 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Fixed-Point Approach to Unified Prompt-Based Counting
Mar 15, 2024



Existing class-agnostic counting models typically rely on a single type of prompt, e.g., box annotations. This paper aims to establish a comprehensive prompt-based counting framework capable of generating density maps for concerned objects indicated by various prompt types, such as box, point, and text. To achieve this goal, we begin by converting prompts from different modalities into prompt masks without requiring training. These masks are then integrated into a class-agnostic counting methodology for predicting density maps. Furthermore, we introduce a fixed-point inference along with an associated loss function to improve counting accuracy, all without introducing new parameters. The effectiveness of this method is substantiated both theoretically and experimentally. Additionally, a contrastive training scheme is implemented to mitigate dataset bias inherent in current class-agnostic counting datasets, a strategy whose effectiveness is confirmed by our ablation study. Our model excels in prominent class-agnostic datasets and exhibits superior performance in cross-dataset adaptation tasks.
Robust Unsupervised Crowd Counting and Localization with Adaptive Resolution SAM
Feb 27, 2024



The existing crowd counting models require extensive training data, which is time-consuming to annotate. To tackle this issue, we propose a simple yet effective crowd counting method by utilizing the Segment-Everything-Everywhere Model (SEEM), an adaptation of the Segmentation Anything Model (SAM), to generate pseudo-labels for training crowd counting models. However, our initial investigation reveals that SEEM's performance in dense crowd scenes is limited, primarily due to the omission of many persons in high-density areas. To overcome this limitation, we propose an adaptive resolution SEEM to handle the scale variations, occlusions, and overlapping of people within crowd scenes. Alongside this, we introduce a robust localization method, based on Gaussian Mixture Models, for predicting the head positions in the predicted people masks. Given the mask and point pseudo-labels, we propose a robust loss function, which is designed to exclude uncertain regions based on SEEM's predictions, thereby enhancing the training process of the counting networks. Finally, we propose an iterative method for generating pseudo-labels. This method aims at improving the quality of the segmentation masks by identifying more tiny persons in high-density regions, which are often missed in the first pseudo-labeling stage. Overall, our proposed method achieves the best unsupervised performance in crowd counting, while also being comparable results to some supervised methods. This makes it a highly effective and versatile tool for crowd counting, especially in situations where labeled data is not available.
Human Attention-Guided Explainable Artificial Intelligence for Computer Vision Models
May 05, 2023We examined whether embedding human attention knowledge into saliency-based explainable AI (XAI) methods for computer vision models could enhance their plausibility and faithfulness. We first developed new gradient-based XAI methods for object detection models to generate object-specific explanations by extending the current methods for image classification models. Interestingly, while these gradient-based methods worked well for explaining image classification models, when being used for explaining object detection models, the resulting saliency maps generally had lower faithfulness than human attention maps when performing the same task. We then developed Human Attention-Guided XAI (HAG-XAI) to learn from human attention how to best combine explanatory information from the models to enhance explanation plausibility by using trainable activation functions and smoothing kernels to maximize XAI saliency map's similarity to human attention maps. While for image classification models, HAG-XAI enhanced explanation plausibility at the expense of faithfulness, for object detection models it enhanced plausibility and faithfulness simultaneously and outperformed existing methods. The learned functions were model-specific, well generalizable to other databases.
ODAM: Gradient-based instance-specific visual explanations for object detection
Apr 13, 2023We propose the gradient-weighted Object Detector Activation Maps (ODAM), a visualized explanation technique for interpreting the predictions of object detectors. Utilizing the gradients of detector targets flowing into the intermediate feature maps, ODAM produces heat maps that show the influence of regions on the detector's decision for each predicted attribute. Compared to previous works classification activation maps (CAM), ODAM generates instance-specific explanations rather than class-specific ones. We show that ODAM is applicable to both one-stage detectors and two-stage detectors with different types of detector backbones and heads, and produces higher-quality visual explanations than the state-of-the-art both effectively and efficiently. We next propose a training scheme, Odam-Train, to improve the explanation ability on object discrimination of the detector through encouraging consistency between explanations for detections on the same object, and distinct explanations for detections on different objects. Based on the heat maps produced by ODAM with Odam-Train, we propose Odam-NMS, which considers the information of the model's explanation for each prediction to distinguish the duplicate detected objects. We present a detailed analysis of the visualized explanations of detectors and carry out extensive experiments to validate the effectiveness of the proposed ODAM.
DropMAE: Masked Autoencoders with Spatial-Attention Dropout for Tracking Tasks
Apr 07, 2023In this paper, we study masked autoencoder (MAE) pretraining on videos for matching-based downstream tasks, including visual object tracking (VOT) and video object segmentation (VOS). A simple extension of MAE is to randomly mask out frame patches in videos and reconstruct the frame pixels. However, we find that this simple baseline heavily relies on spatial cues while ignoring temporal relations for frame reconstruction, thus leading to sub-optimal temporal matching representations for VOT and VOS. To alleviate this problem, we propose DropMAE, which adaptively performs spatial-attention dropout in the frame reconstruction to facilitate temporal correspondence learning in videos. We show that our DropMAE is a strong and efficient temporal matching learner, which achieves better finetuning results on matching-based tasks than the ImageNetbased MAE with 2X faster pre-training speed. Moreover, we also find that motion diversity in pre-training videos is more important than scene diversity for improving the performance on VOT and VOS. Our pre-trained DropMAE model can be directly loaded in existing ViT-based trackers for fine-tuning without further modifications. Notably, DropMAE sets new state-of-the-art performance on 8 out of 9 highly competitive video tracking and segmentation datasets. Our code and pre-trained models are available at https://github.com/jimmy-dq/DropMAE.git.
TWINS: A Fine-Tuning Framework for Improved Transferability of Adversarial Robustness and Generalization
Mar 20, 2023Recent years have seen the ever-increasing importance of pre-trained models and their downstream training in deep learning research and applications. At the same time, the defense for adversarial examples has been mainly investigated in the context of training from random initialization on simple classification tasks. To better exploit the potential of pre-trained models in adversarial robustness, this paper focuses on the fine-tuning of an adversarially pre-trained model in various classification tasks. Existing research has shown that since the robust pre-trained model has already learned a robust feature extractor, the crucial question is how to maintain the robustness in the pre-trained model when learning the downstream task. We study the model-based and data-based approaches for this goal and find that the two common approaches cannot achieve the objective of improving both generalization and adversarial robustness. Thus, we propose a novel statistics-based approach, Two-WIng NormliSation (TWINS) fine-tuning framework, which consists of two neural networks where one of them keeps the population means and variances of pre-training data in the batch normalization layers. Besides the robust information transfer, TWINS increases the effective learning rate without hurting the training stability since the relationship between a weight norm and its gradient norm in standard batch normalization layer is broken, resulting in a faster escape from the sub-optimal initialization and alleviating the robust overfitting. Finally, TWINS is shown to be effective on a wide range of image classification datasets in terms of both generalization and robustness. Our code is available at https://github.com/ziquanliu/CVPR2023-TWINS.
Boosting Adversarial Robustness From The Perspective of Effective Margin Regularization
Oct 11, 2022
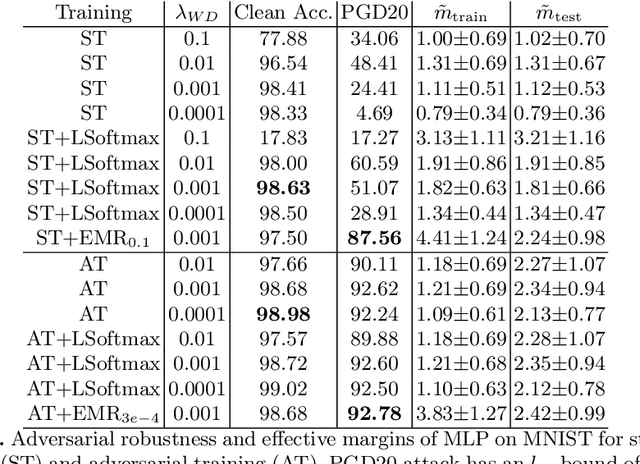
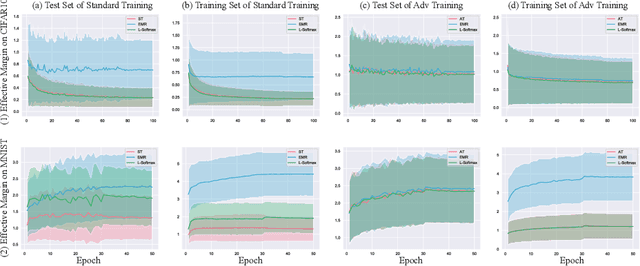
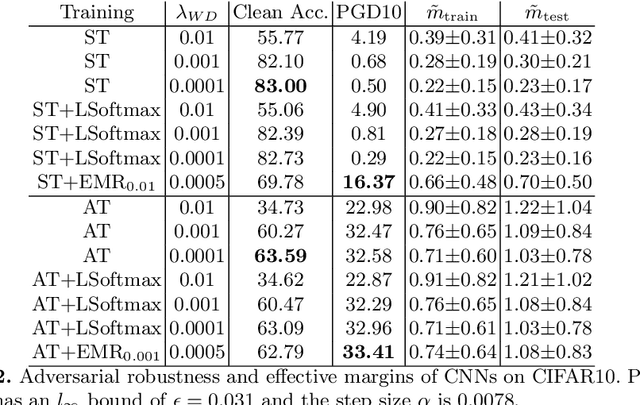
The adversarial vulnerability of deep neural networks (DNNs) has been actively investigated in the past several years. This paper investigates the scale-variant property of cross-entropy loss, which is the most commonly used loss function in classification tasks, and its impact on the effective margin and adversarial robustness of deep neural networks. Since the loss function is not invariant to logit scaling, increasing the effective weight norm will make the loss approach zero and its gradient vanish while the effective margin is not adequately maximized. On typical DNNs, we demonstrate that, if not properly regularized, the standard training does not learn large effective margins and leads to adversarial vulnerability. To maximize the effective margins and learn a robust DNN, we propose to regularize the effective weight norm during training. Our empirical study on feedforward DNNs demonstrates that the proposed effective margin regularization (EMR) learns large effective margins and boosts the adversarial robustness in both standard and adversarial training. On large-scale models, we show that EMR outperforms basic adversarial training, TRADES and two regularization baselines with substantial improvement. Moreover, when combined with several strong adversarial defense methods (MART and MAIL), our EMR further boosts the robustness.
Pareto Optimization for Active Learning under Out-of-Distribution Data Scenarios
Jul 04, 2022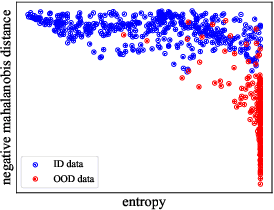
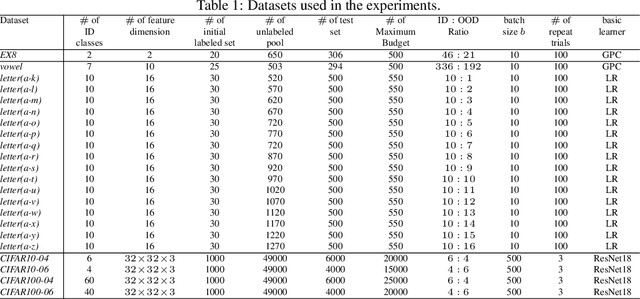
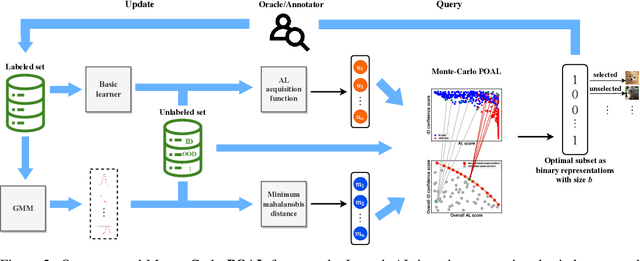
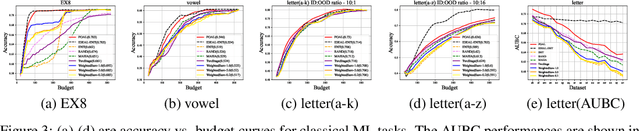
Pool-based Active Learning (AL) has achieved great success in minimizing labeling cost by sequentially selecting informative unlabeled samples from a large unlabeled data pool and querying their labels from oracle/annotators. However, existing AL sampling strategies might not work well in out-of-distribution (OOD) data scenarios, where the unlabeled data pool contains some data samples that do not belong to the classes of the target task. Achieving good AL performance under OOD data scenarios is a challenging task due to the natural conflict between AL sampling strategies and OOD sample detection. AL selects data that are hard to be classified by the current basic classifier (e.g., samples whose predicted class probabilities have high entropy), while OOD samples tend to have more uniform predicted class probabilities (i.e., high entropy) than in-distribution (ID) data. In this paper, we propose a sampling scheme, Monte-Carlo Pareto Optimization for Active Learning (POAL), which selects optimal subsets of unlabeled samples with fixed batch size from the unlabeled data pool. We cast the AL sampling task as a multi-objective optimization problem, and thus we utilize Pareto optimization based on two conflicting objectives: (1) the normal AL data sampling scheme (e.g., maximum entropy), and (2) the confidence of not being an OOD sample. Experimental results show its effectiveness on both classical Machine Learning (ML) and Deep Learning (DL) tasks.
An Empirical Study on Distribution Shift Robustness From the Perspective of Pre-Training and Data Augmentation
May 25, 2022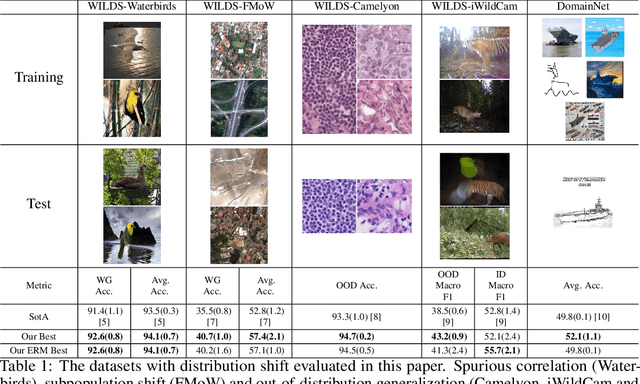
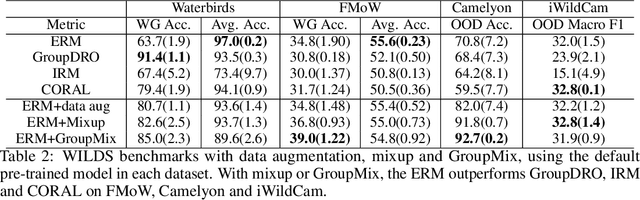
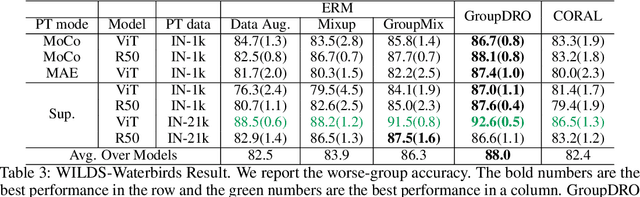
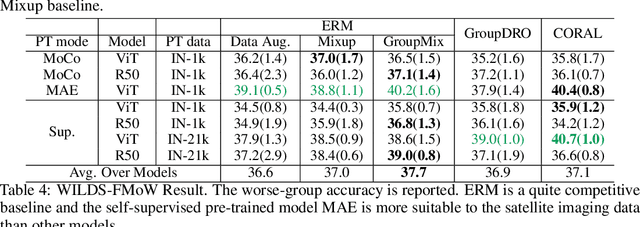
The performance of machine learning models under distribution shift has been the focus of the community in recent years. Most of current methods have been proposed to improve the robustness to distribution shift from the algorithmic perspective, i.e., designing better training algorithms to help the generalization in shifted test distributions. This paper studies the distribution shift problem from the perspective of pre-training and data augmentation, two important factors in the practice of deep learning that have not been systematically investigated by existing work. By evaluating seven pre-trained models, including ResNets and ViT's with self-supervision and supervision mode, on five important distribution-shift datasets, from WILDS and DomainBed benchmarks, with five different learning algorithms, we provide the first comprehensive empirical study focusing on pre-training and data augmentation. With our empirical result obtained from 1,330 models, we provide the following main observations: 1) ERM combined with data augmentation can achieve state-of-the-art performance if we choose a proper pre-trained model respecting the data property; 2) specialized algorithms further improve the robustness on top of ERM when handling a specific type of distribution shift, e.g., GroupDRO for spurious correlation and CORAL for large-scale out-of-distribution data; 3) Comparing different pre-training modes, architectures and data sizes, we provide novel observations about pre-training on distribution shift, which sheds light on designing or selecting pre-training strategy for different kinds of distribution shifts. In summary, our empirical study provides a comprehensive baseline for a wide range of pre-training models fine-tuned with data augmentation, which potentially inspires research exploiting the power of pre-training and data augmentation in the future of distribution shift study.
Cross-View Cross-Scene Multi-View Crowd Counting
May 03, 2022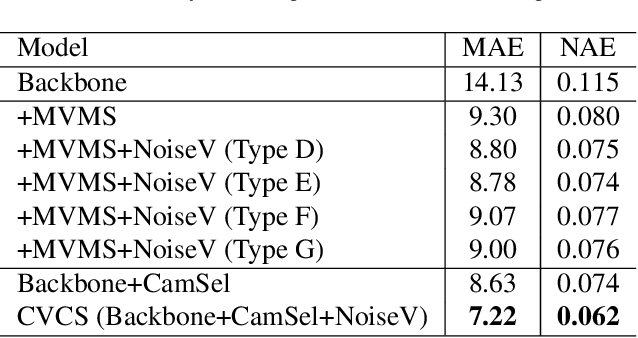
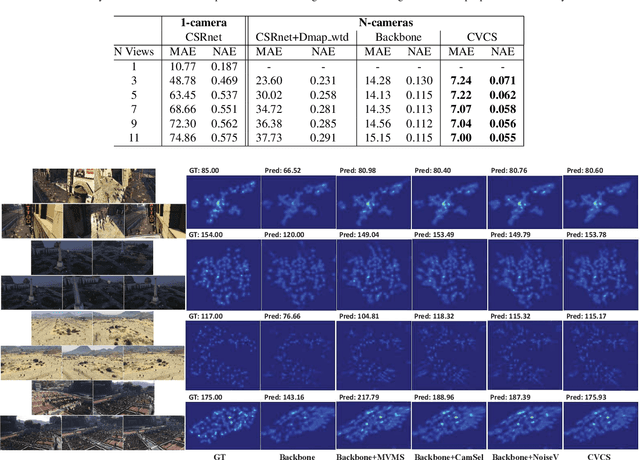

Multi-view crowd counting has been previously proposed to utilize multi-cameras to extend the field-of-view of a single camera, capturing more people in the scene, and improve counting performance for occluded people or those in low resolution. However, the current multi-view paradigm trains and tests on the same single scene and camera-views, which limits its practical application. In this paper, we propose a cross-view cross-scene (CVCS) multi-view crowd counting paradigm, where the training and testing occur on different scenes with arbitrary camera layouts. To dynamically handle the challenge of optimal view fusion under scene and camera layout change and non-correspondence noise due to camera calibration errors or erroneous features, we propose a CVCS model that attentively selects and fuses multiple views together using camera layout geometry, and a noise view regularization method to train the model to handle non-correspondence errors. We also generate a large synthetic multi-camera crowd counting dataset with a large number of scenes and camera views to capture many possible variations, which avoids the difficulty of collecting and annotating such a large real dataset. We then test our trained CVCS model on real multi-view counting datasets, by using unsupervised domain transfer. The proposed CVCS model trained on synthetic data outperforms the same model trained only on real data, and achieves promising performance compared to fully supervised methods that train and test on the same single scene.