 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Cookbook of Self-Supervised Learning
Apr 24, 2023



Self-supervised learning, dubbed the dark matter of intelligence, is a promising path to advance machine learning. Yet, much like cooking, training SSL methods is a delicate art with a high barrier to entry. While many components are familiar, successfully training a SSL method involves a dizzying set of choices from the pretext tasks to training hyper-parameters. Our goal is to lower the barrier to entry into SSL research by laying the foundations and latest SSL recipes in the style of a cookbook. We hope to empower the curious researcher to navigate the terrain of methods, understand the role of the various knobs, and gain the know-how required to explore how delicious SSL can be.
The No Free Lunch Theorem, Kolmogorov Complexity, and the Role of Inductive Biases in Machine Learning
Apr 11, 2023No free lunch theorems for supervised learning state that no learner can solve all problems or that all learners achieve exactly the same accuracy on average over a uniform distribution on learning problems. Accordingly, these theorems are often referenced in support of the notion that individual problems require specially tailored inductive biases. While virtually all uniformly sampled datasets have high complexity, real-world problems disproportionately generate low-complexity data, and we argue that neural network models share this same preference, formalized using Kolmogorov complexity. Notably, we show that architectures designed for a particular domain, such as computer vision, can compress datasets on a variety of seemingly unrelated domains. Our experiments show that pre-trained and even randomly initialized language models prefer to generate low-complexity sequences. Whereas no free lunch theorems seemingly indicate that individual problems require specialized learners, we explain how tasks that often require human intervention such as picking an appropriately sized model when labeled data is scarce or plentiful can be automated into a single learning algorithm. These observations justify the trend in deep learning of unifying seemingly disparate problems with an increasingly small set of machine learning models.
Fortuna: A Library for Uncertainty Quantification in Deep Learning
Feb 08, 2023We present Fortuna, an open-source library for uncertainty quantification in deep learning. Fortuna supports a range of calibration techniques, such as conformal prediction that can be applied to any trained neural network to generate reliable uncertainty estimates, and scalable Bayesian inference methods that can be applied to Flax-based deep neural networks trained from scratch for improved uncertainty quantification and accuracy. By providing a coherent framework for advanced uncertainty quantification methods, Fortuna simplifies the process of benchmarking and helps practitioners build robust AI systems.
Learning Multimodal Data Augmentation in Feature Space
Dec 29, 2022



The ability to jointly learn from multiple modalities, such as text, audio, and visual data, is a defining feature of intelligent systems. While there have been promising advances in designing neural networks to harness multimodal data, the enormous success of data augmentation currently remains limited to single-modality tasks like image classification. Indeed, it is particularly difficult to augment each modality while preserving the overall semantic structure of the data; for example, a caption may no longer be a good description of an image after standard augmentations have been applied, such as translation. Moreover, it is challenging to specify reasonable transformations that are not tailored to a particular modality. In this paper, we introduce LeMDA, Learning Multimodal Data Augmentation, an easy-to-use method that automatically learns to jointly augment multimodal data in feature space, with no constraints on the identities of the modalities or the relationship between modalities. We show that LeMDA can (1) profoundly improve the performance of multimodal deep learning architectures, (2) apply to combinations of modalities that have not been previously considered, and (3) achieve state-of-the-art results on a wide range of applications comprised of image, text, and tabular data.
What do Vision Transformers Learn? A Visual Exploration
Dec 13, 2022



Vision transformers (ViTs) are quickly becoming the de-facto architecture for computer vision, yet we understand very little about why they work and what they learn. While existing studies visually analyze the mechanisms of convolutional neural networks, an analogous exploration of ViTs remains challenging. In this paper, we first address the obstacles to performing visualizations on ViTs. Assisted by these solutions, we observe that neurons in ViTs trained with language model supervision (e.g., CLIP) are activated by semantic concepts rather than visual features. We also explore the underlying differences between ViTs and CNNs, and we find that transformers detect image background features, just like their convolutional counterparts, but their predictions depend far less on high-frequency information. On the other hand, both architecture types behave similarly in the way features progress from abstract patterns in early layers to concrete objects in late layers. In addition, we show that ViTs maintain spatial information in all layers except the final layer. In contrast to previous works, we show that the last layer most likely discards the spatial information and behaves as a learned global pooling operation. Finally, we conduct large-scale visualizations on a wide range of ViT variants, including DeiT, CoaT, ConViT, PiT, Swin, and Twin, to validate the effectiveness of our method.
Chroma-VAE: Mitigating Shortcut Learning with Generative Classifiers
Nov 28, 2022



Deep neural networks are susceptible to shortcut learning, using simple features to achieve low training loss without discovering essential semantic structure. Contrary to prior belief, we show that generative models alone are not sufficient to prevent shortcut learning, despite an incentive to recover a more comprehensive representation of the data than discriminative approaches. However, we observe that shortcuts are preferentially encoded with minimal information, a fact that generative models can exploit to mitigate shortcut learning. In particular, we propose Chroma-VAE, a two-pronged approach where a VAE classifier is initially trained to isolate the shortcut in a small latent subspace, allowing a secondary classifier to be trained on the complementary, shortcut-free latent subspace. In addition to demonstrating the efficacy of Chroma-VAE on benchmark and real-world shortcut learning tasks, our work highlights the potential for manipulating the latent space of generative classifiers to isolate or interpret specific correlations.
PAC-Bayes Compression Bounds So Tight That They Can Explain Generalization
Nov 24, 2022



While there has been progress in developing non-vacuous generalization bounds for deep neural networks, these bounds tend to be uninformative about why deep learning works. In this paper, we develop a compression approach based on quantizing neural network parameters in a linear subspace, profoundly improving on previous results to provide state-of-the-art generalization bounds on a variety of tasks, including transfer learning. We use these tight bounds to better understand the role of model size, equivariance, and the implicit biases of optimization, for generalization in deep learning. Notably, we find large models can be compressed to a much greater extent than previously known, encapsulating Occam's razor. We also argue for data-independent bounds in explaining generalization.
Bayesian Optimization with Conformal Coverage Guarantees
Oct 25, 2022



Bayesian optimization is a coherent, ubiquitous approach to decision-making under uncertainty, with applications including multi-arm bandits, active learning, and black-box optimization. Bayesian optimization selects decisions (i.e. objective function queries) with maximal expected utility with respect to the posterior distribution of a Bayesian model, which quantifies reducible, epistemic uncertainty about query outcomes. In practice, subjectively implausible outcomes can occur regularly for two reasons: 1) model misspecification and 2) covariate shift. Conformal prediction is an uncertainty quantification method with coverage guarantees even for misspecified models and a simple mechanism to correct for covariate shift. We propose conformal Bayesian optimization, which directs queries towards regions of search space where the model predictions have guaranteed validity, and investigate its behavior on a suite of black-box optimization tasks and tabular ranking tasks. In many cases we find that query coverage can be significantly improved without harming sample-efficiency.
K-SAM: Sharpness-Aware Minimization at the Speed of SGD
Oct 23, 2022Sharpness-Aware Minimization (SAM) has recently emerged as a robust technique for improving the accuracy of deep neural networks. However, SAM incurs a high computational cost in practice, requiring up to twice as much computation as vanilla SGD. The computational challenge posed by SAM arises because each iteration requires both ascent and descent steps and thus double the gradient computations. To address this challenge, we propose to compute gradients in both stages of SAM on only the top-k samples with highest loss. K-SAM is simple and extremely easy-to-implement while providing significant generalization boosts over vanilla SGD at little to no additional cost.
On Feature Learning in the Presence of Spurious Correlations
Oct 20, 2022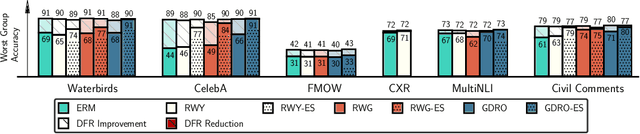
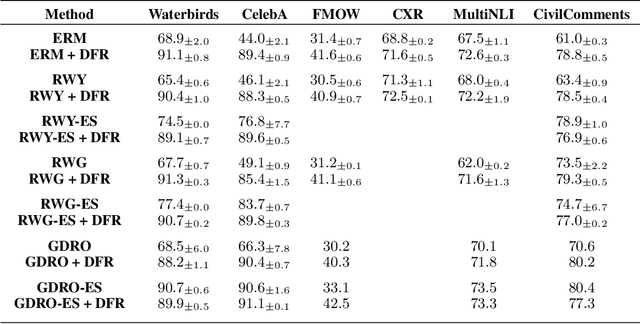
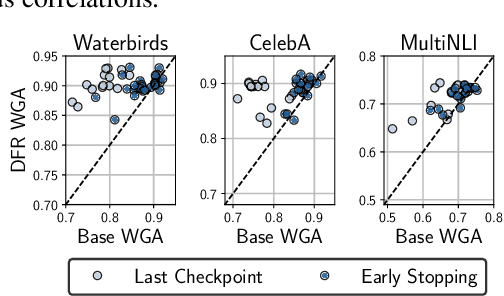
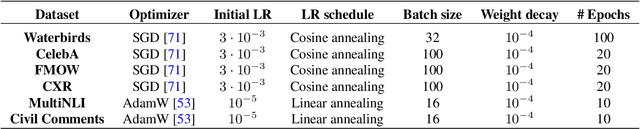
Deep classifiers are known to rely on spurious features $\unicode{x2013}$ patterns which are correlated with the target on the training data but not inherently relevant to the learning problem, such as the image backgrounds when classifying the foregrounds. In this paper we evaluate the amount of information about the core (non-spurious) features that can be decoded from the representations learned by standard empirical risk minimization (ERM) and specialized group robustness training. Following recent work on Deep Feature Reweighting (DFR), we evaluate the feature representations by re-training the last layer of the model on a held-out set where the spurious correlation is broken. On multiple vision and NLP problems, we show that the features learned by simple ERM are highly competitive with the features learned by specialized group robustness methods targeted at reducing the effect of spurious correlations. Moreover, we show that the quality of learned feature representations is greatly affected by the design decisions beyond the training method, such as the model architecture and pre-training strategy. On the other hand, we find that strong regularization is not necessary for learning high quality feature representations. Finally, using insights from our analysis, we significantly improve upon the best results reported in the literature on the popular Waterbirds, CelebA hair color prediction and WILDS-FMOW problems, achieving 97%, 92% and 50% worst-group accuracies, respectively.