1,s} \ge (1+m)^{S-1-s} \Delta_1$ is not valid, and in the proof of Theorem 2, "By Lemma 1" should be "By Definition 2". These problems are fixed in this updated version published here on arxiv
Model Selection in Contextual Stochastic Bandit Problems
Mar 03, 2020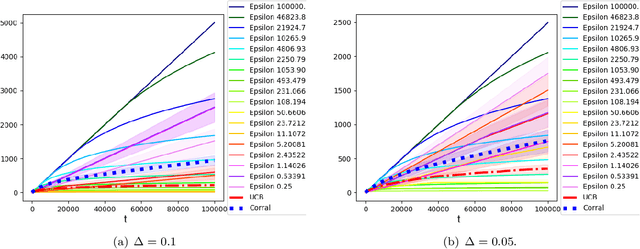
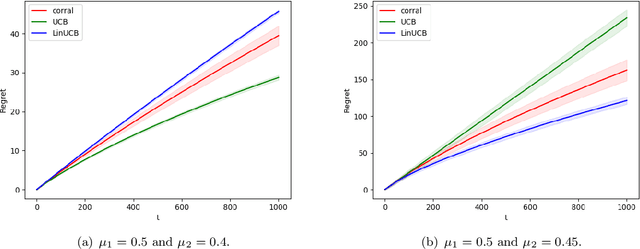
We study model selection in stochastic bandit problems. Our approach relies on a master algorithm that selects its actions among candidate base algorithms. While this problem is studied for specific classes of stochastic base algorithms, our objective is to provide a method that can work with more general classes of stochastic base algorithms. We propose a master algorithm inspired by CORRAL \cite{DBLP:conf/colt/AgarwalLNS17} and introduce a novel and generic smoothing transformation for stochastic bandit algorithms that permits us to obtain $O(\sqrt{T})$ regret guarantees for a wide class of base algorithms when working along with our master. We exhibit a lower bound showing that even when one of the base algorithms has $O(\log T)$ regret, in general it is impossible to get better than $\Omega(\sqrt{T})$ regret in model selection, even asymptotically. We apply our algorithm to choose among different values of $\epsilon$ for the $\epsilon$-greedy algorithm, and to choose between the $k$-armed UCB and linear UCB algorithms. Our empirical studies further confirm the effectiveness of our model-selection method.
Higher-Order Ranking and Link Prediction: From Closing Triangles to Closing Higher-Order Motifs
Jun 12, 2019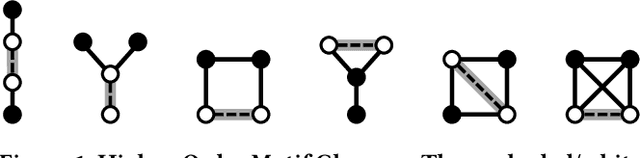
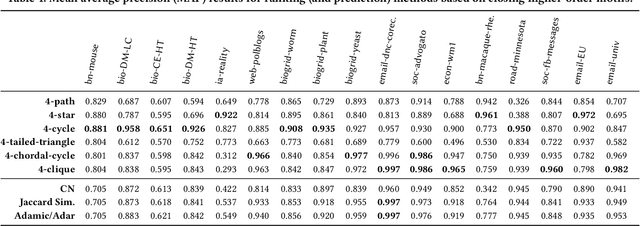
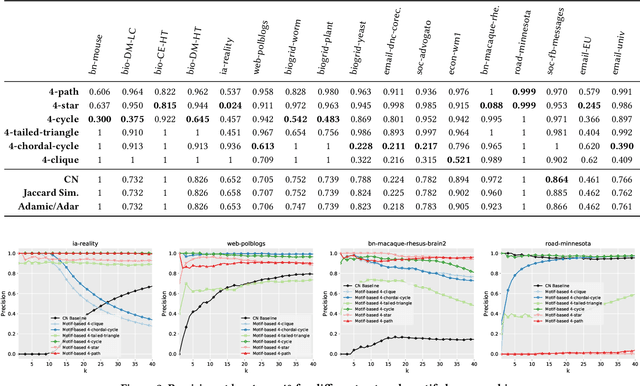
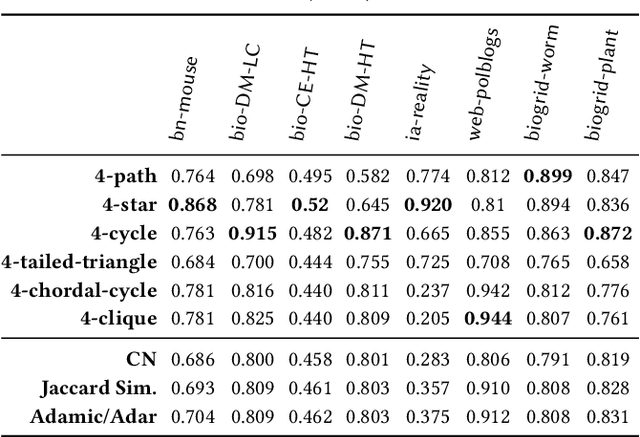
In this paper, we introduce the notion of motif closure and describe higher-order ranking and link prediction methods based on the notion of closing higher-order network motifs. The methods are fast and efficient for real-time ranking and link prediction-based applications such as web search, online advertising, and recommendation. In such applications, real-time performance is critical. The proposed methods do not require any explicit training data, nor do they derive an embedding from the graph data, or perform any explicit learning. Existing methods with the above desired properties are all based on closing triangles (common neighbors, Jaccard similarity, and the ilk). In this work, we investigate higher-order network motifs and develop techniques based on the notion of closing higher-order motifs that move beyond closing simple triangles. All methods described in this work are fast with a runtime that is sublinear in the number of nodes. The experimental results indicate the importance of closing higher-order motifs for ranking and link prediction applications. Finally, the proposed notion of higher-order motif closure can serve as a basis for studying and developing better ranking and link prediction methods.
Heterogeneous Network Motifs
Feb 04, 2019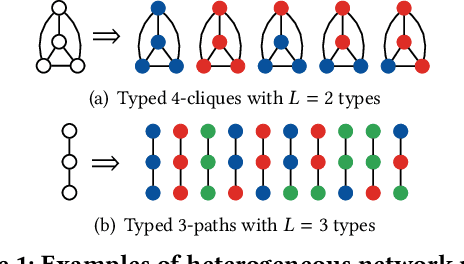

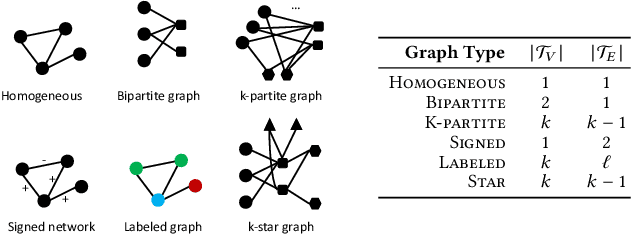
Many real-world applications give rise to large heterogeneous networks where nodes and edges can be of any arbitrary type (e.g., user, web page, location). Special cases of such heterogeneous graphs include homogeneous graphs, bipartite, k-partite, signed, labeled graphs, among many others. In this work, we generalize the notion of network motifs to heterogeneous networks. In particular, small induced typed subgraphs called typed graphlets (heterogeneous network motifs) are introduced and shown to be the fundamental building blocks of complex heterogeneous networks. Typed graphlets are a powerful generalization of the notion of graphlet (network motif) to heterogeneous networks as they capture both the induced subgraph of interest and the types associated with the nodes in the induced subgraph. To address this problem, we propose a fast, parallel, and space-efficient framework for counting typed graphlets in large networks. We discover the existence of non-trivial combinatorial relationships between lower-order ($k-1$)-node typed graphlets and leverage them for deriving many of the $k$-node typed graphlets in $o(1)$ constant time. Thus, we avoid explicit enumeration of those typed graphlets. Notably, the time complexity matches the best untyped graphlet counting algorithm. The experiments demonstrate the effectiveness of the proposed framework in terms of runtime, space-efficiency, parallel speedup, and scalability as it is able to handle large-scale networks.