 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSplitLight: An Exploratory Toolkit for Recommender Systems Datasets and Splits
Feb 22, 2026Offline evaluation of recommender systems is often affected by hidden, under-documented choices in data preparation. Seemingly minor decisions in filtering, handling repeats, cold-start treatment, and splitting strategy design can substantially reorder model rankings and undermine reproducibility and cross-paper comparability. In this paper, we introduce SplitLight, an open-source exploratory toolkit that enables researchers and practitioners designing preprocessing and splitting pipelines or reviewing external artifacts to make these decisions measurable, comparable, and reportable. Given an interaction log and derived split subsets, SplitLight analyzes core and temporal dataset statistics, characterizes repeat consumption patterns and timestamp anomalies, and diagnoses split validity, including temporal leakage, cold-user/item exposure, and distribution shifts. SplitLight further allows side-by-side comparison of alternative splitting strategies through comprehensive aggregated summaries and interactive visualizations. Delivered as both a Python toolkit and an interactive no-code interface, SplitLight produces audit summaries that justify evaluation protocols and support transparent, reliable, and comparable experimentation in recommender systems research and industry.
Neural Click Models for Recommender Systems
Sep 30, 2024We develop and evaluate neural architectures to model the user behavior in recommender systems (RS) inspired by click models for Web search but going beyond standard click models. Proposed architectures include recurrent networks, Transformer-based models that alleviate the quadratic complexity of self-attention, adversarial and hierarchical architectures. Our models outperform baselines on the ContentWise and RL4RS datasets and can be used in RS simulators to model user response for RS evaluation and pretraining.
Autoregressive Generation Strategies for Top-K Sequential Recommendations
Sep 26, 2024The goal of modern sequential recommender systems is often formulated in terms of next-item prediction. In this paper, we explore the applicability of generative transformer-based models for the Top-K sequential recommendation task, where the goal is to predict items a user is likely to interact with in the "near future". We explore commonly used autoregressive generation strategies, including greedy decoding, beam search, and temperature sampling, to evaluate their performance for the Top-K sequential recommendation task. In addition, we propose novel Reciprocal Rank Aggregation (RRA) and Relevance Aggregation (RA) generation strategies based on multi-sequence generation with temperature sampling and subsequent aggregation. Experiments on diverse datasets give valuable insights regarding commonly used strategies' applicability and show that suggested approaches improve performance on longer time horizons compared to widely-used Top-K prediction approach and single-sequence autoregressive generation strategies.
RePlay: a Recommendation Framework for Experimentation and Production Use
Sep 11, 2024
Using a single tool to build and compare recommender systems significantly reduces the time to market for new models. In addition, the comparison results when using such tools look more consistent. This is why many different tools and libraries for researchers in the field of recommendations have recently appeared. Unfortunately, most of these frameworks are aimed primarily at researchers and require modification for use in production due to the inability to work on large datasets or an inappropriate architecture. In this demo, we present our open-source toolkit RePlay - a framework containing an end-to-end pipeline for building recommender systems, which is ready for production use. RePlay also allows you to use a suitable stack for the pipeline on each stage: Pandas, Polars, or Spark. This allows the library to scale computations and deploy to a cluster. Thus, RePlay allows data scientists to easily move from research mode to production mode using the same interfaces.
Does It Look Sequential? An Analysis of Datasets for Evaluation of Sequential Recommendations
Aug 21, 2024Sequential recommender systems are an important and demanded area of research. Such systems aim to use the order of interactions in a user's history to predict future interactions. The premise is that the order of interactions and sequential patterns play an essential role. Therefore, it is crucial to use datasets that exhibit a sequential structure to evaluate sequential recommenders properly. We apply several methods based on the random shuffling of the user's sequence of interactions to assess the strength of sequential structure across 15 datasets, frequently used for sequential recommender systems evaluation in recent research papers presented at top-tier conferences. As shuffling explicitly breaks sequential dependencies inherent in datasets, we estimate the strength of sequential patterns by comparing metrics for shuffled and original versions of the dataset. Our findings show that several popular datasets have a rather weak sequential structure.
From Variability to Stability: Advancing RecSys Benchmarking Practices
Feb 15, 2024In the rapidly evolving domain of Recommender Systems (RecSys), new algorithms frequently claim state-of-the-art performance based on evaluations over a limited set of arbitrarily selected datasets. However, this approach may fail to holistically reflect their effectiveness due to the significant impact of dataset characteristics on algorithm performance. Addressing this deficiency, this paper introduces a novel benchmarking methodology to facilitate a fair and robust comparison of RecSys algorithms, thereby advancing evaluation practices. By utilizing a diverse set of $30$ open datasets, including two introduced in this work, and evaluating $11$ collaborative filtering algorithms across $9$ metrics, we critically examine the influence of dataset characteristics on algorithm performance. We further investigate the feasibility of aggregating outcomes from multiple datasets into a unified ranking. Through rigorous experimental analysis, we validate the reliability of our methodology under the variability of datasets, offering a benchmarking strategy that balances quality and computational demands. This methodology enables a fair yet effective means of evaluating RecSys algorithms, providing valuable guidance for future research endeavors.
Synthetic Data-Based Simulators for Recommender Systems: A Survey
Jun 22, 2022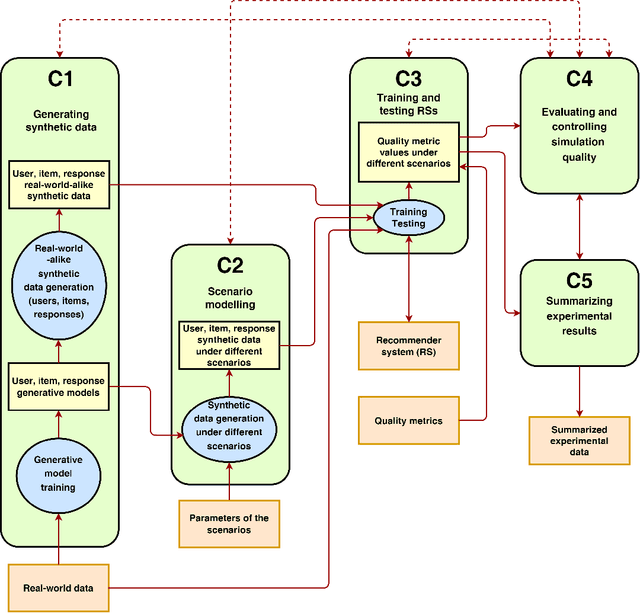
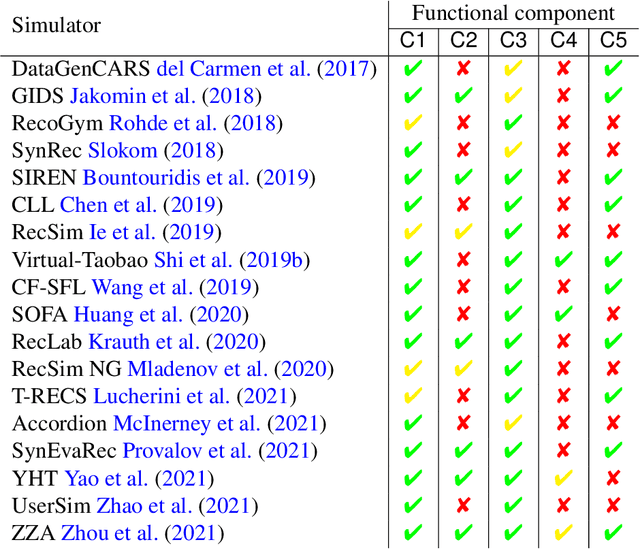
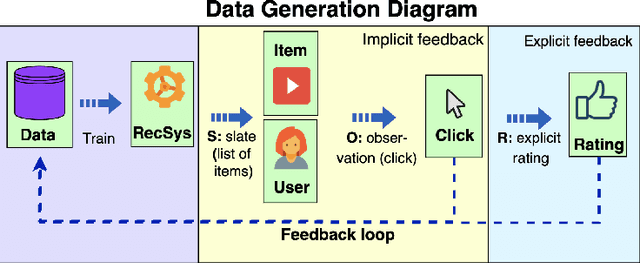
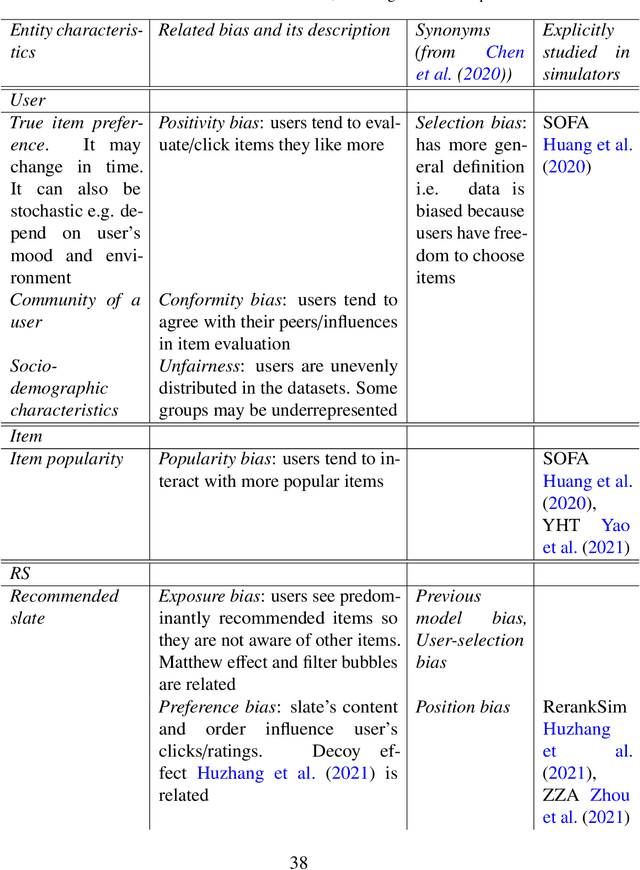
This survey aims at providing a comprehensive overview of the recent trends in the field of modeling and simulation (M&S) of interactions between users and recommender systems and applications of the M&S to the performance improvement of industrial recommender engines. We start with the motivation behind the development of frameworks implementing the simulations -- simulators -- and the usage of them for training and testing recommender systems of different types (including Reinforcement Learning ones). Furthermore, we provide a new consistent classification of existing simulators based on their functionality, approbation, and industrial effectiveness and moreover make a summary of the simulators found in the research literature. Besides other things, we discuss the building blocks of simulators: methods for synthetic data (user, item, user-item responses) generation, methods for what-if experimental analysis, methods and datasets used for simulation quality evaluation (including the methods that monitor and/or close possible simulation-to-reality gaps), and methods for summarization of experimental simulation results. Finally, this survey considers emerging topics and open problems in the field.