 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Text-Native Interface for Generative Video Authoring
Mar 10, 2026Everyone can write their stories in freeform text format -- it's something we all learn in school. Yet storytelling via video requires one to learn specialized and complicated tools. In this paper, we introduce Doki, a text-native interface for generative video authoring, aligning video creation with the natural process of text writing. In Doki, writing text is the primary interaction: within a single document, users define assets, structure scenes, create shots, refine edits, and add audio. We articulate the design principles of this text-first approach and demonstrate Doki's capabilities through a series of examples. To evaluate its real-world use, we conducted a week-long deployment study with participants of varying expertise in video authoring. This work contributes a fundamental shift in generative video interfaces, demonstrating a powerful and accessible new way to craft visual stories.
Vidmento: Creating Video Stories Through Context-Aware Expansion With Generative Video
Jan 29, 2026Video storytelling is often constrained by available material, limiting creative expression and leaving undesired narrative gaps. Generative video offers a new way to address these limitations by augmenting captured media with tailored visuals. To explore this potential, we interviewed eight video creators to identify opportunities and challenges in integrating generative video into their workflows. Building on these insights and established filmmaking principles, we developed Vidmento, a tool for authoring hybrid video stories that combine captured and generated media through context-aware expansion. Vidmento surfaces opportunities for story development, generates clips that blend stylistically and narratively with surrounding media, and provides controls for refinement. In a study with 12 creators, Vidmento supported narrative development and exploration by systematically expanding initial materials with generative media, enabling expressive video storytelling aligned with creative intent. We highlight how creators bridge story gaps with generative content and where they find this blending capability most valuable.
VidTune: Creating Video Soundtracks with Generative Music and Contextual Thumbnails
Jan 17, 2026Music shapes the tone of videos, yet creators often struggle to find soundtracks that match their video's mood and narrative. Recent text-to-music models let creators generate music from text prompts, but our formative study (N=8) shows creators struggle to construct diverse prompts, quickly review and compare tracks, and understand their impact on the video. We present VidTune, a system that supports soundtrack creation by generating diverse music options from a creator's prompt and producing contextual thumbnails for rapid review. VidTune extracts representative video subjects to ground thumbnails in context, maps each track's valence and energy onto visual cues like color and brightness, and depicts prominent genres and instruments. Creators can refine tracks through natural language edits, which VidTune expands into new generations. In a controlled user study (N=12) and an exploratory case study (N=6), participants found VidTune helpful for efficiently reviewing and comparing music options and described the process as playful and enriching.
Learning Style Similarity for Searching Infographics
May 05, 2015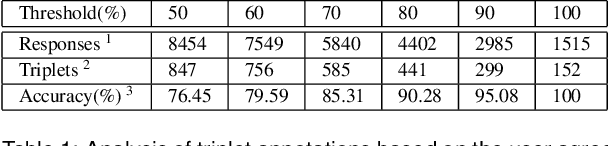

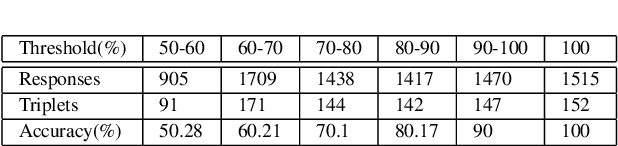
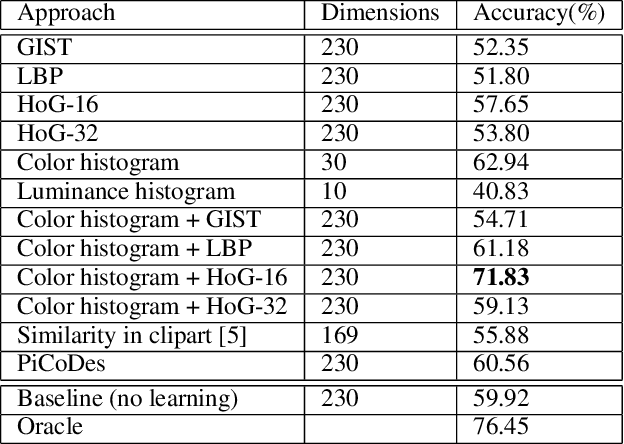
Infographics are complex graphic designs integrating text, images, charts and sketches. Despite the increasing popularity of infographics and the rapid growth of online design portfolios, little research investigates how we can take advantage of these design resources. In this paper we present a method for measuring the style similarity between infographics. Based on human perception data collected from crowdsourced experiments, we use computer vision and machine learning algorithms to learn a style similarity metric for infographic designs. We evaluate different visual features and learning algorithms and find that a combination of color histograms and Histograms-of-Gradients (HoG) features is most effective in characterizing the style of infographics. We demonstrate our similarity metric on a preliminary image retrieval test.