 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Code Generation by Training with Natural Language Feedback
Mar 28, 2023



The potential for pre-trained large language models (LLMs) to use natural language feedback at inference time has been an exciting recent development. We build upon this observation by formalizing an algorithm for learning from natural language feedback at training time instead, which we call Imitation learning from Language Feedback (ILF). ILF requires only a small amount of human-written feedback during training and does not require the same feedback at test time, making it both user-friendly and sample-efficient. We further show that ILF can be seen as a form of minimizing the KL divergence to the ground truth distribution and demonstrate a proof-of-concept on a neural program synthesis task. We use ILF to improve a Codegen-Mono 6.1B model's pass@1 rate by 38% relative (and 10% absolute) on the Mostly Basic Python Problems (MBPP) benchmark, outperforming both fine-tuning on MBPP and fine-tuning on repaired programs written by humans. Overall, our results suggest that learning from human-written natural language feedback is both more effective and sample-efficient than training exclusively on demonstrations for improving an LLM's performance on code generation tasks.
EvoPrompting: Language Models for Code-Level Neural Architecture Search
Feb 28, 2023



Given the recent impressive accomplishments of language models (LMs) for code generation, we explore the use of LMs as adaptive mutation and crossover operators for an evolutionary neural architecture search (NAS) algorithm. While NAS still proves too difficult a task for LMs to succeed at solely through prompting, we find that the combination of evolutionary prompt engineering with soft prompt-tuning, a method we term EvoPrompting, consistently finds diverse and high performing models. We first demonstrate that EvoPrompting is effective on the computationally efficient MNIST-1D dataset, where EvoPrompting produces convolutional architecture variants that outperform both those designed by human experts and naive few-shot prompting in terms of accuracy and model size. We then apply our method to searching for graph neural networks on the CLRS Algorithmic Reasoning Benchmark, where EvoPrompting is able to design novel architectures that outperform current state-of-the-art models on 21 out of 30 algorithmic reasoning tasks while maintaining similar model size. EvoPrompting is successful at designing accurate and efficient neural network architectures across a variety of machine learning tasks, while also being general enough for easy adaptation to other tasks beyond neural network design.
Pretraining Language Models with Human Preferences
Feb 16, 2023Language models (LMs) are pretrained to imitate internet text, including content that would violate human preferences if generated by an LM: falsehoods, offensive comments, personally identifiable information, low-quality or buggy code, and more. Here, we explore alternative objectives for pretraining LMs in a way that also guides them to generate text aligned with human preferences. We benchmark five objectives for pretraining with human feedback across three tasks and study how they affect the trade-off between alignment and capabilities of pretrained LMs. We find a Pareto-optimal and simple approach among those we explored: conditional training, or learning distribution over tokens conditional on their human preference scores given by a reward model. Conditional training reduces the rate of undesirable content by up to an order of magnitude, both when generating without a prompt and with an adversarially-chosen prompt. Moreover, conditional training maintains the downstream task performance of standard LM pretraining, both before and after task-specific finetuning. Pretraining with human feedback results in much better preference satisfaction than standard LM pretraining followed by finetuning with feedback, i.e., learning and then unlearning undesirable behavior. Our results suggest that we should move beyond imitation learning when pretraining LMs and incorporate human preferences from the start of training.
What Do NLP Researchers Believe? Results of the NLP Community Metasurvey
Aug 26, 2022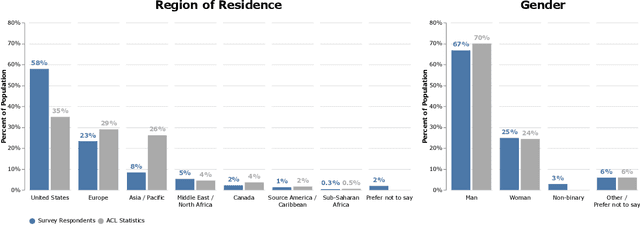

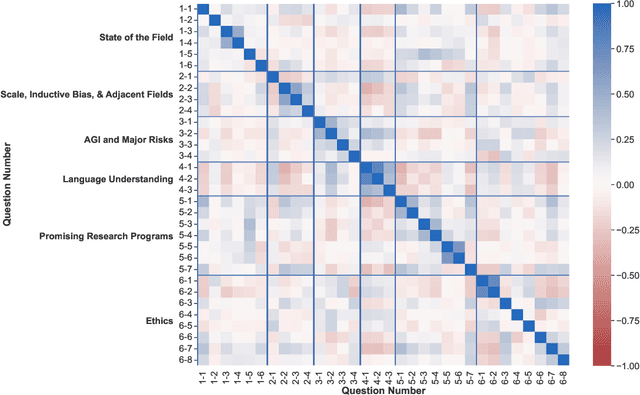
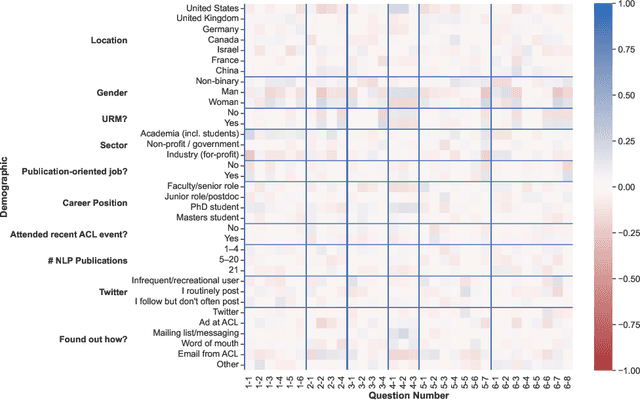
We present the results of the NLP Community Metasurvey. Run from May to June 2022, the survey elicited opinions on controversial issues, including industry influence in the field, concerns about AGI, and ethics. Our results put concrete numbers to several controversies: For example, respondents are split almost exactly in half on questions about the importance of artificial general intelligence, whether language models understand language, and the necessity of linguistic structure and inductive bias for solving NLP problems. In addition, the survey posed meta-questions, asking respondents to predict the distribution of survey responses. This allows us not only to gain insight on the spectrum of beliefs held by NLP researchers, but also to uncover false sociological beliefs where the community's predictions don't match reality. We find such mismatches on a wide range of issues. Among other results, the community greatly overestimates its own belief in the usefulness of benchmarks and the potential for scaling to solve real-world problems, while underestimating its own belief in the importance of linguistic structure, inductive bias, and interdisciplinary science.
Beyond the Imitation Game: Quantifying and extrapolating the capabilities of language models
Jun 10, 2022Language models demonstrate both quantitative improvement and new qualitative capabilities with increasing scale. Despite their potentially transformative impact, these new capabilities are as yet poorly characterized. In order to inform future research, prepare for disruptive new model capabilities, and ameliorate socially harmful effects, it is vital that we understand the present and near-future capabilities and limitations of language models. To address this challenge, we introduce the Beyond the Imitation Game benchmark (BIG-bench). BIG-bench currently consists of 204 tasks, contributed by 442 authors across 132 institutions. Task topics are diverse, drawing problems from linguistics, childhood development, math, common-sense reasoning, biology, physics, social bias, software development, and beyond. BIG-bench focuses on tasks that are believed to be beyond the capabilities of current language models. We evaluate the behavior of OpenAI's GPT models, Google-internal dense transformer architectures, and Switch-style sparse transformers on BIG-bench, across model sizes spanning millions to hundreds of billions of parameters. In addition, a team of human expert raters performed all tasks in order to provide a strong baseline. Findings include: model performance and calibration both improve with scale, but are poor in absolute terms (and when compared with rater performance); performance is remarkably similar across model classes, though with benefits from sparsity; tasks that improve gradually and predictably commonly involve a large knowledge or memorization component, whereas tasks that exhibit "breakthrough" behavior at a critical scale often involve multiple steps or components, or brittle metrics; social bias typically increases with scale in settings with ambiguous context, but this can be improved with prompting.
SQuALITY: Building a Long-Document Summarization Dataset the Hard Way
May 23, 2022

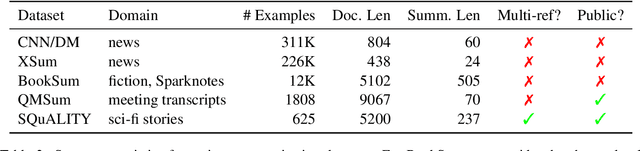

Summarization datasets are often assembled either by scraping naturally occurring public-domain summaries -- which are nearly always in difficult-to-work-with technical domains -- or by using approximate heuristics to extract them from everyday text -- which frequently yields unfaithful summaries. In this work, we turn to a slower but more straightforward approach to developing summarization benchmark data: We hire highly-qualified contractors to read stories and write original summaries from scratch. To amortize reading time, we collect five summaries per document, with the first giving an overview and the subsequent four addressing specific questions. We use this protocol to collect SQuALITY, a dataset of question-focused summaries built on the same public-domain short stories as the multiple-choice dataset QuALITY (Pang et al., 2021). Experiments with state-of-the-art summarization systems show that our dataset is challenging and that existing automatic evaluation metrics are weak indicators of quality.
Training Language Models with Natural Language Feedback
May 02, 2022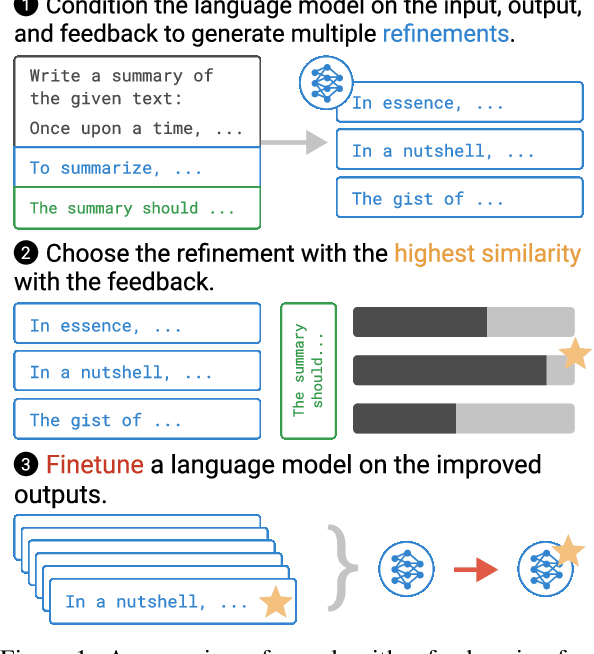
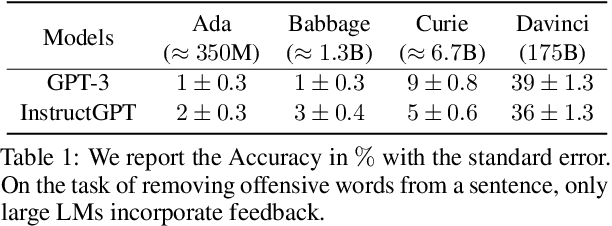
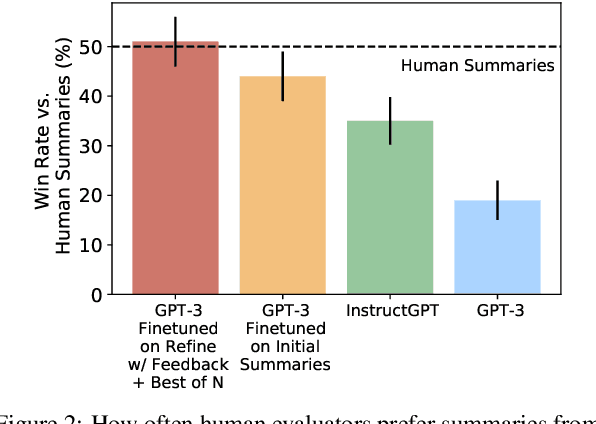
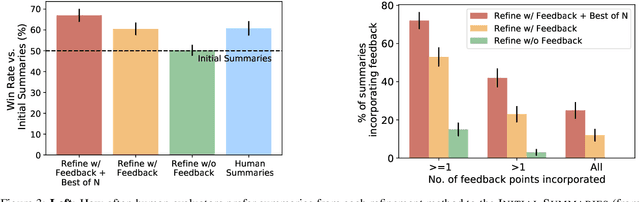
Pretrained language models often do not perform tasks in ways that are in line with our preferences, e.g., generating offensive text or factually incorrect summaries. Recent work approaches the above issue by learning from a simple form of human evaluation: comparisons between pairs of model-generated task outputs. Comparison feedback conveys limited information about human preferences per human evaluation. Here, we propose to learn from natural language feedback, which conveys more information per human evaluation. We learn from language feedback on model outputs using a three-step learning algorithm. First, we condition the language model on the initial output and feedback to generate many refinements. Second, we choose the refinement with the highest similarity to the feedback. Third, we finetune a language model to maximize the likelihood of the chosen refinement given the input. In synthetic experiments, we first evaluate whether language models accurately incorporate feedback to produce refinements, finding that only large language models (175B parameters) do so. Using only 100 samples of human-written feedback, our learning algorithm finetunes a GPT-3 model to roughly human-level summarization.
Teaching BERT to Wait: Balancing Accuracy and Latency for Streaming Disfluency Detection
May 02, 2022
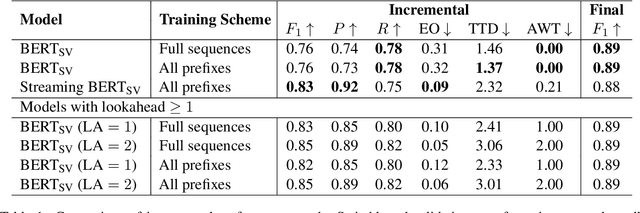
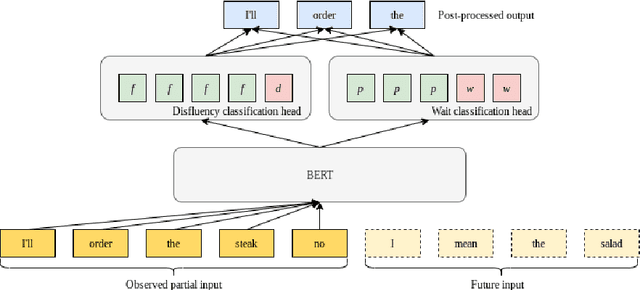
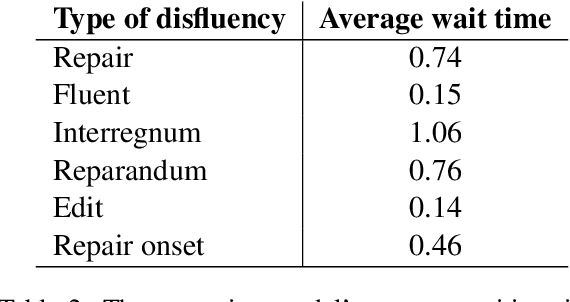
In modern interactive speech-based systems, speech is consumed and transcribed incrementally prior to having disfluencies removed. This post-processing step is crucial for producing clean transcripts and high performance on downstream tasks (e.g. machine translation). However, most current state-of-the-art NLP models such as the Transformer operate non-incrementally, potentially causing unacceptable delays. We propose a streaming BERT-based sequence tagging model that, combined with a novel training objective, is capable of detecting disfluencies in real-time while balancing accuracy and latency. This is accomplished by training the model to decide whether to immediately output a prediction for the current input or to wait for further context. Essentially, the model learns to dynamically size its lookahead window. Our results demonstrate that our model produces comparably accurate predictions and does so sooner than our baselines, with lower flicker. Furthermore, the model attains state-of-the-art latency and stability scores when compared with recent work on incremental disfluency detection.
Single-Turn Debate Does Not Help Humans Answer Hard Reading-Comprehension Questions
Apr 13, 2022
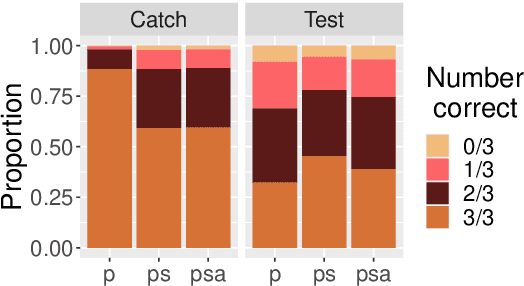
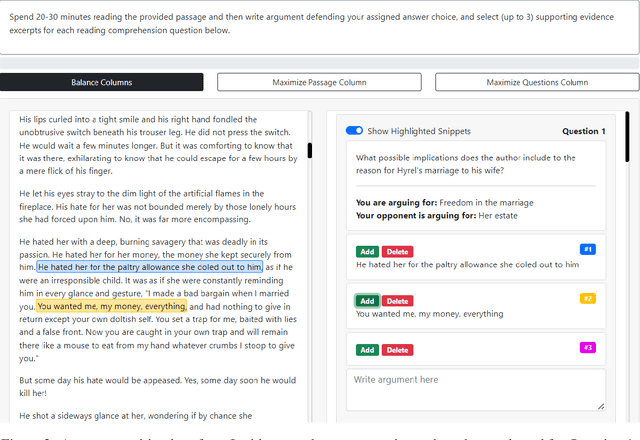
Current QA systems can generate reasonable-sounding yet false answers without explanation or evidence for the generated answer, which is especially problematic when humans cannot readily check the model's answers. This presents a challenge for building trust in machine learning systems. We take inspiration from real-world situations where difficult questions are answered by considering opposing sides (see Irving et al., 2018). For multiple-choice QA examples, we build a dataset of single arguments for both a correct and incorrect answer option in a debate-style set-up as an initial step in training models to produce explanations for two candidate answers. We use long contexts -- humans familiar with the context write convincing explanations for pre-selected correct and incorrect answers, and we test if those explanations allow humans who have not read the full context to more accurately determine the correct answer. We do not find that explanations in our set-up improve human accuracy, but a baseline condition shows that providing human-selected text snippets does improve accuracy. We use these findings to suggest ways of improving the debate set up for future data collection efforts.
QuALITY: Question Answering with Long Input Texts, Yes!
Dec 16, 2021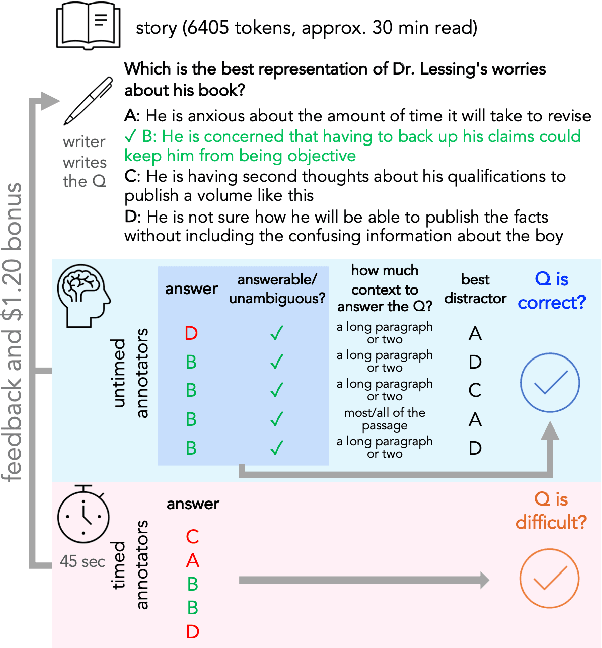


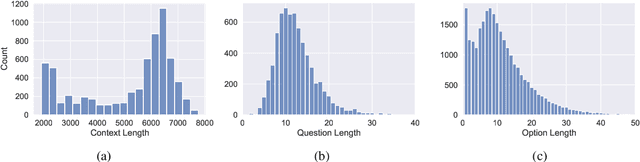
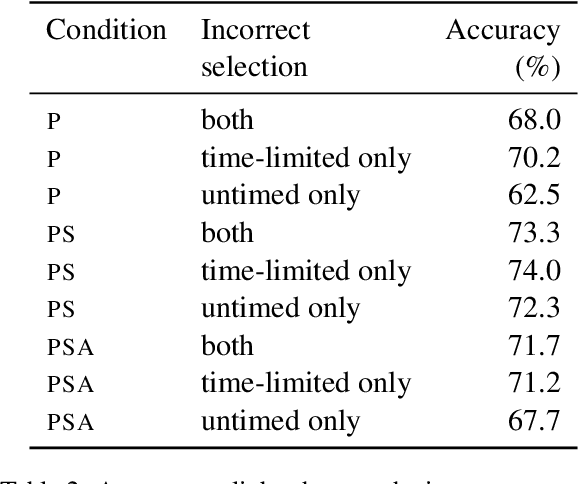
To enable building and testing models on long-document comprehension, we introduce QuALITY, a multiple-choice QA dataset with context passages in English that have an average length of about 5,000 tokens, much longer than typical current models can process. Unlike in prior work with passages, our questions are written and validated by contributors who have read the entire passage, rather than relying on summaries or excerpts. In addition, only half of the questions are answerable by annotators working under tight time constraints, indicating that skimming and simple search are not enough to consistently perform well. Current models perform poorly on this task (55.4%) and significantly lag behind human performance (93.5%).