 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Diverse and Accurate Image Captions via Reinforcing Determinantal Point Process
Paper and Code
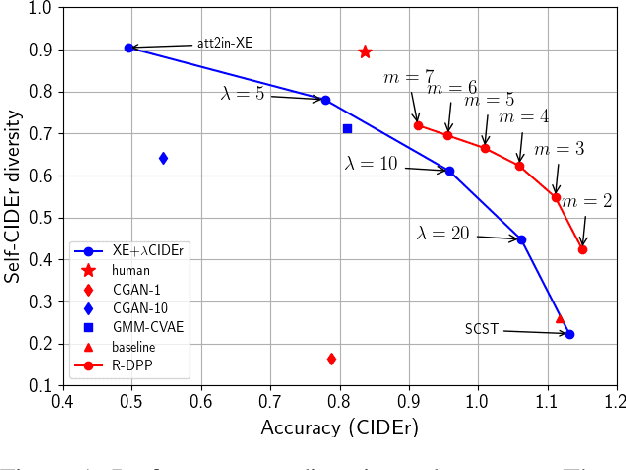
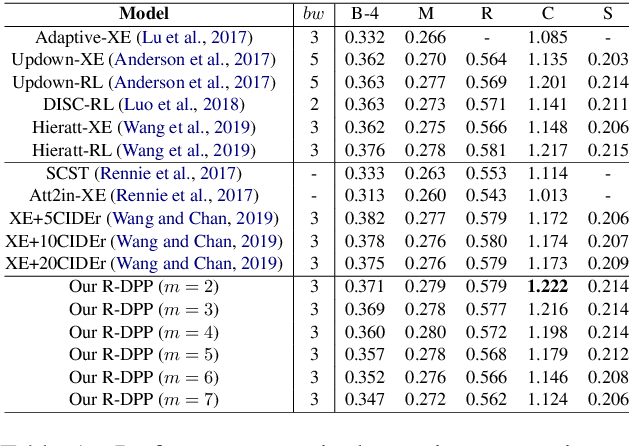
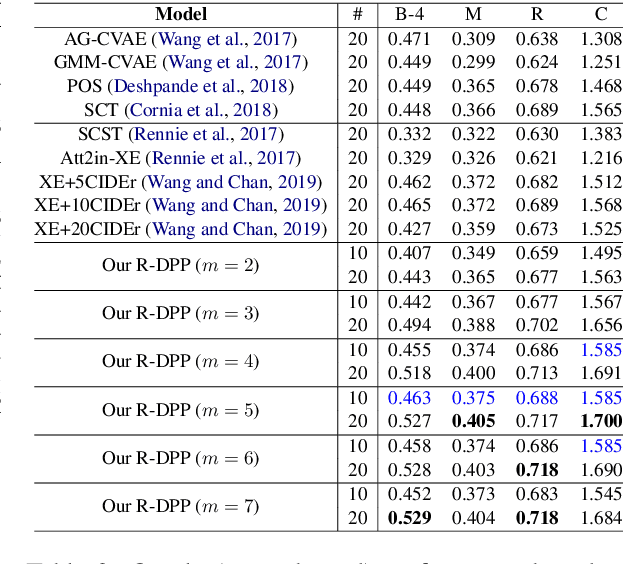

Although significant progress has been made in the field of automatic image captioning, it is still a challenging task. Previous works normally pay much attention to improving the quality of the generated captions but ignore the diversity of captions. In this paper, we combine determinantal point process (DPP) and reinforcement learning (RL) and propose a novel reinforcing DPP (R-DPP) approach to generate a set of captions with high quality and diversity for an image. We show that R-DPP performs better on accuracy and diversity than using noise as a control signal (GANs, VAEs). Moreover, R-DPP is able to preserve the modes of the learned distribution. Hence, beam search algorithm can be applied to generate a single accurate caption, which performs better than other RL-based models.