 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStep-resolved data attribution for looped transformers
Feb 10, 2026We study how individual training examples shape the internal computation of looped transformers, where a shared block is applied for $τ$ recurrent iterations to enable latent reasoning. Existing training-data influence estimators such as TracIn yield a single scalar score that aggregates over all loop iterations, obscuring when during the recurrent computation a training example matters. We introduce \textit{Step-Decomposed Influence (SDI)}, which decomposes TracIn into a length-$τ$ influence trajectory by unrolling the recurrent computation graph and attributing influence to specific loop iterations. To make SDI practical at transformer scale, we propose a TensorSketch implementation that never materialises per-example gradients. Experiments on looped GPT-style models and algorithmic reasoning tasks show that SDI scales excellently, matches full-gradient baselines with low error and supports a broad range of data attribution and interpretability tasks with per-step insights into the latent reasoning process.
Unifying Re-Identification, Attribute Inference, and Data Reconstruction Risks in Differential Privacy
Jul 09, 2025Differentially private (DP) mechanisms are difficult to interpret and calibrate because existing methods for mapping standard privacy parameters to concrete privacy risks -- re-identification, attribute inference, and data reconstruction -- are both overly pessimistic and inconsistent. In this work, we use the hypothesis-testing interpretation of DP ($f$-DP), and determine that bounds on attack success can take the same unified form across re-identification, attribute inference, and data reconstruction risks. Our unified bounds are (1) consistent across a multitude of attack settings, and (2) tunable, enabling practitioners to evaluate risk with respect to arbitrary (including worst-case) levels of baseline risk. Empirically, our results are tighter than prior methods using $\varepsilon$-DP, R\'enyi DP, and concentrated DP. As a result, calibrating noise using our bounds can reduce the required noise by 20% at the same risk level, which yields, e.g., more than 15pp accuracy increase in a text classification task. Overall, this unifying perspective provides a principled framework for interpreting and calibrating the degree of protection in DP against specific levels of re-identification, attribute inference, or data reconstruction risk.
$(\varepsilon, δ)$ Considered Harmful: Best Practices for Reporting Differential Privacy Guarantees
Mar 13, 2025Current practices for reporting the level of differential privacy (DP) guarantees for machine learning (ML) algorithms provide an incomplete and potentially misleading picture of the guarantees and make it difficult to compare privacy levels across different settings. We argue for using Gaussian differential privacy (GDP) as the primary means of communicating DP guarantees in ML, with the full privacy profile as a secondary option in case GDP is too inaccurate. Unlike other widely used alternatives, GDP has only one parameter, which ensures easy comparability of guarantees, and it can accurately capture the full privacy profile of many important ML applications. To support our claims, we investigate the privacy profiles of state-of-the-art DP large-scale image classification, and the TopDown algorithm for the U.S. Decennial Census, observing that GDP fits the profiles remarkably well in all three cases. Although GDP is ideal for reporting the final guarantees, other formalisms (e.g., privacy loss random variables) are needed for accurate privacy accounting. We show that such intermediate representations can be efficiently converted to GDP with minimal loss in tightness.
Attack-Aware Noise Calibration for Differential Privacy
Jul 02, 2024Differential privacy (DP) is a widely used approach for mitigating privacy risks when training machine learning models on sensitive data. DP mechanisms add noise during training to limit the risk of information leakage. The scale of the added noise is critical, as it determines the trade-off between privacy and utility. The standard practice is to select the noise scale in terms of a privacy budget parameter $\epsilon$. This parameter is in turn interpreted in terms of operational attack risk, such as accuracy, or sensitivity and specificity of inference attacks against the privacy of the data. We demonstrate that this two-step procedure of first calibrating the noise scale to a privacy budget $\epsilon$, and then translating $\epsilon$ to attack risk leads to overly conservative risk assessments and unnecessarily low utility. We propose methods to directly calibrate the noise scale to a desired attack risk level, bypassing the intermediate step of choosing $\epsilon$. For a target attack risk, our approach significantly decreases noise scale, leading to increased utility at the same level of privacy. We empirically demonstrate that calibrating noise to attack sensitivity/specificity, rather than $\epsilon$, when training privacy-preserving ML models substantially improves model accuracy for the same risk level. Our work provides a principled and practical way to improve the utility of privacy-preserving ML without compromising on privacy.
Algorithmic Arbitrariness in Content Moderation
Feb 26, 2024



Machine learning (ML) is widely used to moderate online content. Despite its scalability relative to human moderation, the use of ML introduces unique challenges to content moderation. One such challenge is predictive multiplicity: multiple competing models for content classification may perform equally well on average, yet assign conflicting predictions to the same content. This multiplicity can result from seemingly innocuous choices during model development, such as random seed selection for parameter initialization. We experimentally demonstrate how content moderation tools can arbitrarily classify samples as toxic, leading to arbitrary restrictions on speech. We discuss these findings in terms of human rights set out by the International Covenant on Civil and Political Rights (ICCPR), namely freedom of expression, non-discrimination, and procedural justice. We analyze (i) the extent of predictive multiplicity among state-of-the-art LLMs used for detecting toxic content; (ii) the disparate impact of this arbitrariness across social groups; and (iii) how model multiplicity compares to unambiguous human classifications. Our findings indicate that the up-scaled algorithmic moderation risks legitimizing an algorithmic leviathan, where an algorithm disproportionately manages human rights. To mitigate such risks, our study underscores the need to identify and increase the transparency of arbitrariness in content moderation applications. Since algorithmic content moderation is being fueled by pressing social concerns, such as disinformation and hate speech, our discussion on harms raises concerns relevant to policy debates. Our findings also contribute to content moderation and intermediary liability laws being discussed and passed in many countries, such as the Digital Services Act in the European Union, the Online Safety Act in the United Kingdom, and the Fake News Bill in Brazil.
The Saddle-Point Accountant for Differential Privacy
Aug 20, 2022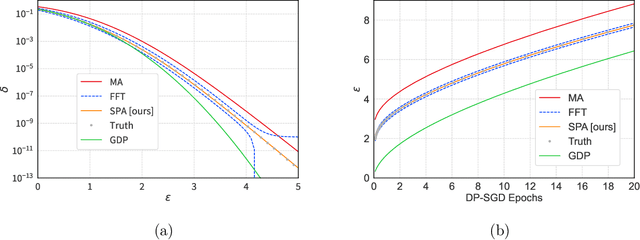
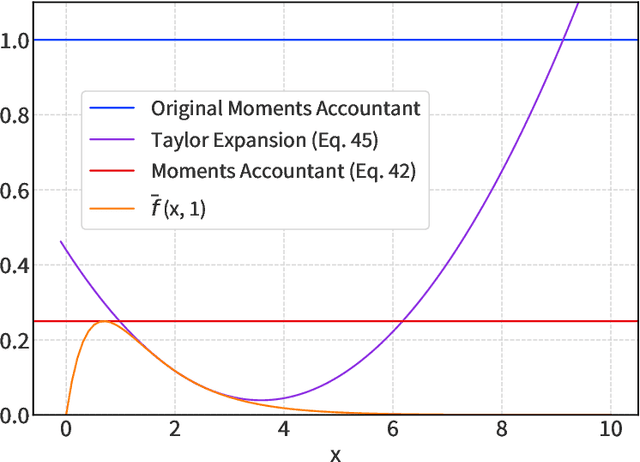
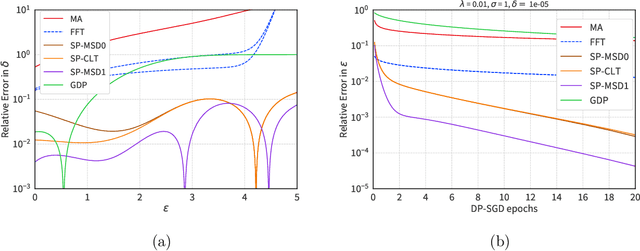
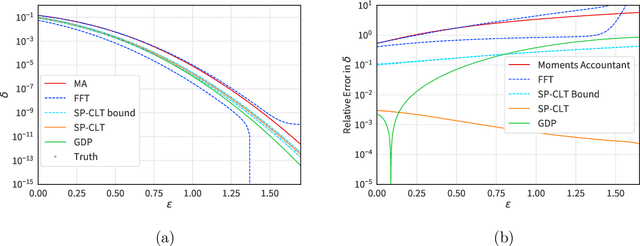
We introduce a new differential privacy (DP) accountant called the saddle-point accountant (SPA). SPA approximates privacy guarantees for the composition of DP mechanisms in an accurate and fast manner. Our approach is inspired by the saddle-point method -- a ubiquitous numerical technique in statistics. We prove rigorous performance guarantees by deriving upper and lower bounds for the approximation error offered by SPA. The crux of SPA is a combination of large-deviation methods with central limit theorems, which we derive via exponentially tilting the privacy loss random variables corresponding to the DP mechanisms. One key advantage of SPA is that it runs in constant time for the $n$-fold composition of a privacy mechanism. Numerical experiments demonstrate that SPA achieves comparable accuracy to state-of-the-art accounting methods with a faster runtime.