 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeApproaches to Corpus Creation for Low-Resource Language Technology: the Case of Southern Kurdish and Laki
Apr 03, 2023One of the major challenges that under-represented and endangered language communities face in language technology is the lack or paucity of language data. This is also the case of the Southern varieties of the Kurdish and Laki languages for which very limited resources are available with insubstantial progress in tools. To tackle this, we provide a few approaches that rely on the content of local news websites, a local radio station that broadcasts content in Southern Kurdish and fieldwork for Laki. In this paper, we describe some of the challenges of such under-represented languages, particularly in writing and standardization, and also, in retrieving sources of data and retro-digitizing handwritten content to create a corpus for Southern Kurdish and Laki. In addition, we study the task of language identification in light of the other variants of Kurdish and Zaza-Gorani languages.
User-Centric Evaluation of OCR Systems for Kwak'wala
Feb 26, 2023



There has been recent interest in improving optical character recognition (OCR) for endangered languages, particularly because a large number of documents and books in these languages are not in machine-readable formats. The performance of OCR systems is typically evaluated using automatic metrics such as character and word error rates. While error rates are useful for the comparison of different models and systems, they do not measure whether and how the transcriptions produced from OCR tools are useful to downstream users. In this paper, we present a human-centric evaluation of OCR systems, focusing on the Kwak'wala language as a case study. With a user study, we show that utilizing OCR reduces the time spent in the manual transcription of culturally valuable documents -- a task that is often undertaken by endangered language community members and researchers -- by over 50%. Our results demonstrate the potential benefits that OCR tools can have on downstream language documentation and revitalization efforts.
Noisy Parallel Data Alignment
Jan 23, 2023



An ongoing challenge in current natural language processing is how its major advancements tend to disproportionately favor resource-rich languages, leaving a significant number of under-resourced languages behind. Due to the lack of resources required to train and evaluate models, most modern language technologies are either nonexistent or unreliable to process endangered, local, and non-standardized languages. Optical character recognition (OCR) is often used to convert endangered language documents into machine-readable data. However, such OCR output is typically noisy, and most word alignment models are not built to work under such noisy conditions. In this work, we study the existing word-level alignment models under noisy settings and aim to make them more robust to noisy data. Our noise simulation and structural biasing method, tested on multiple language pairs, manages to reduce the alignment error rate on a state-of-the-art neural-based alignment model up to 59.6%.
Geographic and Geopolitical Biases of Language Models
Dec 20, 2022



Pretrained language models (PLMs) often fail to fairly represent target users from certain world regions because of the under-representation of those regions in training datasets. With recent PLMs trained on enormous data sources, quantifying their potential biases is difficult, due to their black-box nature and the sheer scale of the data sources. In this work, we devise an approach to study the geographic bias (and knowledge) present in PLMs, proposing a Geographic-Representation Probing Framework adopting a self-conditioning method coupled with entity-country mappings. Our findings suggest PLMs' representations map surprisingly well to the physical world in terms of country-to-country associations, but this knowledge is unequally shared across languages. Last, we explain how large PLMs despite exhibiting notions of geographical proximity, over-amplify geopolitical favouritism at inference time.
Language Generation Models Can Cause Harm: So What Can We Do About It? An Actionable Survey
Oct 14, 2022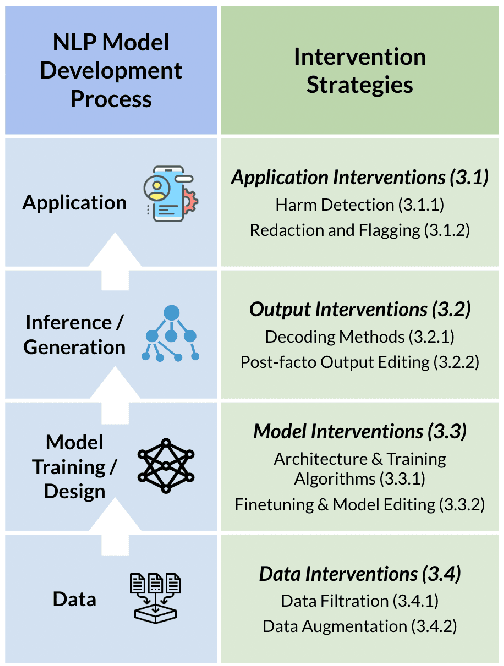
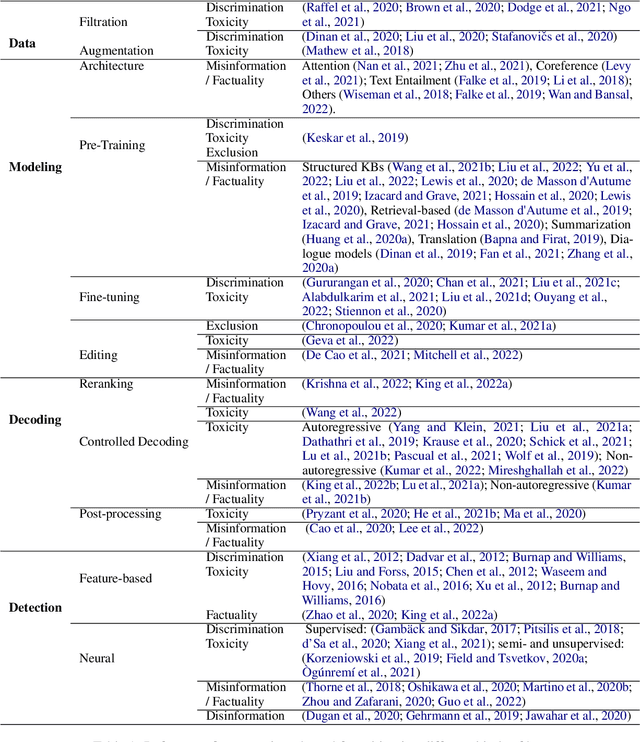
Recent advances in the capacity of large language models to generate human-like text have resulted in their increased adoption in user-facing settings. In parallel, these improvements have prompted a heated discourse around the risks of societal harms they introduce, whether inadvertent or malicious. Several studies have identified potential causes of these harms and called for their mitigation via development of safer and fairer models. Going beyond enumerating the risks of harms, this work provides a survey of practical methods for addressing potential threats and societal harms from language generation models. We draw on several prior works' taxonomies of language model risks to present a structured overview of strategies for detecting and ameliorating different kinds of risks/harms of language generators. Bridging diverse strands of research, this survey aims to serve as a practical guide for both LM researchers and practitioners with explanations of motivations behind different mitigation strategies, their limitations, and open problems for future research.
Phylogeny-Inspired Adaptation of Multilingual Models to New Languages
May 19, 2022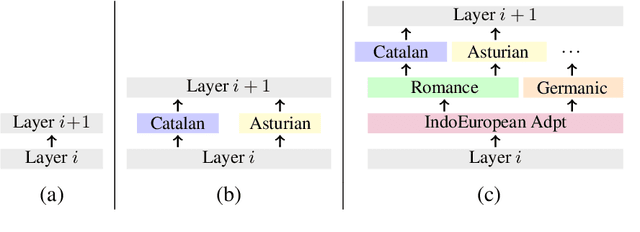
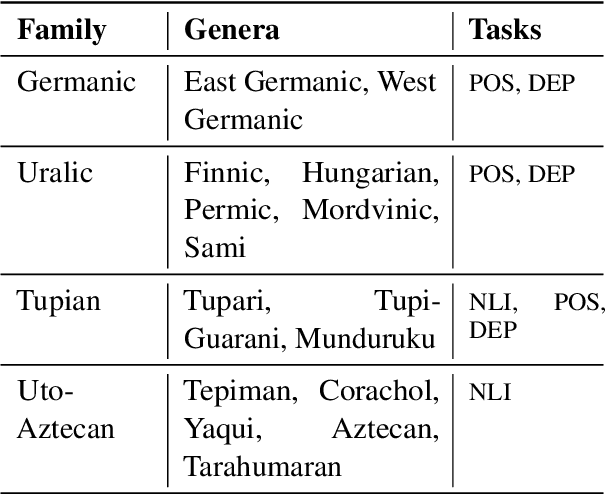
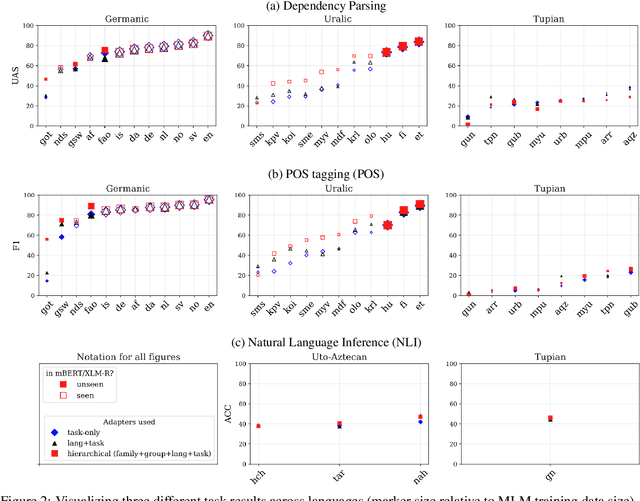
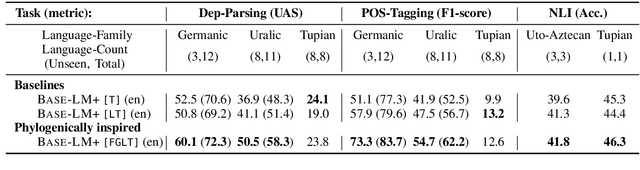
Large pretrained multilingual models, trained on dozens of languages, have delivered promising results due to cross-lingual learning capabilities on variety of language tasks. Further adapting these models to specific languages, especially ones unseen during pre-training, is an important goal towards expanding the coverage of language technologies. In this study, we show how we can use language phylogenetic information to improve cross-lingual transfer leveraging closely related languages in a structured, linguistically-informed manner. We perform adapter-based training on languages from diverse language families (Germanic, Uralic, Tupian, Uto-Aztecan) and evaluate on both syntactic and semantic tasks, obtaining more than 20% relative performance improvements over strong commonly used baselines, especially on languages unseen during pre-training.
Educational Tools for Mapuzugun
May 19, 2022

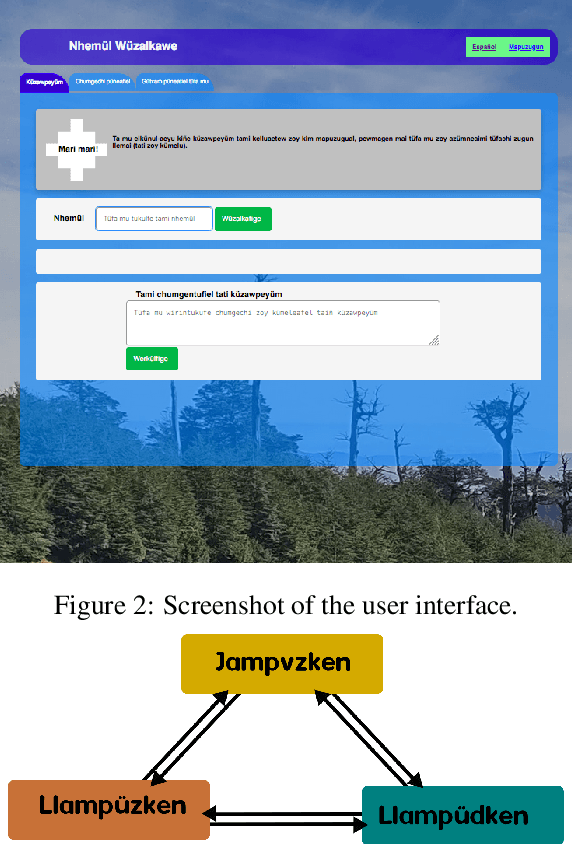
Mapuzugun is the language of the Mapuche people. Due to political and historical reasons, its number of speakers has decreased and the language has been excluded from the educational system in Chile and Argentina. For this reason, it is very important to support the revitalization of the Mapuzugun in all spaces and media of society. In this work we present a tool towards supporting educational activities of Mapuzugun, tailored to the characteristics of the language. The tool consists of three parts: design and development of an orthography detector and converter; a morphological analyzer; and an informal translator. We also present a case study with Mapuzugun students showing promising results. Short Abstract in Mapuzuzgun: T\"ufachi k\"uzaw pegelfi ki\~ne zugun k\"uzawpey\"um kelluaetew pu mapuzugun chillkatufe kimal kizu ta\~ni zugun.
UniMorph 4.0: Universal Morphology
May 10, 2022



The Universal Morphology (UniMorph) project is a collaborative effort providing broad-coverage instantiated normalized morphological inflection tables for hundreds of diverse world languages. The project comprises two major thrusts: a language-independent feature schema for rich morphological annotation and a type-level resource of annotated data in diverse languages realizing that schema. This paper presents the expansions and improvements made on several fronts over the last couple of years (since McCarthy et al. (2020)). Collaborative efforts by numerous linguists have added 67 new languages, including 30 endangered languages. We have implemented several improvements to the extraction pipeline to tackle some issues, e.g. missing gender and macron information. We have also amended the schema to use a hierarchical structure that is needed for morphological phenomena like multiple-argument agreement and case stacking, while adding some missing morphological features to make the schema more inclusive. In light of the last UniMorph release, we also augmented the database with morpheme segmentation for 16 languages. Lastly, this new release makes a push towards inclusion of derivational morphology in UniMorph by enriching the data and annotation schema with instances representing derivational processes from MorphyNet.
AUTOLEX: An Automatic Framework for Linguistic Exploration
Mar 25, 2022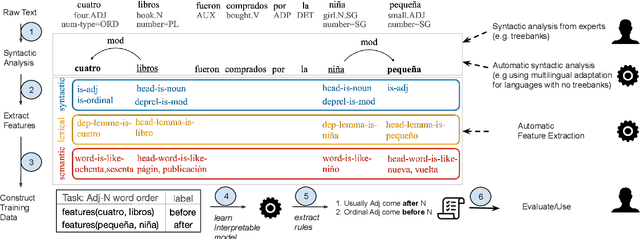
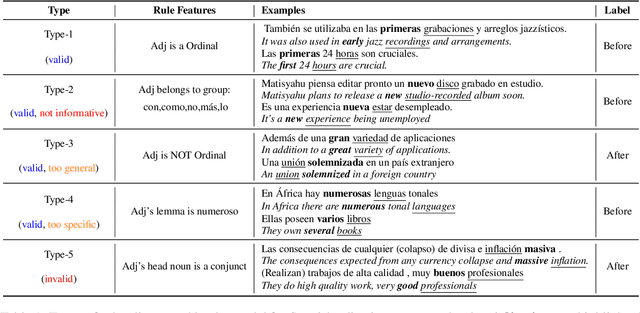
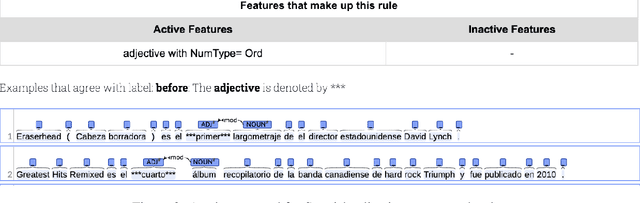
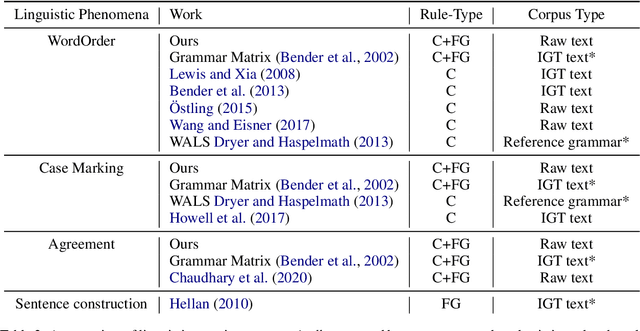
Each language has its own complex systems of word, phrase, and sentence construction, the guiding principles of which are often summarized in grammar descriptions for the consumption of linguists or language learners. However, manual creation of such descriptions is a fraught process, as creating descriptions which describe the language in "its own terms" without bias or error requires both a deep understanding of the language at hand and linguistics as a whole. We propose an automatic framework AutoLEX that aims to ease linguists' discovery and extraction of concise descriptions of linguistic phenomena. Specifically, we apply this framework to extract descriptions for three phenomena: morphological agreement, case marking, and word order, across several languages. We evaluate the descriptions with the help of language experts and propose a method for automated evaluation when human evaluation is infeasible.
Revisiting the Effects of Leakage on Dependency Parsing
Mar 24, 2022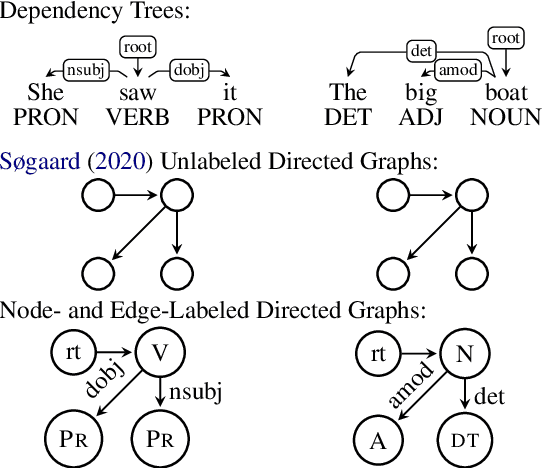
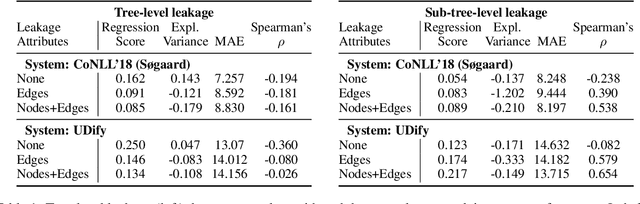

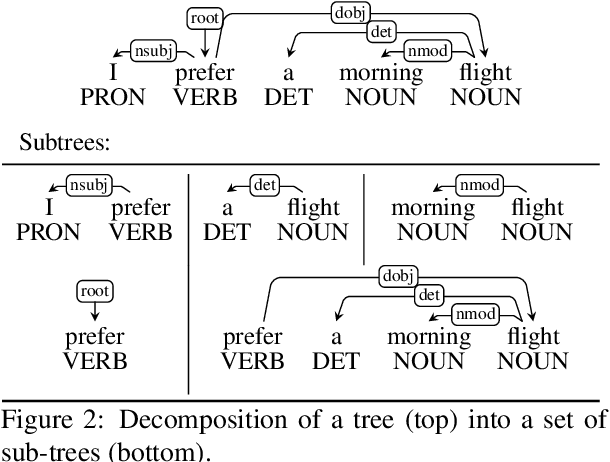
Recent work by S{\o}gaard (2020) showed that, treebank size aside, overlap between training and test graphs (termed leakage) explains more of the observed variation in dependency parsing performance than other explanations. In this work we revisit this claim, testing it on more models and languages. We find that it only holds for zero-shot cross-lingual settings. We then propose a more fine-grained measure of such leakage which, unlike the original measure, not only explains but also correlates with observed performance variation. Code and data are available here: https://github.com/miriamwanner/reu-nlp-project