 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCompare and Reweight: Distinctive Image Captioning Using Similar Images Sets
Paper and Code
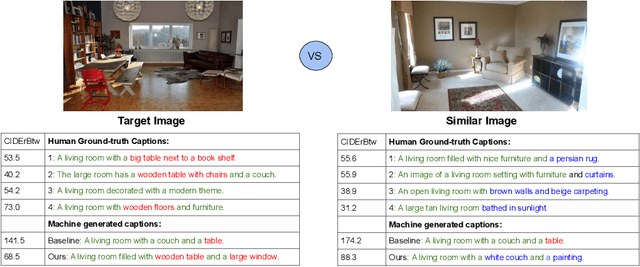
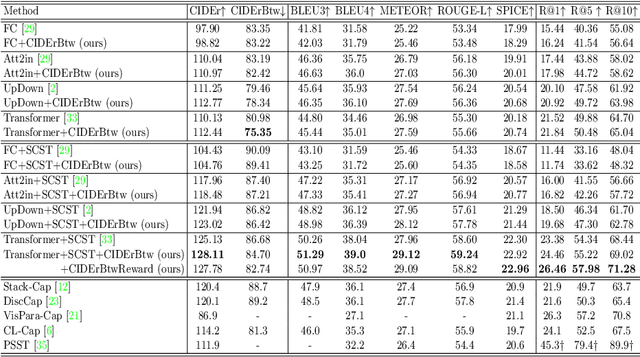
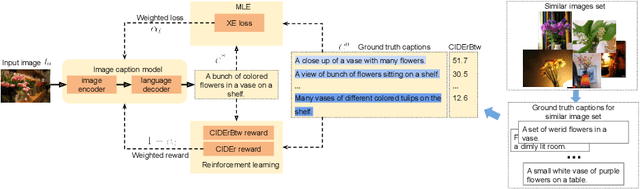
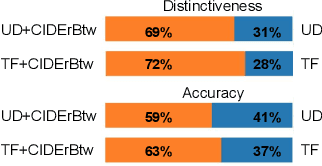
A wide range of image captioning models has been developed, achieving significant improvement based on popular metrics, such as BLEU, CIDEr, and SPICE. However, although the generated captions can accurately describe the image, they are generic for similar images and lack distinctiveness, i.e., cannot properly describe the uniqueness of each image. In this paper, we aim to improve the distinctiveness of image captions through training with sets of similar images. First, we propose a distinctiveness metric -- between-set CIDEr (CIDErBtw) to evaluate the distinctiveness of a caption with respect to those of similar images. Our metric shows that the human annotations of each image are not equivalent based on distinctiveness. Thus we propose several new training strategies to encourage the distinctiveness of the generated caption for each image, which are based on using CIDErBtw in a weighted loss function or as a reinforcement learning reward. Finally, extensive experiments are conducted, showing that our proposed approach significantly improves both distinctiveness (as measured by CIDErBtw and retrieval metrics) and accuracy (e.g., as measured by CIDEr) for a wide variety of image captioning baselines. These results are further confirmed through a user study.