 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOrbNet: Deep Learning for Quantum Chemistry Using Symmetry-Adapted Atomic-Orbital Features
Jul 15, 2020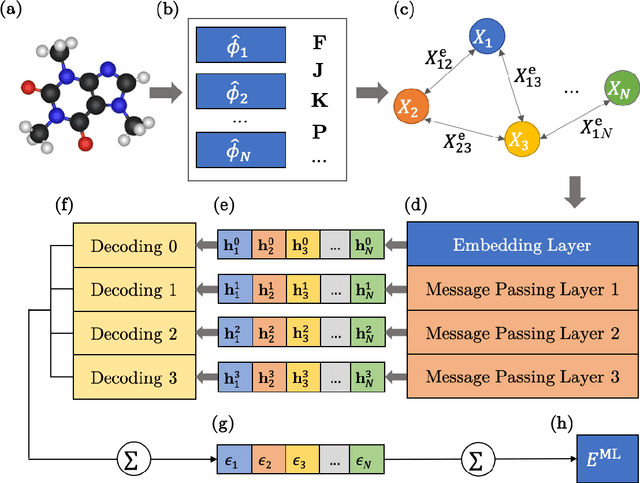
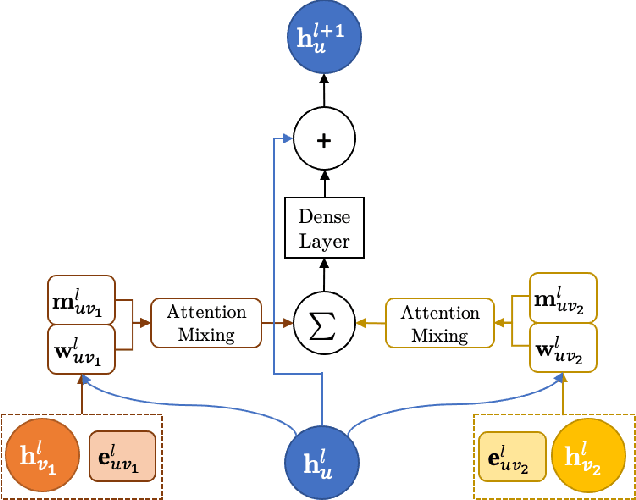
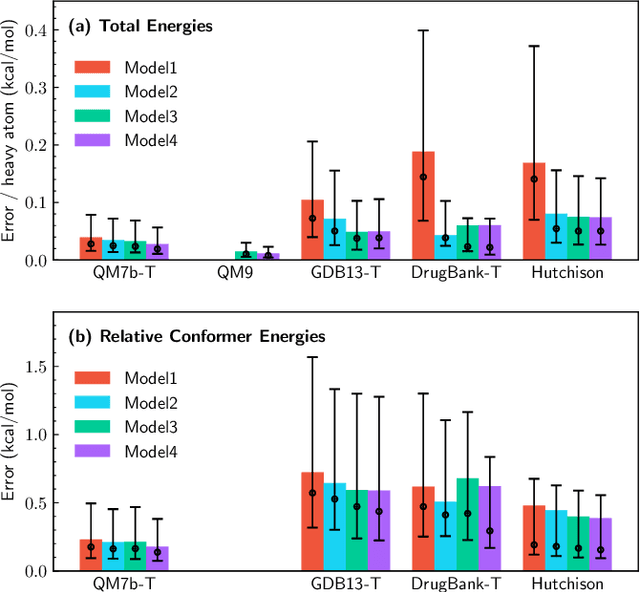
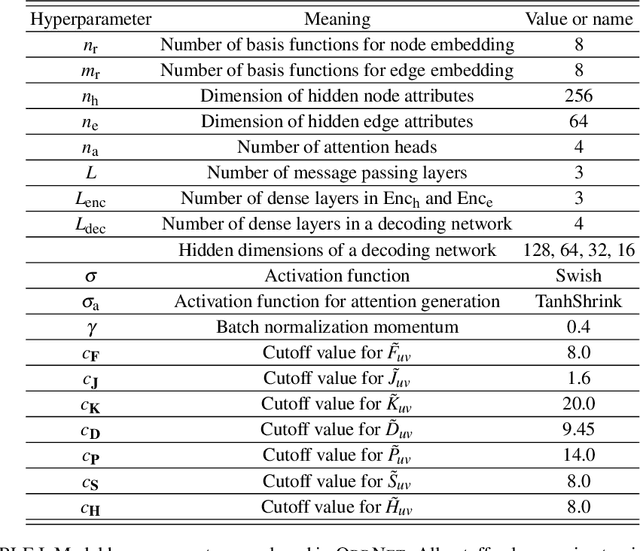
We introduce a machine learning method in which energy solutions from the Schrodinger equation are predicted using symmetry adapted atomic orbitals features and a graph neural-network architecture. \textsc{OrbNet} is shown to outperform existing methods in terms of learning efficiency and transferability for the prediction of density functional theory results while employing low-cost features that are obtained from semi-empirical electronic structure calculations. For applications to datasets of drug-like molecules, including QM7b-T, QM9, GDB-13-T, DrugBank, and the conformer benchmark dataset of Folmsbee and Hutchison, \textsc{OrbNet} predicts energies within chemical accuracy of DFT at a computational cost that is thousand-fold or more reduced.
Causal Discovery in Physical Systems from Videos
Jul 02, 2020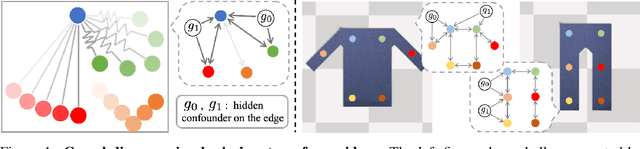
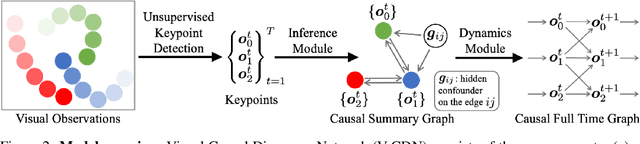
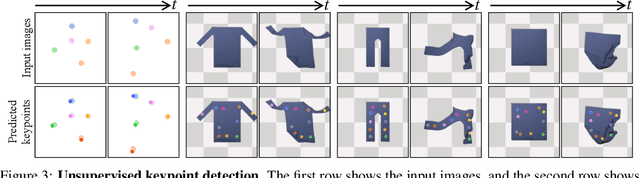
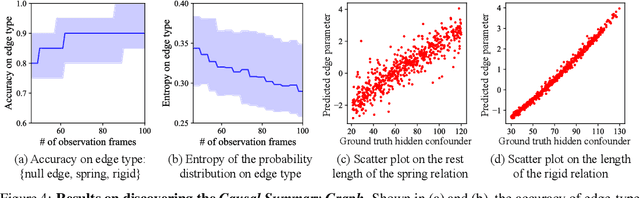
Causal discovery is at the core of human cognition. It enables us to reason about the environment and make counterfactual predictions about unseen scenarios, that can vastly differ from our previous experiences. We consider the task of causal discovery from videos in an end-to-end fashion without supervision on the ground-truth graph structure. In particular, our goal is to discover the structural dependencies among environmental and object variables: inferring the type and strength of interactions that have a causal effect on the behavior of the dynamical system. Our model consists of (a) a perception module that extracts a semantically meaningful and temporally consistent keypoint representation from images, (b) an inference module for determining the graph distribution induced by the detected keypoints, and (c) a dynamics module that can predict the future by conditioning on the inferred graph. We assume access to different configurations and environmental conditions, i.e., data from unknown interventions on the underlying system; thus, we can hope to discover the correct underlying causal graph without explicit interventions. We evaluate our method in a planar multi-body interaction environment and scenarios involving fabrics of different shapes like shirts and pants. Experiments demonstrate that our model can correctly identify the interactions from a short sequence of images and make long-term future predictions. The causal structure assumed by the model also allows it to make counterfactual predictions and extrapolate to systems of unseen interaction graphs or graphs of various sizes.
Convolutional Tensor-Train LSTM for Spatio-temporal Learning
Mar 22, 2020
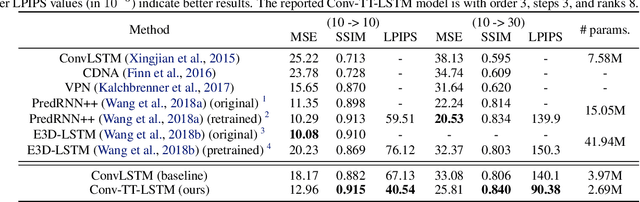

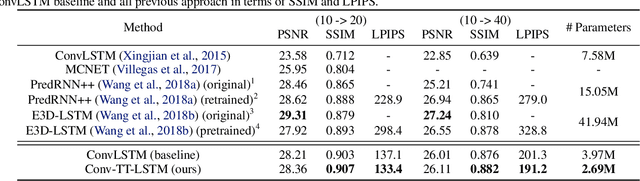
Higher-order Recurrent Neural Networks (RNNs) are effective for long-term forecasting since such architectures can model higher-order correlations and long-term dynamics more effectively. However, higher-order models are expensive and require exponentially more parameters and operations compared with their first-order counterparts. This problem is particularly pronounced in multidimensional data such as videos. To address this issue, we propose Convolutional Tensor-Train Decomposition (CTTD), a novel tensor decomposition with convolutional operations. With CTTD, we construct Convolutional Tensor-Train LSTM (Conv-TT-LSTM) to capture higher-order space-time correlations in videos. We demonstrate that the proposed model outperforms the conventional (first-order) Convolutional LSTM (ConvLSTM) as well as the state-of-the-art ConvLSTM-based approaches in pixel-level video prediction tasks on Moving-MNIST and KTH action datasets, but with much fewer parameters.
Learning Pose Estimation for UAV Autonomous Navigation andLanding Using Visual-Inertial Sensor Data
Dec 10, 2019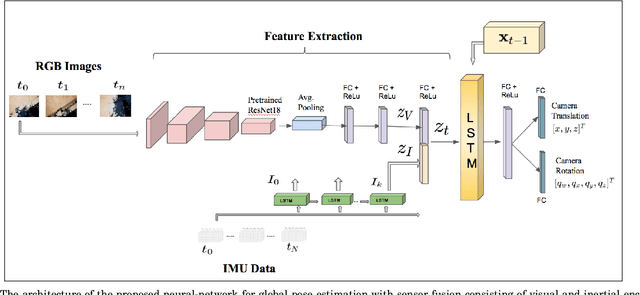
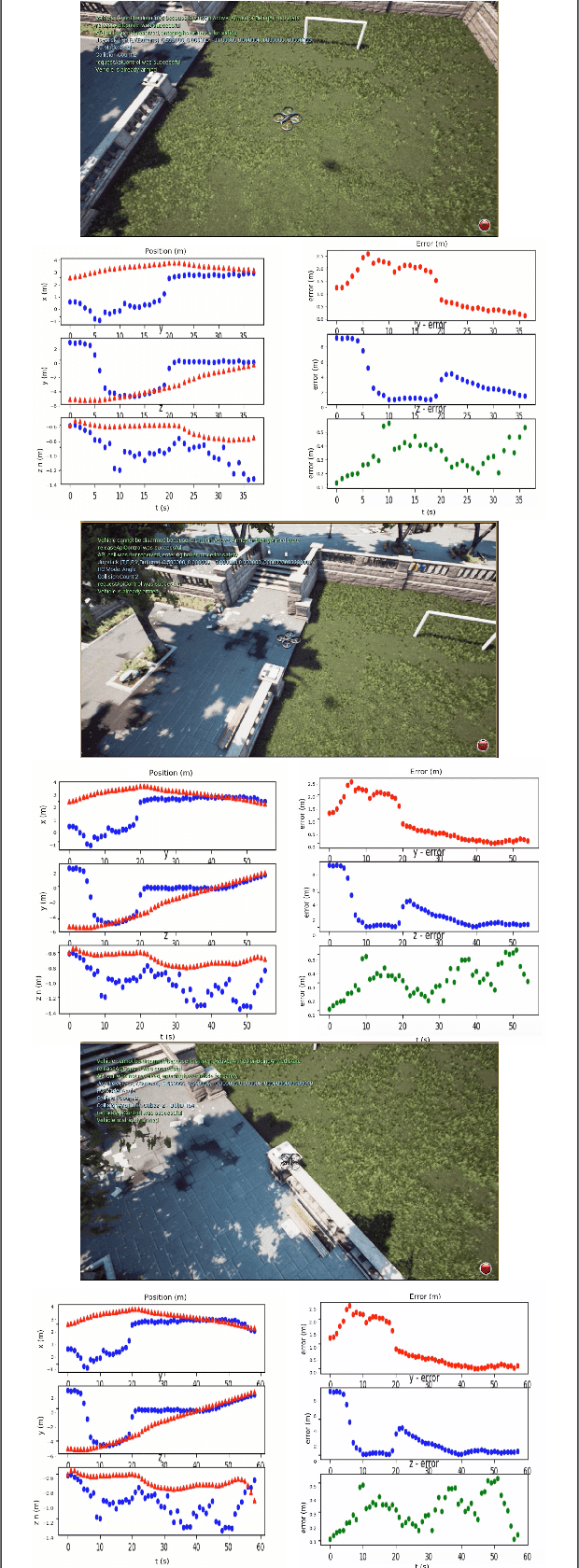

In this work, we propose a robust network-in-the-loop control system that allows an Unmanned-Aerial-Vehicles to navigate and land autonomously ona desired target. To estimate the global pose of theaerial vehicle, we develop a deep neural network ar-chitecture for visual-inertial odometry, which providesa robust alternative to traditional techniques for au-tonomous navigation of Unmanned-Aerial-Vehicles. Wefirst provide experimental results on the accuracy ofthe estimation by comparing the prediction of our modelto traditional visual-inertial approaches on the publiclyavailable EuRoC MAV dataset. The results indicate aclear improvement in the accuracy of the pose estima-tion up to 25% against the baseline. Second, we useAirsim, a simulator available as a plugin for UnrealEngine, to create new datasets of photorealistic imagesand inertial measurement to train and test our model.We finally integrate the proposed architecture for globallocalization with the Airsim closed-loop control system,and we provide simulation results for the autonomouslanding of the aerial vehicle.
Memory Augmented Recursive Neural Networks
Nov 08, 2019
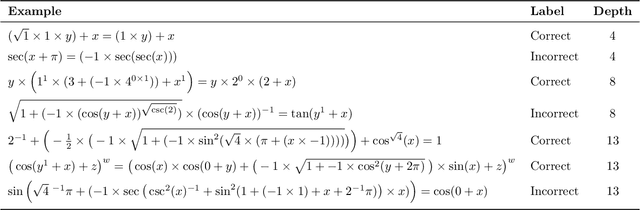

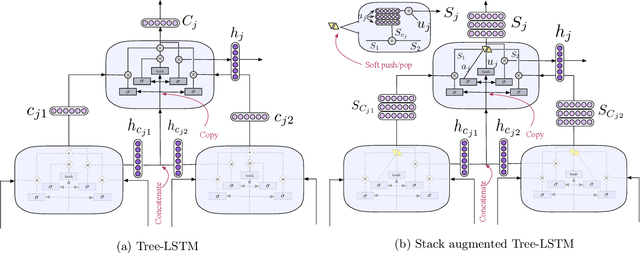
Recursive neural networks have shown an impressive performance for modeling compositional data compared to their recurrent counterparts. Although recursive neural networks are better at capturing long range dependencies, their generalization performance starts to decay as the test data becomes more compositional and potentially deeper than the training data. In this paper, we present memory-augmented recursive neural networks to address this generalization performance loss on deeper data points. We augment Tree-LSTMs with an external memory, namely neural stacks. We define soft push and pop operations for filling and emptying the memory to ensure that the networks remain end-to-end differentiable. In order to assess the effectiveness of the external memory, we evaluate our model on a neural programming task introduced in the literature called equation verification. Our results indicate that augmenting recursive neural networks with external memory consistently improves the generalization performance on deeper data points compared to the state-of-the-art Tree-LSTM by up to 10%.
Regularized Learning for Domain Adaptation under Label Shifts
Mar 22, 2019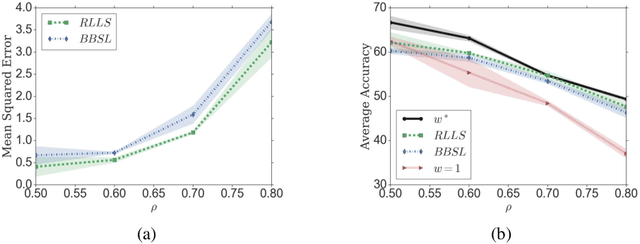
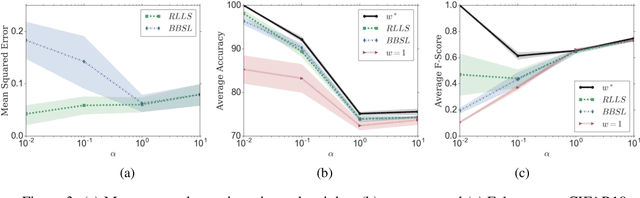
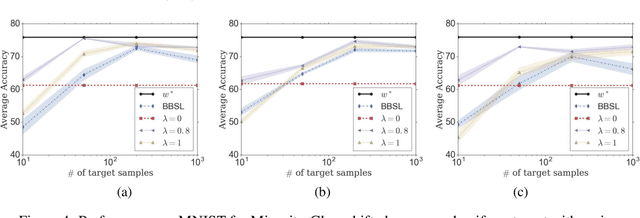
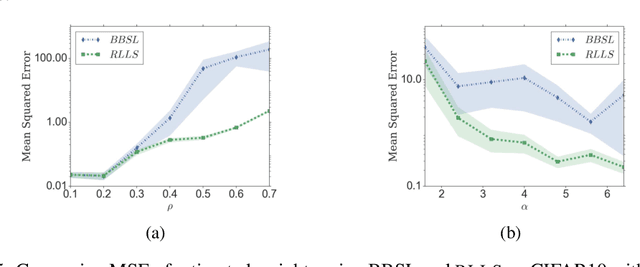
We propose Regularized Learning under Label shifts (RLLS), a principled and a practical domain-adaptation algorithm to correct for shifts in the label distribution between a source and a target domain. We first estimate importance weights using labeled source data and unlabeled target data, and then train a classifier on the weighted source samples. We derive a generalization bound for the classifier on the target domain which is independent of the (ambient) data dimensions, and instead only depends on the complexity of the function class. To the best of our knowledge, this is the first generalization bound for the label-shift problem where the labels in the target domain are not available. Based on this bound, we propose a regularized estimator for the small-sample regime which accounts for the uncertainty in the estimated weights. Experiments on the CIFAR-10 and MNIST datasets show that RLLS improves classification accuracy, especially in the low sample and large-shift regimes, compared to previous methods.
* International Conference on Learning Representations (ICLR) 2019
Neural Lander: Stable Drone Landing Control using Learned Dynamics
Mar 04, 2019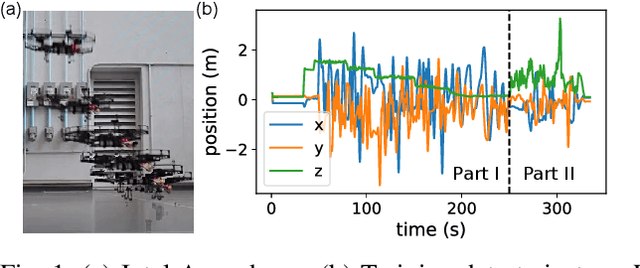
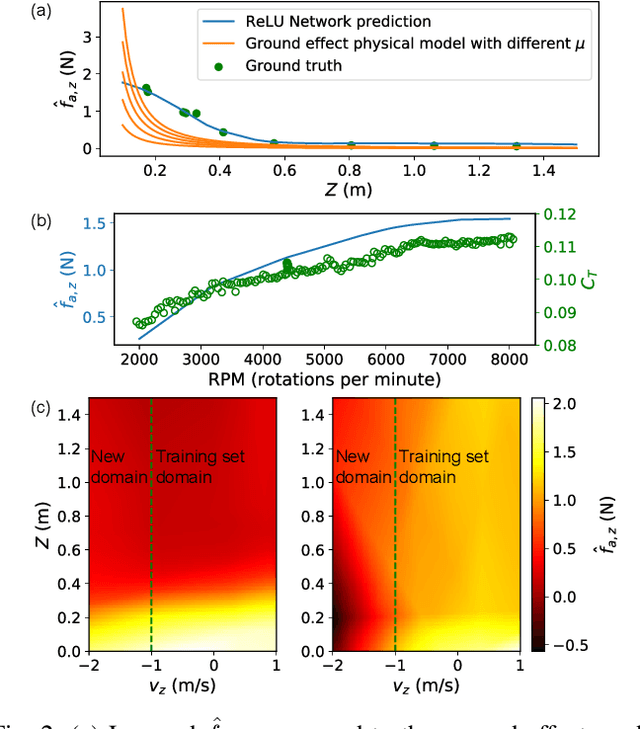
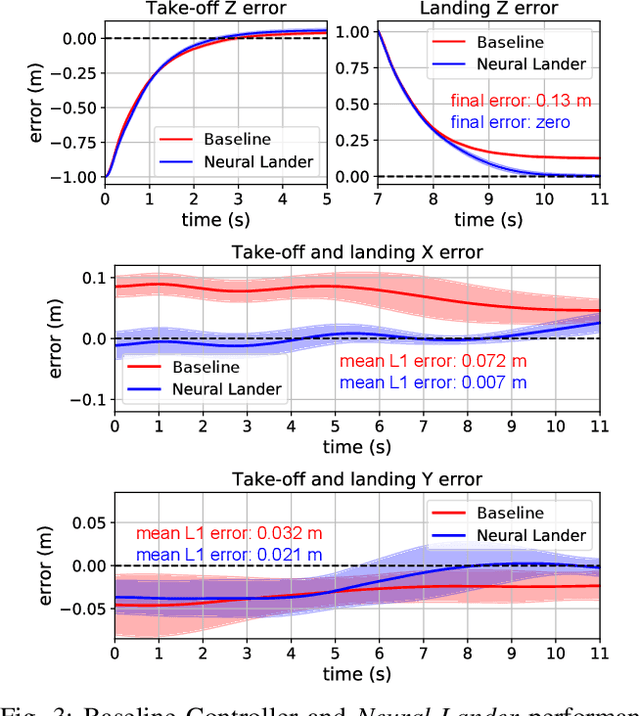
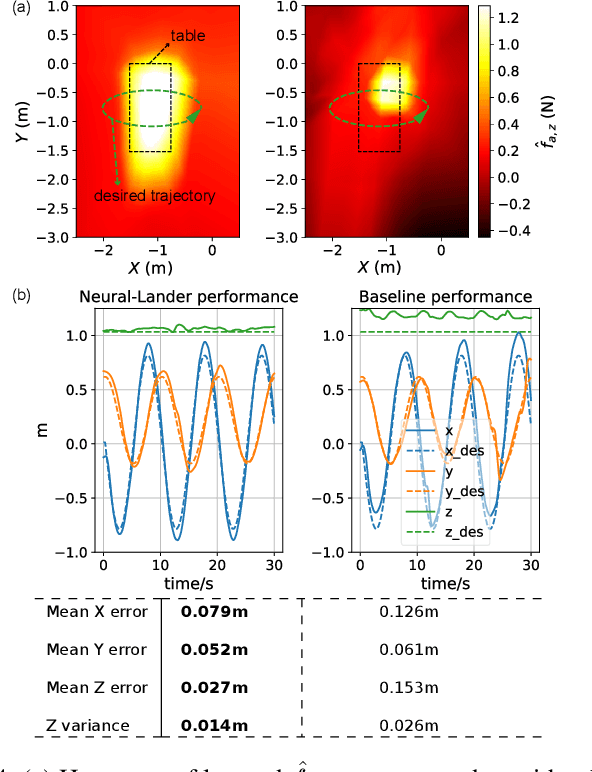
Precise near-ground trajectory control is difficult for multi-rotor drones, due to the complex aerodynamic effects caused by interactions between multi-rotor airflow and the environment. Conventional control methods often fail to properly account for these complex effects and fall short in accomplishing smooth landing. In this paper, we present a novel deep-learning-based robust nonlinear controller (Neural Lander) that improves control performance of a quadrotor during landing. Our approach combines a nominal dynamics model with a Deep Neural Network (DNN) that learns high-order interactions. We apply spectral normalization (SN) to constrain the Lipschitz constant of the DNN. Leveraging this Lipschitz property, we design a nonlinear feedback linearization controller using the learned model and prove system stability with disturbance rejection. To the best of our knowledge, this is the first DNN-based nonlinear feedback controller with stability guarantees that can utilize arbitrarily large neural nets. Experimental results demonstrate that the proposed controller significantly outperforms a Baseline Nonlinear Tracking Controller in both landing and cross-table trajectory tracking cases. We also empirically show that the DNN generalizes well to unseen data outside the training domain.
Multi-dimensional Tensor Sketch
Feb 06, 2019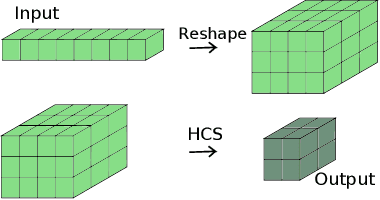

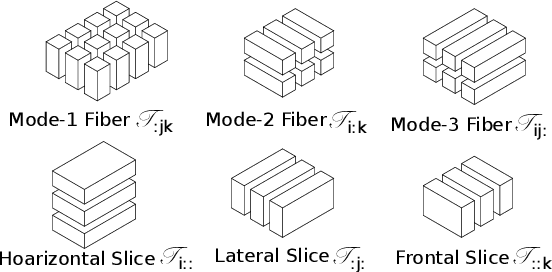

Sketching refers to a class of randomized dimensionality reduction methods that aim to preserve relevant information in large-scale datasets. They have efficient memory requirements and typically require just a single pass over the dataset. Efficient sketching methods have been derived for vector and matrix-valued datasets. When the datasets are higher-order tensors, a naive approach is to flatten the tensors into vectors or matrices and then sketch them. However, this is inefficient since it ignores the multi-dimensional nature of tensors. In this paper, we propose a novel multi-dimensional tensor sketch (MTS) that preserves higher order data structures while reducing dimensionality. We build this as an extension to the popular count sketch (CS) and show that it yields an unbiased estimator of the original tensor. We demonstrate significant advantages in compression ratios when the original data has decomposable tensor representations such as the Tucker, CP, tensor train or Kronecker product forms. We apply MTS to tensorized neural networks where we replace fully connected layers with tensor operations. We achieve nearly state of art accuracy with significant compression on image classification benchmarks.
Trust Region Policy Optimization of POMDPs
Oct 18, 2018
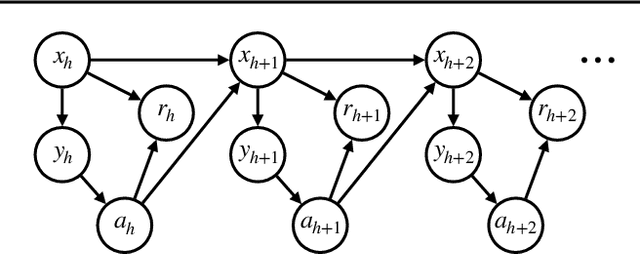
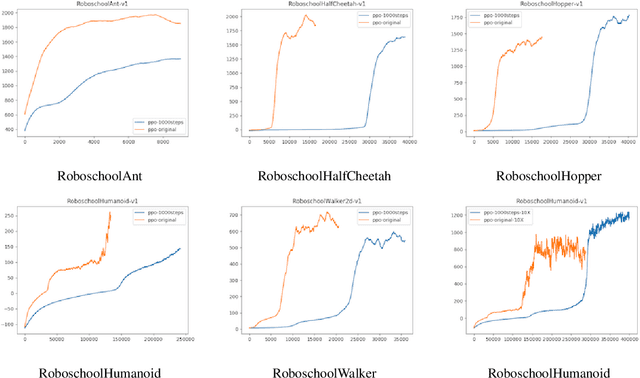
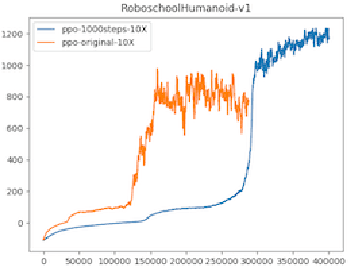
We propose Generalized Trust Region Policy Optimization (GTRPO), a Reinforcement Learning algorithm for TRPO of Partially Observable Markov Decision Processes (POMDP). While the principle of policy gradient methods does not require any model assumption, previous studies of more sophisticated policy gradient methods are mainly limited to MDPs. Many real-world decision-making tasks, however, are inherently non-Markovian, i.e., only an incomplete representation of the environment is observable. Moreover, most of the advanced policy gradient methods are designed for infinite horizon MDPs. Our proposed algorithm, GTRPO, is a policy gradient method for continuous episodic POMDPs. We prove that its policy updates monotonically improve the expected cumulative return. We empirically study GTRPO on many RoboSchool environments, an extension to the MuJoCo environments, and provide insights into its empirical behavior.
Question Type Guided Attention in Visual Question Answering
Jul 18, 2018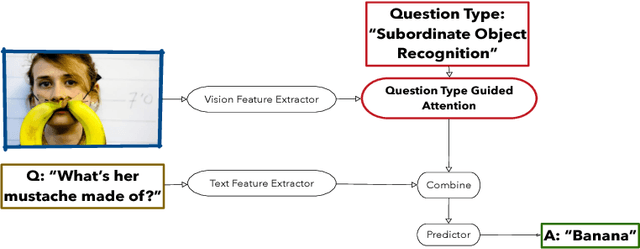
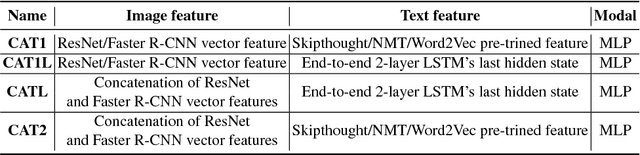
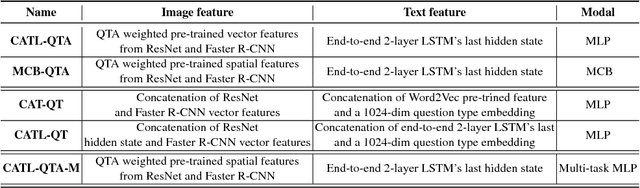
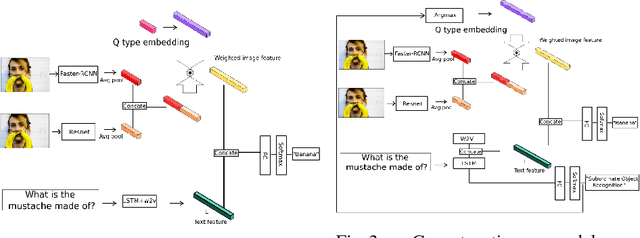
Visual Question Answering (VQA) requires integration of feature maps with drastically different structures and focus of the correct regions. Image descriptors have structures at multiple spatial scales, while lexical inputs inherently follow a temporal sequence and naturally cluster into semantically different question types. A lot of previous works use complex models to extract feature representations but neglect to use high-level information summary such as question types in learning. In this work, we propose Question Type-guided Attention (QTA). It utilizes the information of question type to dynamically balance between bottom-up and top-down visual features, respectively extracted from ResNet and Faster R-CNN networks. We experiment with multiple VQA architectures with extensive input ablation studies over the TDIUC dataset and show that QTA systematically improves the performance by more than 5% across multiple question type categories such as "Activity Recognition", "Utility" and "Counting" on TDIUC dataset. By adding QTA on the state-of-art model MCB, we achieve 3% improvement for overall accuracy. Finally, we propose a multi-task extension to predict question types which generalizes QTA to applications that lack of question type, with minimal performance loss.