 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Optimal Hyperparameters for Differentially Private Deep Transfer Learning
Oct 23, 2025Differentially private (DP) transfer learning, i.e., fine-tuning a pretrained model on private data, is the current state-of-the-art approach for training large models under privacy constraints. We focus on two key hyperparameters in this setting: the clipping bound $C$ and batch size $B$. We show a clear mismatch between the current theoretical understanding of how to choose an optimal $C$ (stronger privacy requires smaller $C$) and empirical outcomes (larger $C$ performs better under strong privacy), caused by changes in the gradient distributions. Assuming a limited compute budget (fixed epochs), we demonstrate that the existing heuristics for tuning $B$ do not work, while cumulative DP noise better explains whether smaller or larger batches perform better. We also highlight how the common practice of using a single $(C,B)$ setting across tasks can lead to suboptimal performance. We find that performance drops especially when moving between loose and tight privacy and between plentiful and limited compute, which we explain by analyzing clipping as a form of gradient re-weighting and examining cumulative DP noise.
An Interactive Framework for Finding the Optimal Trade-off in Differential Privacy
Sep 04, 2025



Differential privacy (DP) is the standard for privacy-preserving analysis, and introduces a fundamental trade-off between privacy guarantees and model performance. Selecting the optimal balance is a critical challenge that can be framed as a multi-objective optimization (MOO) problem where one first discovers the set of optimal trade-offs (the Pareto front) and then learns a decision-maker's preference over them. While a rich body of work on interactive MOO exists, the standard approach -- modeling the objective functions with generic surrogates and learning preferences from simple pairwise feedback -- is inefficient for DP because it fails to leverage the problem's unique structure: a point on the Pareto front can be generated directly by maximizing accuracy for a fixed privacy level. Motivated by this property, we first derive the shape of the trade-off theoretically, which allows us to model the Pareto front directly and efficiently. To address inefficiency in preference learning, we replace pairwise comparisons with a more informative interaction. In particular, we present the user with hypothetical trade-off curves and ask them to pick their preferred trade-off. Our experiments on differentially private logistic regression and deep transfer learning across six real-world datasets show that our method converges to the optimal privacy-accuracy trade-off with significantly less computational cost and user interaction than baselines.
$(\varepsilon, δ)$ Considered Harmful: Best Practices for Reporting Differential Privacy Guarantees
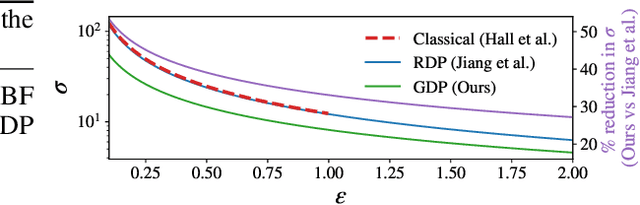
Mar 13, 2025Current practices for reporting the level of differential privacy (DP) guarantees for machine learning (ML) algorithms provide an incomplete and potentially misleading picture of the guarantees and make it difficult to compare privacy levels across different settings. We argue for using Gaussian differential privacy (GDP) as the primary means of communicating DP guarantees in ML, with the full privacy profile as a secondary option in case GDP is too inaccurate. Unlike other widely used alternatives, GDP has only one parameter, which ensures easy comparability of guarantees, and it can accurately capture the full privacy profile of many important ML applications. To support our claims, we investigate the privacy profiles of state-of-the-art DP large-scale image classification, and the TopDown algorithm for the U.S. Decennial Census, observing that GDP fits the profiles remarkably well in all three cases. Although GDP is ideal for reporting the final guarantees, other formalisms (e.g., privacy loss random variables) are needed for accurate privacy accounting. We show that such intermediate representations can be efficiently converted to GDP with minimal loss in tightness.
Hyperparameters in Score-Based Membership Inference Attacks
Feb 10, 2025



Membership Inference Attacks (MIAs) have emerged as a valuable framework for evaluating privacy leakage by machine learning models. Score-based MIAs are distinguished, in particular, by their ability to exploit the confidence scores that the model generates for particular inputs. Existing score-based MIAs implicitly assume that the adversary has access to the target model's hyperparameters, which can be used to train the shadow models for the attack. In this work, we demonstrate that the knowledge of target hyperparameters is not a prerequisite for MIA in the transfer learning setting. Based on this, we propose a novel approach to select the hyperparameters for training the shadow models for MIA when the attacker has no prior knowledge about them by matching the output distributions of target and shadow models. We demonstrate that using the new approach yields hyperparameters that lead to an attack near indistinguishable in performance from an attack that uses target hyperparameters to train the shadow models. Furthermore, we study the empirical privacy risk of unaccounted use of training data for hyperparameter optimization (HPO) in differentially private (DP) transfer learning. We find no statistically significant evidence that performing HPO using training data would increase vulnerability to MIA.
NeurIPS 2023 Competition: Privacy Preserving Federated Learning Document VQA
Nov 06, 2024



The Privacy Preserving Federated Learning Document VQA (PFL-DocVQA) competition challenged the community to develop provably private and communication-efficient solutions in a federated setting for a real-life use case: invoice processing. The competition introduced a dataset of real invoice documents, along with associated questions and answers requiring information extraction and reasoning over the document images. Thereby, it brings together researchers and expertise from the document analysis, privacy, and federated learning communities. Participants fine-tuned a pre-trained, state-of-the-art Document Visual Question Answering model provided by the organizers for this new domain, mimicking a typical federated invoice processing setup. The base model is a multi-modal generative language model, and sensitive information could be exposed through either the visual or textual input modality. Participants proposed elegant solutions to reduce communication costs while maintaining a minimum utility threshold in track 1 and to protect all information from each document provider using differential privacy in track 2. The competition served as a new testbed for developing and testing private federated learning methods, simultaneously raising awareness about privacy within the document image analysis and recognition community. Ultimately, the competition analysis provides best practices and recommendations for successfully running privacy-focused federated learning challenges in the future.
Noise-Aware Differentially Private Variational Inference
Oct 25, 2024



Differential privacy (DP) provides robust privacy guarantees for statistical inference, but this can lead to unreliable results and biases in downstream applications. While several noise-aware approaches have been proposed which integrate DP perturbation into the inference, they are limited to specific types of simple probabilistic models. In this work, we propose a novel method for noise-aware approximate Bayesian inference based on stochastic gradient variational inference which can also be applied to high-dimensional and non-conjugate models. We also propose a more accurate evaluation method for noise-aware posteriors. Empirically, our inference method has similar performance to existing methods in the domain where they are applicable. Outside this domain, we obtain accurate coverages on high-dimensional Bayesian linear regression and well-calibrated predictive probabilities on Bayesian logistic regression with the UCI Adult dataset.
Towards Efficient and Scalable Training of Differentially Private Deep Learning
Jun 25, 2024



Differentially private stochastic gradient descent (DP-SGD) is the standard algorithm for training machine learning models under differential privacy (DP). The major drawback of DP-SGD is the drop in utility which prior work has comprehensively studied. However, in practice another major drawback that hinders the large-scale deployment is the significantly higher computational cost. We conduct a comprehensive empirical study to quantify the computational cost of training deep learning models under DP and benchmark methods that aim at reducing the cost. Among these are more efficient implementations of DP-SGD and training with lower precision. Finally, we study the scaling behaviour using up to 80 GPUs.
Noise-Aware Differentially Private Regression via Meta-Learning
Jun 12, 2024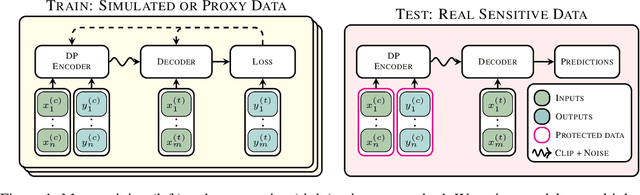
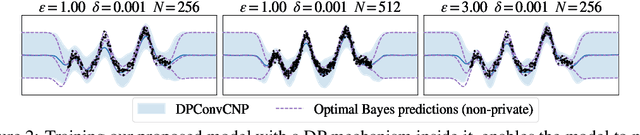

Many high-stakes applications require machine learning models that protect user privacy and provide well-calibrated, accurate predictions. While Differential Privacy (DP) is the gold standard for protecting user privacy, standard DP mechanisms typically significantly impair performance. One approach to mitigating this issue is pre-training models on simulated data before DP learning on the private data. In this work we go a step further, using simulated data to train a meta-learning model that combines the Convolutional Conditional Neural Process (ConvCNP) with an improved functional DP mechanism of Hall et al. [2013] yielding the DPConvCNP. DPConvCNP learns from simulated data how to map private data to a DP predictive model in one forward pass, and then provides accurate, well-calibrated predictions. We compare DPConvCNP with a DP Gaussian Process (GP) baseline with carefully tuned hyperparameters. The DPConvCNP outperforms the GP baseline, especially on non-Gaussian data, yet is much faster at test time and requires less tuning.
Understanding Practical Membership Privacy of Deep Learning
Feb 07, 2024



We apply a state-of-the-art membership inference attack (MIA) to systematically test the practical privacy vulnerability of fine-tuning large image classification models.We focus on understanding the properties of data sets and samples that make them vulnerable to membership inference. In terms of data set properties, we find a strong power law dependence between the number of examples per class in the data and the MIA vulnerability, as measured by true positive rate of the attack at a low false positive rate. For an individual sample, large gradients at the end of training are strongly correlated with MIA vulnerability.
A Bias-Variance Decomposition for Ensembles over Multiple Synthetic Datasets
Feb 06, 2024



Recent studies have highlighted the benefits of generating multiple synthetic datasets for supervised learning, from increased accuracy to more effective model selection and uncertainty estimation. These benefits have clear empirical support, but the theoretical understanding of them is currently very light. We seek to increase the theoretical understanding by deriving bias-variance decompositions for several settings of using multiple synthetic datasets. Our theory predicts multiple synthetic datasets to be especially beneficial for high-variance downstream predictors, and yields a simple rule of thumb to select the appropriate number of synthetic datasets in the case of mean-squared error and Brier score. We investigate how our theory works in practice by evaluating the performance of an ensemble over many synthetic datasets for several real datasets and downstream predictors. The results follow our theory, showing that our insights are also practically relevant.