 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpatial-Temporal Networks for Antibiogram Pattern Prediction
May 02, 2023An antibiogram is a periodic summary of antibiotic resistance results of organisms from infected patients to selected antimicrobial drugs. Antibiograms help clinicians to understand regional resistance rates and select appropriate antibiotics in prescriptions. In practice, significant combinations of antibiotic resistance may appear in different antibiograms, forming antibiogram patterns. Such patterns may imply the prevalence of some infectious diseases in certain regions. Thus it is of crucial importance to monitor antibiotic resistance trends and track the spread of multi-drug resistant organisms. In this paper, we propose a novel problem of antibiogram pattern prediction that aims to predict which patterns will appear in the future. Despite its importance, tackling this problem encounters a series of challenges and has not yet been explored in the literature. First of all, antibiogram patterns are not i.i.d as they may have strong relations with each other due to genomic similarities of the underlying organisms. Second, antibiogram patterns are often temporally dependent on the ones that are previously detected. Furthermore, the spread of antibiotic resistance can be significantly influenced by nearby or similar regions. To address the above challenges, we propose a novel Spatial-Temporal Antibiogram Pattern Prediction framework, STAPP, that can effectively leverage the pattern correlations and exploit the temporal and spatial information. We conduct extensive experiments on a real-world dataset with antibiogram reports of patients from 1999 to 2012 for 203 cities in the United States. The experimental results show the superiority of STAPP against several competitive baselines.
Finding Nontrivial Minimum Fixed Points in Discrete Dynamical Systems
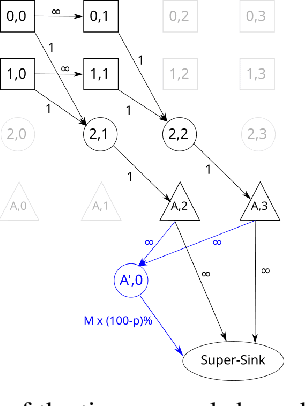
Jan 06, 2023Networked discrete dynamical systems are often used to model the spread of contagions and decision-making by agents in coordination games. Fixed points of such dynamical systems represent configurations to which the system converges. In the dissemination of undesirable contagions (such as rumors and misinformation), convergence to fixed points with a small number of affected nodes is a desirable goal. Motivated by such considerations, we formulate a novel optimization problem of finding a nontrivial fixed point of the system with the minimum number of affected nodes. We establish that, unless P = NP, there is no polynomial time algorithm for approximating a solution to this problem to within the factor n^1-\epsilon for any constant epsilon > 0. To cope with this computational intractability, we identify several special cases for which the problem can be solved efficiently. Further, we introduce an integer linear program to address the problem for networks of reasonable sizes. For solving the problem on larger networks, we propose a general heuristic framework along with greedy selection methods. Extensive experimental results on real-world networks demonstrate the effectiveness of the proposed heuristics.
High-resolution synthetic residential energy use profiles for the United States
Oct 14, 2022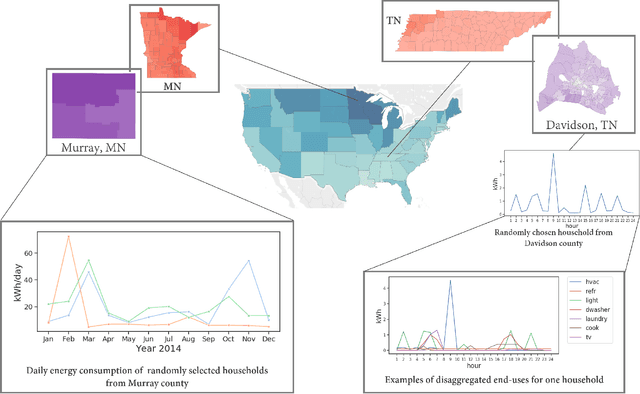


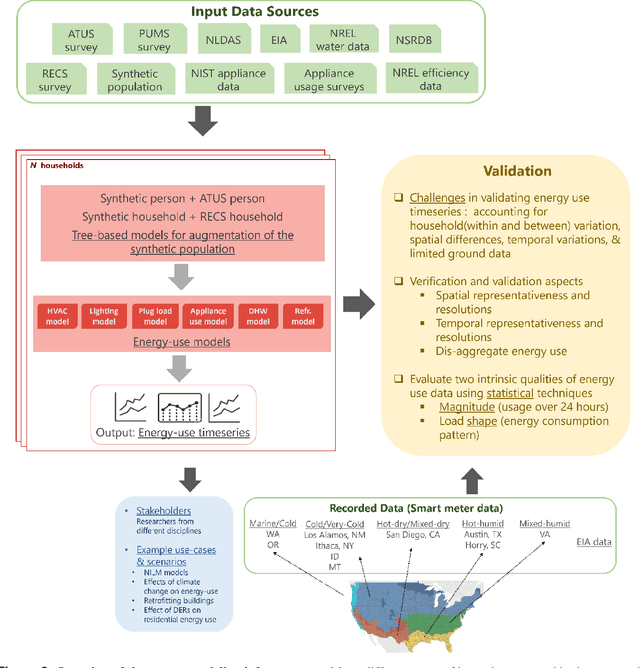
Efficient energy consumption is crucial for achieving sustainable energy goals in the era of climate change and grid modernization. Thus, it is vital to understand how energy is consumed at finer resolutions such as household in order to plan demand-response events or analyze the impacts of weather, electricity prices, electric vehicles, solar, and occupancy schedules on energy consumption. However, availability and access to detailed energy-use data, which would enable detailed studies, has been rare. In this paper, we release a unique, large-scale, synthetic, residential energy-use dataset for the residential sector across the contiguous United States covering millions of households. The data comprise of hourly energy use profiles for synthetic households, disaggregated into Thermostatically Controlled Loads (TCL) and appliance use. The underlying framework is constructed using a bottom-up approach. Diverse open-source surveys and first principles models are used for end-use modeling. Extensive validation of the synthetic dataset has been conducted through comparisons with reported energy-use data. We present a detailed, open, high-resolution, residential energy-use dataset for the United States.
A Scalable Data-Driven Technique for Joint Evacuation Routing and Scheduling Problems
Sep 12, 2022
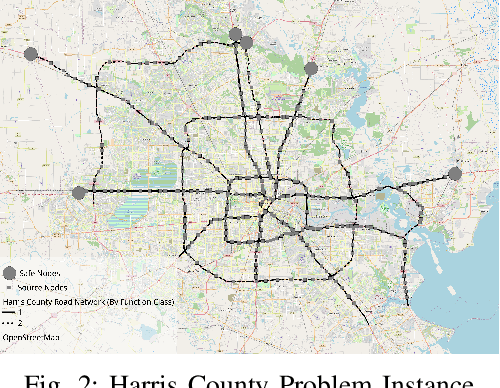
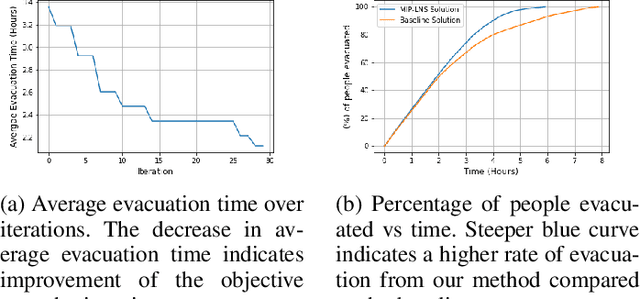
Evacuation planning is a crucial part of disaster management where the goal is to relocate people to safety and minimize casualties. Every evacuation plan has two essential components: routing and scheduling. However, joint optimization of these two components with objectives such as minimizing average evacuation time or evacuation completion time, is a computationally hard problem. To approach it, we present MIP-LNS, a scalable optimization method that combines heuristic search with mathematical optimization and can optimize a variety of objective functions. We use real-world road network and population data from Harris County in Houston, Texas, and apply MIP-LNS to find evacuation routes and schedule for the area. We show that, within a given time limit, our proposed method finds better solutions than existing methods in terms of average evacuation time, evacuation completion time and optimality guarantee of the solutions. We perform agent-based simulations of evacuation in our study area to demonstrate the efficacy and robustness of our solution. We show that our prescribed evacuation plan remains effective even if the evacuees deviate from the suggested schedule upto a certain extent. We also examine how evacuation plans are affected by road failures. Our results show that MIP-LNS can use information regarding estimated deadline of roads to come up with better evacuation plans in terms evacuating more people successfully and conveniently.
Differentially Private Partial Set Cover with Applications to Facility Location
Jul 21, 2022



It was observed in \citet{gupta2009differentially} that the Set Cover problem has strong impossibility results under differential privacy. In our work, we observe that these hardness results dissolve when we turn to the Partial Set Cover problem, where we only need to cover a $\rho$-fraction of the elements in the universe, for some $\rho\in(0,1)$. We show that this relaxation enables us to avoid the impossibility results: under loose conditions on the input set system, we give differentially private algorithms which output an explicit set cover with non-trivial approximation guarantees. In particular, this is the first differentially private algorithm which outputs an explicit set cover. Using our algorithm for Partial Set Cover as a subroutine, we give a differentially private (bicriteria) approximation algorithm for a facility location problem which generalizes $k$-center/$k$-supplier with outliers. Like with the Set Cover problem, no algorithm has been able to give non-trivial guarantees for $k$-center/$k$-supplier-type facility location problems due to the high sensitivity and impossibility results. Our algorithm shows that relaxing the covering requirement to serving only a $\rho$-fraction of the population, for $\rho\in(0,1)$, enables us to circumvent the inherent hardness. Overall, our work is an important step in tackling and understanding impossibility results in private combinatorial optimization.
Controlling Epidemic Spread using Probabilistic Diffusion Models on Networks
Feb 16, 2022The spread of an epidemic is often modeled by an SIR random process on a social network graph. The MinINF problem for optimal social distancing involves minimizing the expected number of infections, when we are allowed to break at most $B$ edges; similarly the MinINFNode problem involves removing at most $B$ vertices. These are fundamental problems in epidemiology and network science. While a number of heuristics have been considered, the complexity of these problems remains generally open. In this paper, we present two bicriteria approximation algorithms for MinINF, which give the first non-trivial approximations for this problem. The first is based on the cut sparsification result of Karger \cite{karger:mathor99}, and works when the transmission probabilities are not too small. The second is a Sample Average Approximation (SAA) based algorithm, which we analyze for the Chung-Lu random graph model. We also extend some of our results to tackle the MinINFNode problem.
Deploying Vaccine Distribution Sites for Improved Accessibility and Equity to Support Pandemic Response
Feb 09, 2022

In response to COVID-19, many countries have mandated social distancing and banned large group gatherings in order to slow down the spread of SARS-CoV-2. These social interventions along with vaccines remain the best way forward to reduce the spread of SARS CoV-2. In order to increase vaccine accessibility, states such as Virginia have deployed mobile vaccination centers to distribute vaccines across the state. When choosing where to place these sites, there are two important factors to take into account: accessibility and equity. We formulate a combinatorial problem that captures these factors and then develop efficient algorithms with theoretical guarantees on both of these aspects. Furthermore, we study the inherent hardness of the problem, and demonstrate strong impossibility results. Finally, we run computational experiments on real-world data to show the efficacy of our methods.
Differentially Private Community Detection for Stochastic Block Models
Jan 31, 2022
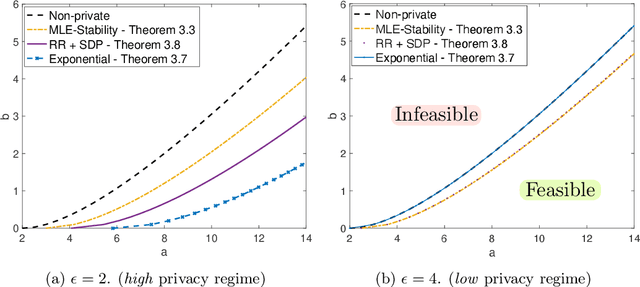

The goal of community detection over graphs is to recover underlying labels/attributes of users (e.g., political affiliation) given the connectivity between users (represented by adjacency matrix of a graph). There has been significant recent progress on understanding the fundamental limits of community detection when the graph is generated from a stochastic block model (SBM). Specifically, sharp information theoretic limits and efficient algorithms have been obtained for SBMs as a function of $p$ and $q$, which represent the intra-community and inter-community connection probabilities. In this paper, we study the community detection problem while preserving the privacy of the individual connections (edges) between the vertices. Focusing on the notion of $(\epsilon, \delta)$-edge differential privacy (DP), we seek to understand the fundamental tradeoffs between $(p, q)$, DP budget $(\epsilon, \delta)$, and computational efficiency for exact recovery of the community labels. To this end, we present and analyze the associated information-theoretic tradeoffs for three broad classes of differentially private community recovery mechanisms: a) stability based mechanism; b) sampling based mechanisms; and c) graph perturbation mechanisms. Our main findings are that stability and sampling based mechanisms lead to a superior tradeoff between $(p,q)$ and the privacy budget $(\epsilon, \delta)$; however this comes at the expense of higher computational complexity. On the other hand, albeit low complexity, graph perturbation mechanisms require the privacy budget $\epsilon$ to scale as $\Omega(\log(n))$ for exact recovery. To the best of our knowledge, this is the first work to study the impact of privacy constraints on the fundamental limits for community detection.
Differentially Private Densest Subgraph Detection
Jun 18, 2021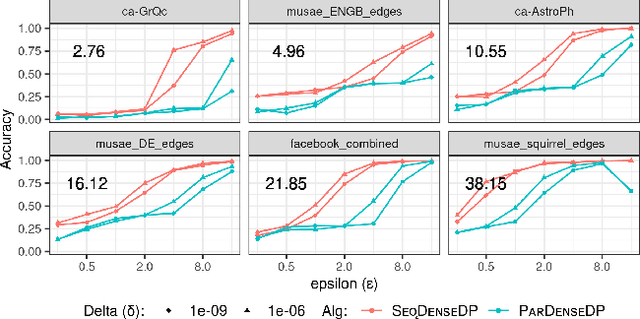

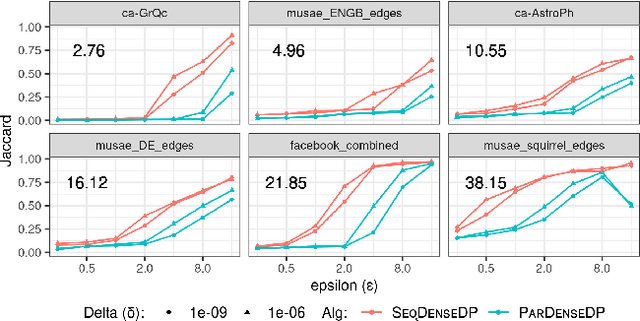

Densest subgraph detection is a fundamental graph mining problem, with a large number of applications. There has been a lot of work on efficient algorithms for finding the densest subgraph in massive networks. However, in many domains, the network is private, and returning a densest subgraph can reveal information about the network. Differential privacy is a powerful framework to handle such settings. We study the densest subgraph problem in the edge privacy model, in which the edges of the graph are private. We present the first sequential and parallel differentially private algorithms for this problem. We show that our algorithms have an additive approximation guarantee. We evaluate our algorithms on a large number of real-world networks, and observe a good privacy-accuracy tradeoff when the network has high density.
Fair Disaster Containment via Graph-Cut Problems
Jun 09, 2021Graph cut problems form a fundamental problem type in combinatorial optimization, and are a central object of study in both theory and practice. In addition, the study of fairness in Algorithmic Design and Machine Learning has recently received significant attention, with many different notions proposed and analyzed in a variety of contexts. In this paper we initiate the study of fairness for graph cut problems by giving the first fair definitions for them, and subsequently we demonstrate appropriate algorithmic techniques that yield a rigorous theoretical analysis. Specifically, we incorporate two different definitions of fairness, namely demographic and probabilistic individual fairness, in a particular cut problem modeling disaster containment scenarios. Our results include a variety of approximation algorithms with provable theoretical guarantees.