 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmergent Communication through Negotiation
Apr 11, 2018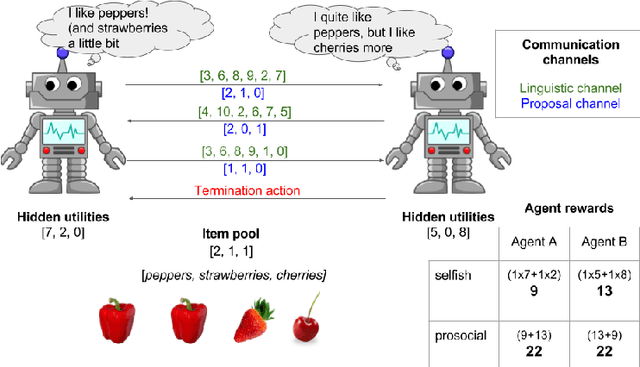
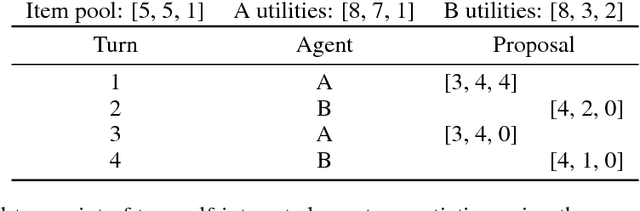
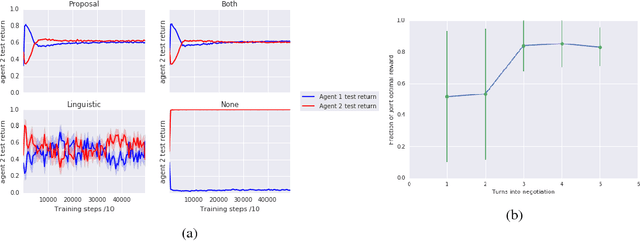
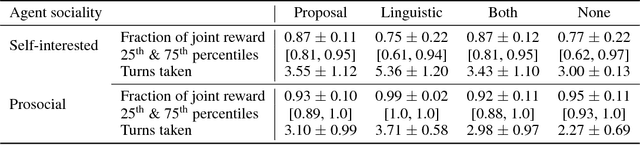
Multi-agent reinforcement learning offers a way to study how communication could emerge in communities of agents needing to solve specific problems. In this paper, we study the emergence of communication in the negotiation environment, a semi-cooperative model of agent interaction. We introduce two communication protocols -- one grounded in the semantics of the game, and one which is \textit{a priori} ungrounded and is a form of cheap talk. We show that self-interested agents can use the pre-grounded communication channel to negotiate fairly, but are unable to effectively use the ungrounded channel. However, prosocial agents do learn to use cheap talk to find an optimal negotiating strategy, suggesting that cooperation is necessary for language to emerge. We also study communication behaviour in a setting where one agent interacts with agents in a community with different levels of prosociality and show how agent identifiability can aid negotiation.
Compositional Obverter Communication Learning From Raw Visual Input
Apr 06, 2018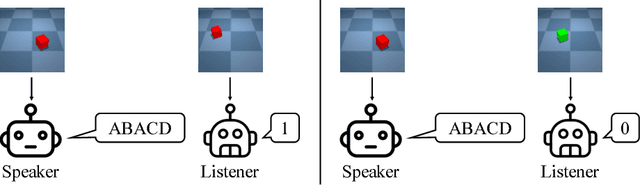
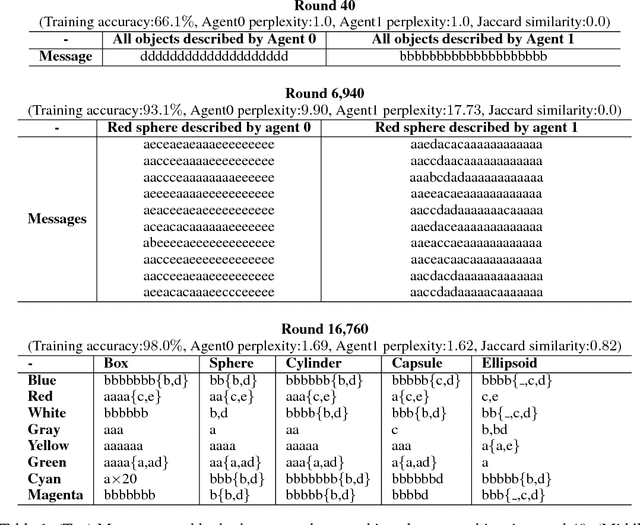

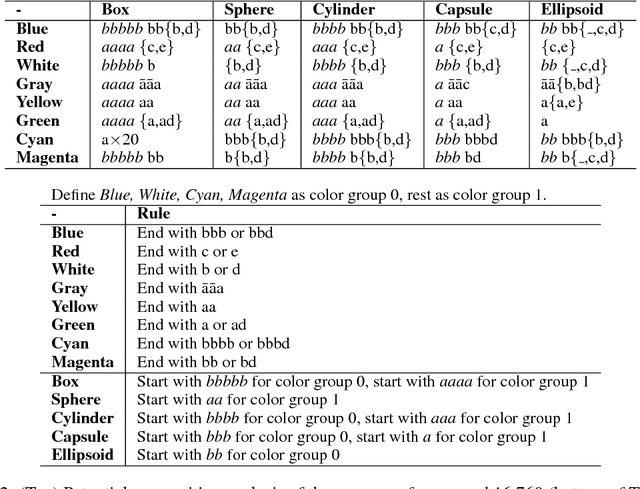
One of the distinguishing aspects of human language is its compositionality, which allows us to describe complex environments with limited vocabulary. Previously, it has been shown that neural network agents can learn to communicate in a highly structured, possibly compositional language based on disentangled input (e.g. hand- engineered features). Humans, however, do not learn to communicate based on well-summarized features. In this work, we train neural agents to simultaneously develop visual perception from raw image pixels, and learn to communicate with a sequence of discrete symbols. The agents play an image description game where the image contains factors such as colors and shapes. We train the agents using the obverter technique where an agent introspects to generate messages that maximize its own understanding. Through qualitative analysis, visualization and a zero-shot test, we show that the agents can develop, out of raw image pixels, a language with compositional properties, given a proper pressure from the environment.
A Unified Game-Theoretic Approach to Multiagent Reinforcement Learning
Nov 07, 2017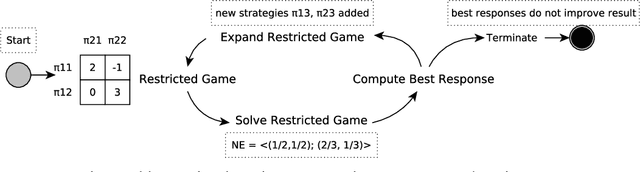
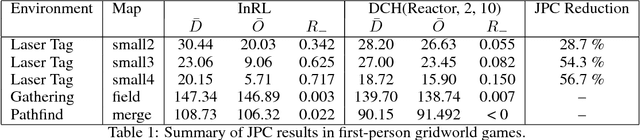
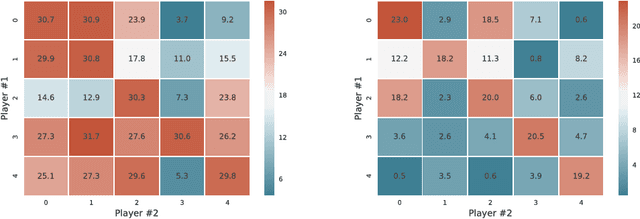
To achieve general intelligence, agents must learn how to interact with others in a shared environment: this is the challenge of multiagent reinforcement learning (MARL). The simplest form is independent reinforcement learning (InRL), where each agent treats its experience as part of its (non-stationary) environment. In this paper, we first observe that policies learned using InRL can overfit to the other agents' policies during training, failing to sufficiently generalize during execution. We introduce a new metric, joint-policy correlation, to quantify this effect. We describe an algorithm for general MARL, based on approximate best responses to mixtures of policies generated using deep reinforcement learning, and empirical game-theoretic analysis to compute meta-strategies for policy selection. The algorithm generalizes previous ones such as InRL, iterated best response, double oracle, and fictitious play. Then, we present a scalable implementation which reduces the memory requirement using decoupled meta-solvers. Finally, we demonstrate the generality of the resulting policies in two partially observable settings: gridworld coordination games and poker.
The RepEval 2017 Shared Task: Multi-Genre Natural Language Inference with Sentence Representations
Jul 25, 2017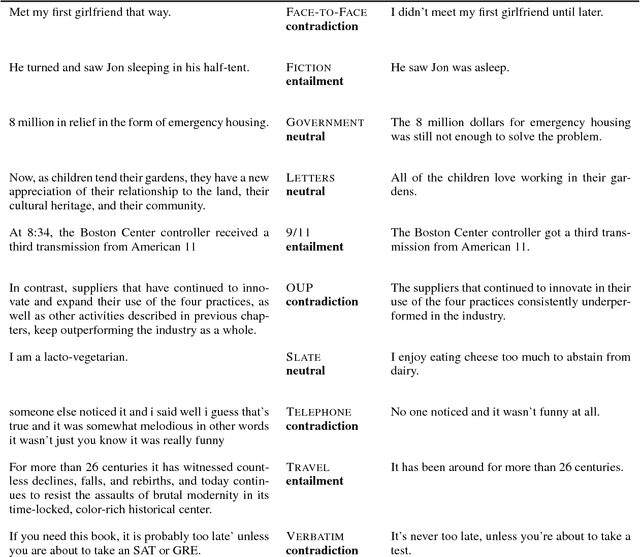

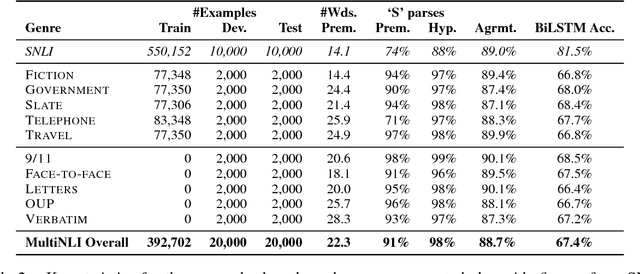
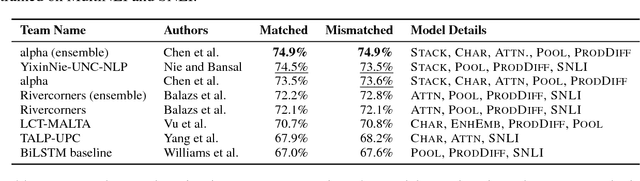
This paper presents the results of the RepEval 2017 Shared Task, which evaluated neural network sentence representation learning models on the Multi-Genre Natural Language Inference corpus (MultiNLI) recently introduced by Williams et al. (2017). All of the five participating teams beat the bidirectional LSTM (BiLSTM) and continuous bag of words baselines reported in Williams et al.. The best single model used stacked BiLSTMs with residual connections to extract sentence features and reached 74.5% accuracy on the genre-matched test set. Surprisingly, the results of the competition were fairly consistent across the genre-matched and genre-mismatched test sets, and across subsets of the test data representing a variety of linguistic phenomena, suggesting that all of the submitted systems learned reasonably domain-independent representations for sentence meaning.
CommAI: Evaluating the first steps towards a useful general AI
Mar 27, 2017With machine learning successfully applied to new daunting problems almost every day, general AI starts looking like an attainable goal. However, most current research focuses instead on important but narrow applications, such as image classification or machine translation. We believe this to be largely due to the lack of objective ways to measure progress towards broad machine intelligence. In order to fill this gap, we propose here a set of concrete desiderata for general AI, together with a platform to test machines on how well they satisfy such desiderata, while keeping all further complexities to a minimum.
Multi-Agent Cooperation and the Emergence of Language
Mar 05, 2017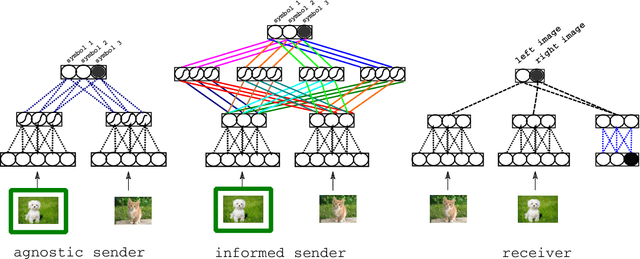
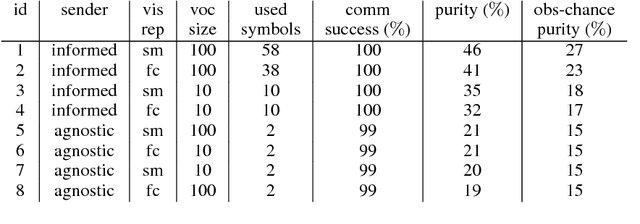
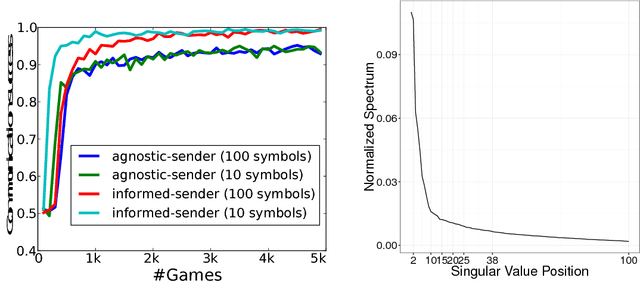
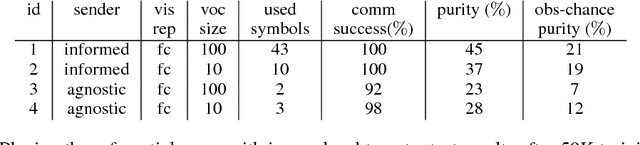
The current mainstream approach to train natural language systems is to expose them to large amounts of text. This passive learning is problematic if we are interested in developing interactive machines, such as conversational agents. We propose a framework for language learning that relies on multi-agent communication. We study this learning in the context of referential games. In these games, a sender and a receiver see a pair of images. The sender is told one of them is the target and is allowed to send a message from a fixed, arbitrary vocabulary to the receiver. The receiver must rely on this message to identify the target. Thus, the agents develop their own language interactively out of the need to communicate. We show that two networks with simple configurations are able to learn to coordinate in the referential game. We further explore how to make changes to the game environment to cause the "word meanings" induced in the game to better reflect intuitive semantic properties of the images. In addition, we present a simple strategy for grounding the agents' code into natural language. Both of these are necessary steps towards developing machines that are able to communicate with humans productively.
The LAMBADA dataset: Word prediction requiring a broad discourse context
Jun 20, 2016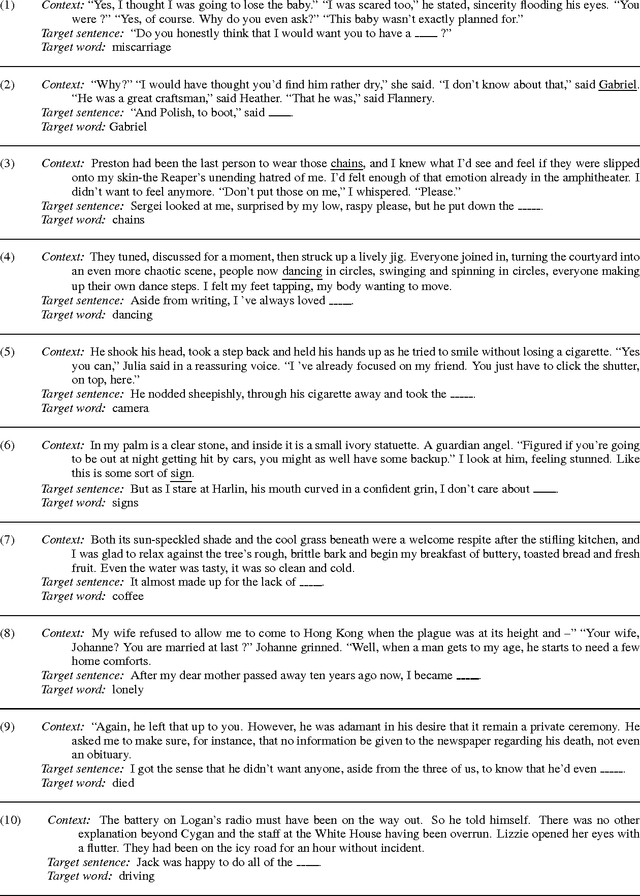
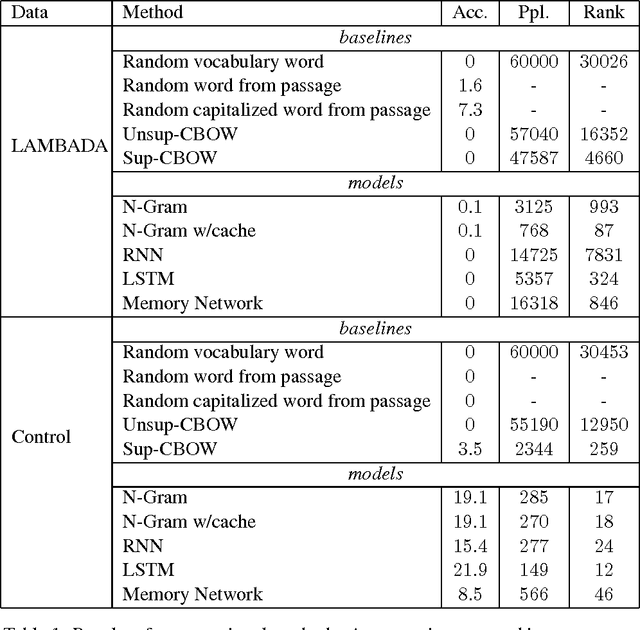
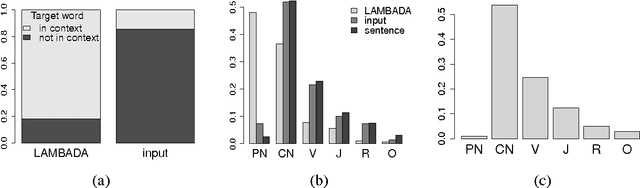
We introduce LAMBADA, a dataset to evaluate the capabilities of computational models for text understanding by means of a word prediction task. LAMBADA is a collection of narrative passages sharing the characteristic that human subjects are able to guess their last word if they are exposed to the whole passage, but not if they only see the last sentence preceding the target word. To succeed on LAMBADA, computational models cannot simply rely on local context, but must be able to keep track of information in the broader discourse. We show that LAMBADA exemplifies a wide range of linguistic phenomena, and that none of several state-of-the-art language models reaches accuracy above 1% on this novel benchmark. We thus propose LAMBADA as a challenging test set, meant to encourage the development of new models capable of genuine understanding of broad context in natural language text.
Towards Multi-Agent Communication-Based Language Learning
May 23, 2016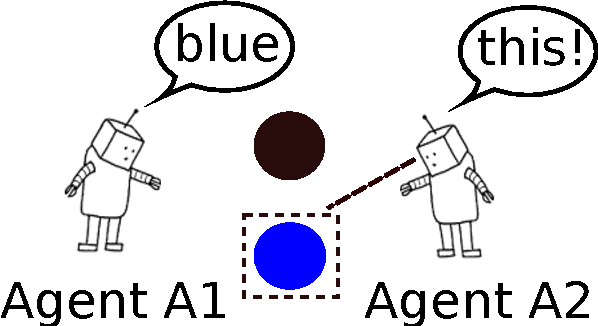

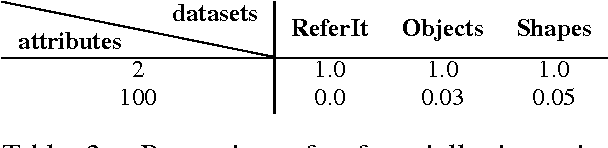
We propose an interactive multimodal framework for language learning. Instead of being passively exposed to large amounts of natural text, our learners (implemented as feed-forward neural networks) engage in cooperative referential games starting from a tabula rasa setup, and thus develop their own language from the need to communicate in order to succeed at the game. Preliminary experiments provide promising results, but also suggest that it is important to ensure that agents trained in this way do not develop an adhoc communication code only effective for the game they are playing
The red one!: On learning to refer to things based on their discriminative properties
May 23, 2016

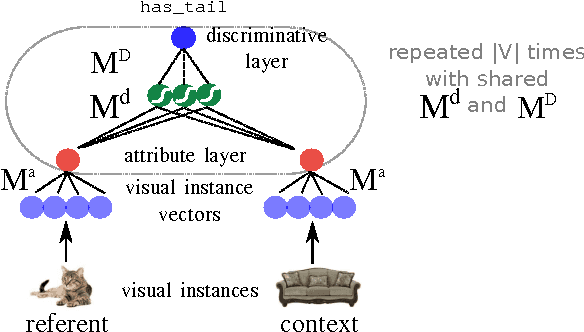
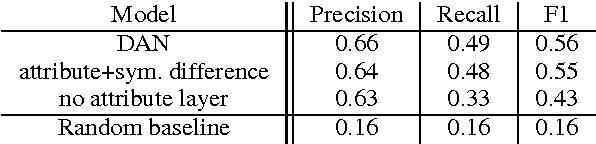
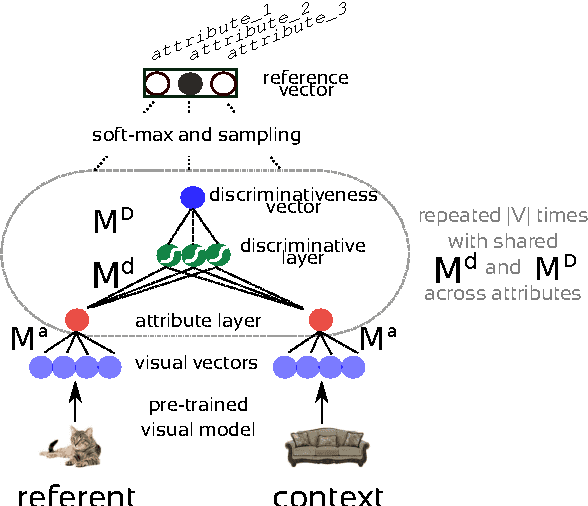
As a first step towards agents learning to communicate about their visual environment, we propose a system that, given visual representations of a referent (cat) and a context (sofa), identifies their discriminative attributes, i.e., properties that distinguish them (has_tail). Moreover, despite the lack of direct supervision at the attribute level, the model learns to assign plausible attributes to objects (sofa-has_cushion). Finally, we present a preliminary experiment confirming the referential success of the predicted discriminative attributes.
Unveiling the Dreams of Word Embeddings: Towards Language-Driven Image Generation
Nov 23, 2015


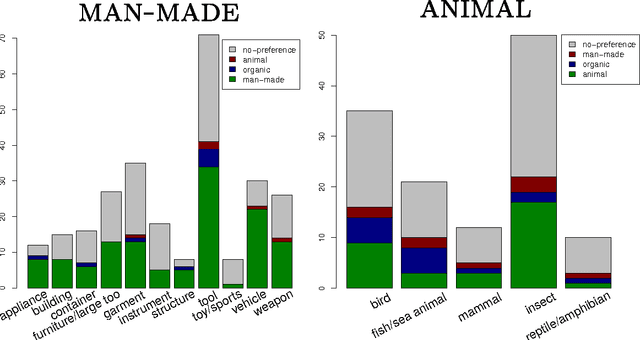
We introduce language-driven image generation, the task of generating an image visualizing the semantic contents of a word embedding, e.g., given the word embedding of grasshopper, we generate a natural image of a grasshopper. We implement a simple method based on two mapping functions. The first takes as input a word embedding (as produced, e.g., by the word2vec toolkit) and maps it onto a high-level visual space (e.g., the space defined by one of the top layers of a Convolutional Neural Network). The second function maps this abstract visual representation to pixel space, in order to generate the target image. Several user studies suggest that the current system produces images that capture general visual properties of the concepts encoded in the word embedding, such as color or typical environment, and are sufficient to discriminate between general categories of objects.