 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFixing the train-test resolution discrepancy
Jul 19, 2019
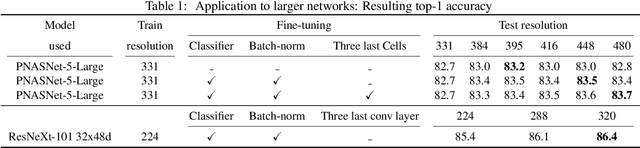
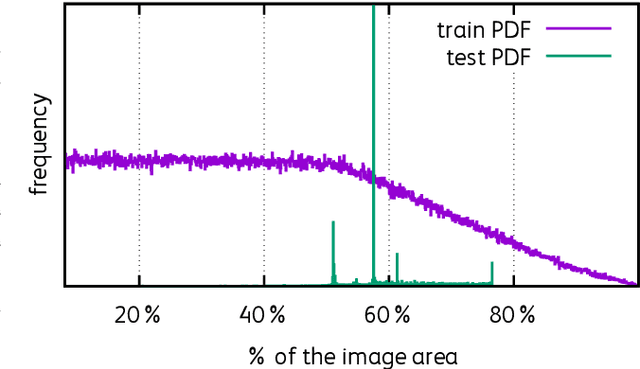
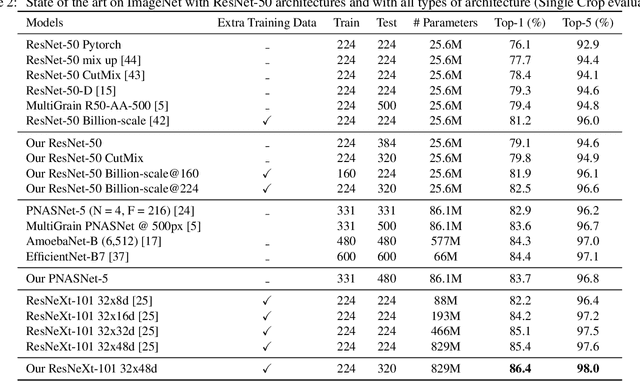
Data-augmentation is key to the training of neural networks for image classification. This paper first shows that existing augmentations induce a significant discrepancy between the typical size of the objects seen by the classifier at train and test time. We experimentally validate that, for a target test resolution, using a lower train resolution offers better classification at test time. We then propose a simple yet effective and efficient strategy to optimize the classifier performance when the train and test resolutions differ. It involves only a computationally cheap fine-tuning of the network at the test resolution. This enables training strong classifiers using small training images. For instance, we obtain 77.1% top-1 accuracy on ImageNet with a ResNet-50 trained on 128x128 images, and 79.8% with one trained on 224x224 image. In addition, if we use extra training data we get 82.5% with the ResNet-50 train with 224x224 images. Conversely, when training a ResNeXt-101 32x48d pre-trained in weakly-supervised fashion on 940 million public images at resolution 224x224 and further optimizing for test resolution 320x320, we obtain a test top-1 accuracy of 86.4% (top-5: 98.0%) (single-crop). To the best of our knowledge this is the highest ImageNet single-crop, top-1 and top-5 accuracy to date.
Learning Landmarks from Unaligned Data using Image Translation
Jul 03, 2019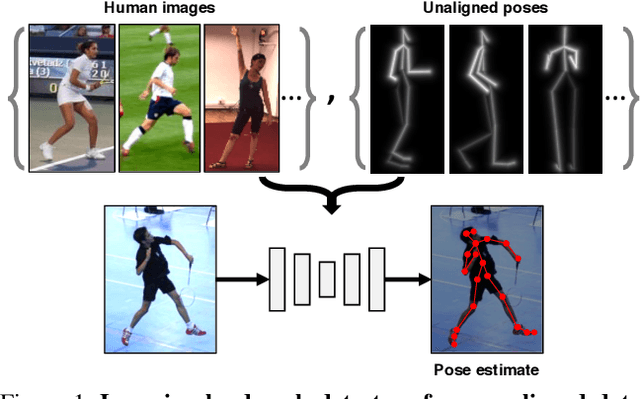
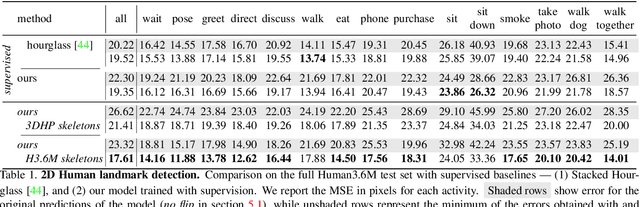

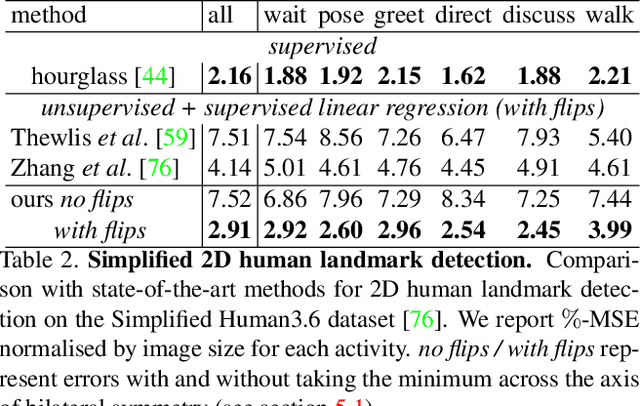
We introduce a method for learning landmark detectors from unlabelled video frames and unpaired labels. This allows us to learn a detector from a large collection of raw videos given only a few example annotations harvested from existing data or motion capture. We achieve this by formulating the landmark detection task as one of image translation, learning to map an image of the object to an image of its landmarks, represented as a skeleton. The advantage is that this translation problem can then be tackled by CycleGAN. However, we show that a naive application of CycleGAN confounds appearance and pose information, with suboptimal keypoint detection performance. We solve this problem by introducing an analytical and differentiable renderer for the skeleton image so that no appearance information can be leaked in the skeleton. Then, since cycle consistency requires to reconstruct the input image from the skeleton, we supply the appearance information thus removed by conditioning the generator with a second image of the same object (e.g. another frame from a video). Furthermore, while CycleGAN uses two cycle consistency constraints, we show that the second one is detrimental in this application and we discard it, significantly simplifying the model. We show that these modifications improve the quality of the learned detector leading to state-of-the-art unsupervised landmark detection performance in a number of challenging human pose and facial landmark detection benchmarks.
Slim DensePose: Thrifty Learning from Sparse Annotations and Motion Cues
Jun 13, 2019
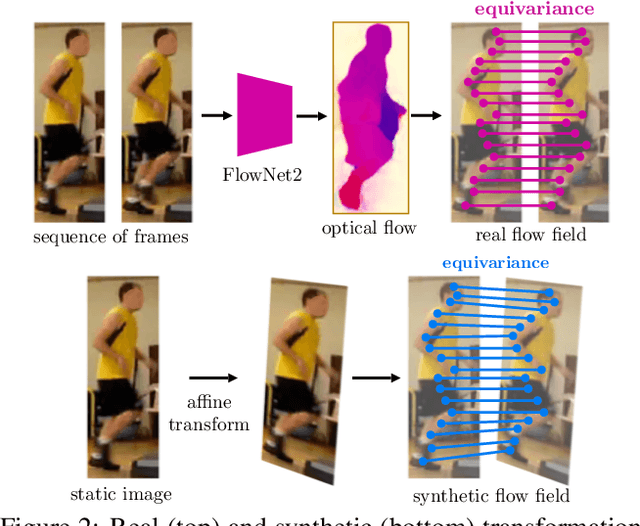
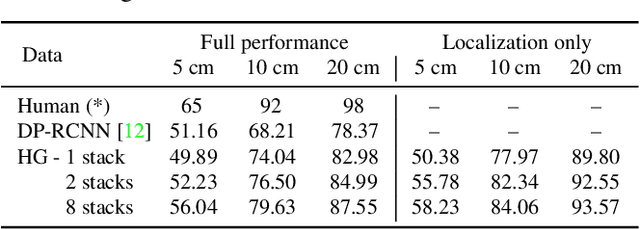

DensePose supersedes traditional landmark detectors by densely mapping image pixels to body surface coordinates. This power, however, comes at a greatly increased annotation time, as supervising the model requires to manually label hundreds of points per pose instance. In this work, we thus seek methods to significantly slim down the DensePose annotations, proposing more efficient data collection strategies. In particular, we demonstrate that if annotations are collected in video frames, their efficacy can be multiplied for free by using motion cues. To explore this idea, we introduce DensePose-Track, a dataset of videos where selected frames are annotated in the traditional DensePose manner. Then, building on geometric properties of the DensePose mapping, we use the video dynamic to propagate ground-truth annotations in time as well as to learn from Siamese equivariance constraints. Having performed exhaustive empirical evaluation of various data annotation and learning strategies, we demonstrate that doing so can deliver significantly improved pose estimation results over strong baselines. However, despite what is suggested by some recent works, we show that merely synthesizing motion patterns by applying geometric transformations to isolated frames is significantly less effective, and that motion cues help much more when they are extracted from videos.
Photo-Geometric Autoencoding to Learn 3D Objects from Unlabelled Images
Jun 04, 2019
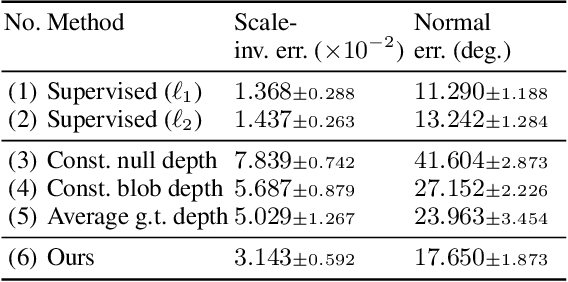
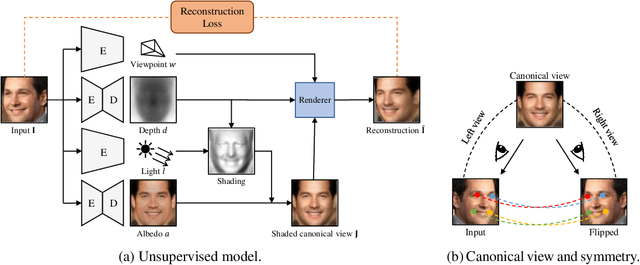

We show that generative models can be used to capture visual geometry constraints statistically. We use this fact to infer the 3D shape of object categories from raw single-view images. Differently from prior work, we use no external supervision, nor do we use multiple views or videos of the objects. We achieve this by a simple reconstruction task, exploiting the symmetry of the objects' shape and albedo. Specifically, given a single image of the object seen from an arbitrary viewpoint, our model predicts a symmetric canonical view, the corresponding 3D shape and a viewpoint transformation, and trains with the goal of reconstructing the input view, resembling an auto-encoder. Our experiments show that this method can recover the 3D shape of human faces, cat faces, and cars from single view images, without supervision. On benchmarks, we demonstrate superior accuracy compared to other methods that use supervision at the level of 2D image correspondences.
Unsupervised Intuitive Physics from Past Experiences
May 26, 2019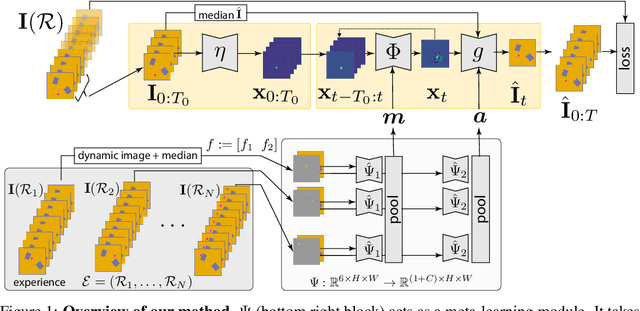
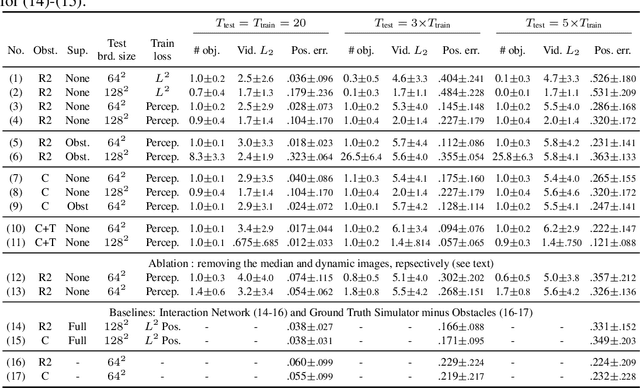


We are interested in learning models of intuitive physics similar to the ones that animals use for navigation, manipulation and planning. In addition to learning general physical principles, however, we are also interested in learning ``on the fly'', from a few experiences, physical properties specific to new environments. We do all this in an unsupervised manner, using a meta-learning formulation where the goal is to predict videos containing demonstrations of physical phenomena, such as objects moving and colliding with a complex background. We introduce the idea of summarizing past experiences in a very compact manner, in our case using dynamic images, and show that this can be used to solve the problem well and efficiently. Empirically, we show via extensive experiments and ablation studies, that our model learns to perform physical predictions that generalize well in time and space, as well as to a variable number of interacting physical objects.
Semi-Supervised Learning with Scarce Annotations
May 21, 2019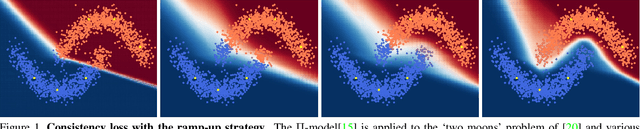

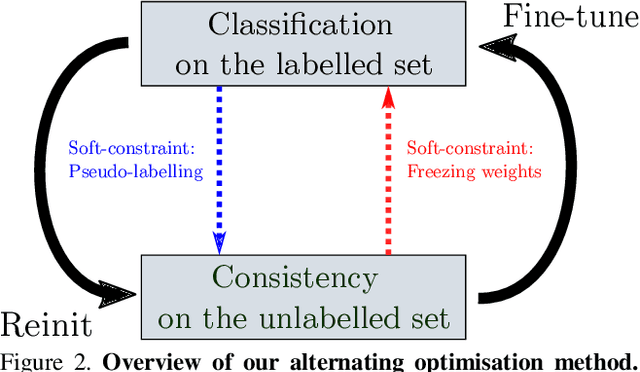

While semi-supervised learning (SSL) algorithms provide an efficient way to make use of both labelled and unlabelled data, they generally struggle when the number of annotated samples is very small. In this work, we consider the problem of SSL multi-class classification with very few labelled instances. We introduce two key ideas. The first is a simple but effective one: we leverage the power of transfer learning among different tasks and self-supervision to initialize a good representation of the data without making use of any label. The second idea is a new algorithm for SSL that can exploit well such a pre-trained representation. The algorithm works by alternating two phases, one fitting the labelled points and one fitting the unlabelled ones, with carefully-controlled information flow between them. The benefits are greatly reducing overfitting of the labelled data and avoiding issue with balancing labelled and unlabelled losses during training. We show empirically that this method can successfully train competitive models with as few as 10 labelled data points per class. More in general, we show that the idea of bootstrapping features using self-supervised learning always improves SSL on standard benchmarks. We show that our algorithm works increasingly well compared to other methods when refining from other tasks or datasets.
Surprising Effectiveness of Few-Image Unsupervised Feature Learning
Apr 30, 2019

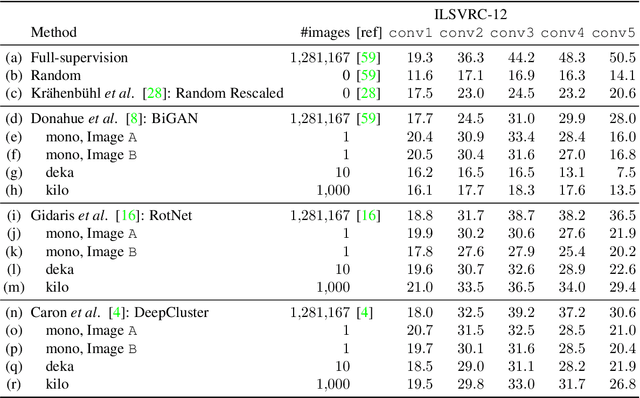
State-of-the-art methods for unsupervised representation learning can train well the first few layers of standard convolutional neural networks, but they are not as good as supervised learning for deeper layers. This is likely due to the generic and relatively simple nature of shallow layers; and yet, these approaches are applied to millions of images, scalability being advertised as their major advantage since unlabelled data is cheap to collect. In this paper we question this practice and ask whether so many images are actually needed to learn the layers for which unsupervised learning works best. Our main result is that a few or even a single image together with strong data augmentation are sufficient to nearly saturate performance. Specifically, we provide an analysis for three different self-supervised feature learning methods (BiGAN, RotNet, DeepCluster) vs number of training images (1, 10, 1000) and show that we can top the accuracy for the first two convolutional layers of common networks using just a single unlabelled training image and obtain competitive results for other layers. We further study and visualize the learned representation as a function of which (single) image is used for training. Our results are also suggestive of which type of information may be captured by shallow layers in deep networks.
MultiGrain: a unified image embedding for classes and instances
Apr 03, 2019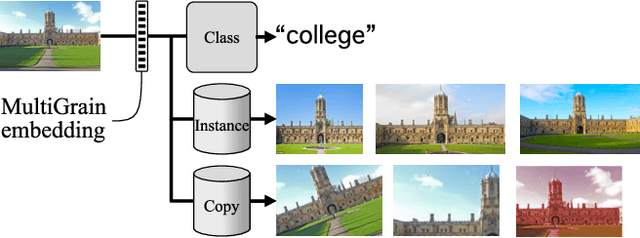
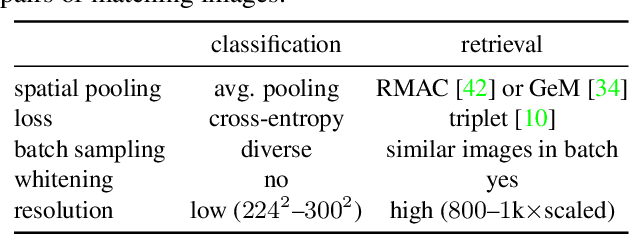
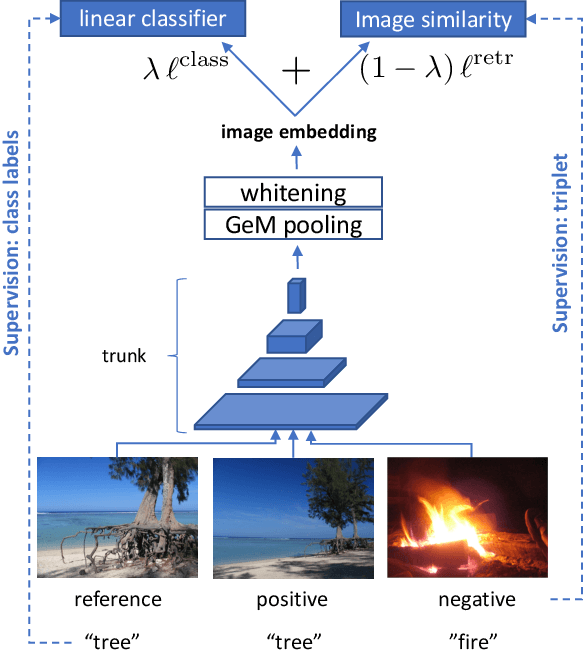
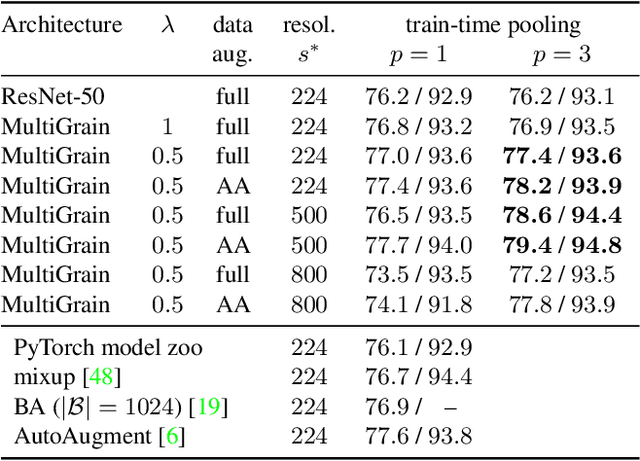
MultiGrain is a network architecture producing compact vector representations that are suited both for image classification and particular object retrieval. It builds on a standard classification trunk. The top of the network produces an embedding containing coarse and fine-grained information, so that images can be recognized based on the object class, particular object, or if they are distorted copies. Our joint training is simple: we minimize a cross-entropy loss for classification and a ranking loss that determines if two images are identical up to data augmentation, with no need for additional labels. A key component of MultiGrain is a pooling layer that takes advantage of high-resolution images with a network trained at a lower resolution. When fed to a linear classifier, the learned embeddings provide state-of-the-art classification accuracy. For instance, we obtain 79.4% top-1 accuracy with a ResNet-50 learned on Imagenet, which is a +1.8% absolute improvement over the AutoAugment method. When compared with the cosine similarity, the same embeddings perform on par with the state-of-the-art for image retrieval at moderate resolutions.
Gather-Excite: Exploiting Feature Context in Convolutional Neural Networks
Oct 29, 2018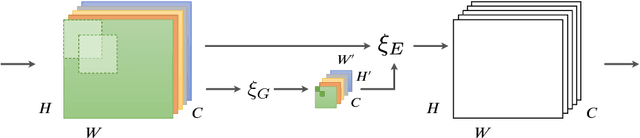
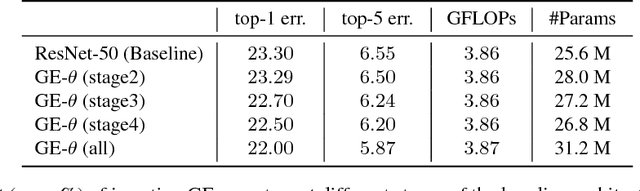
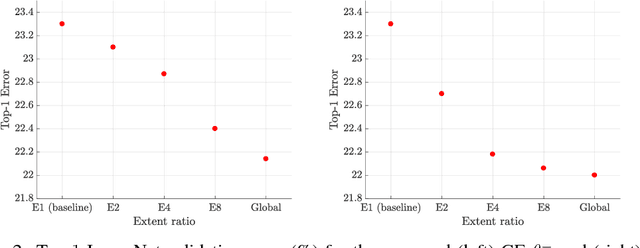
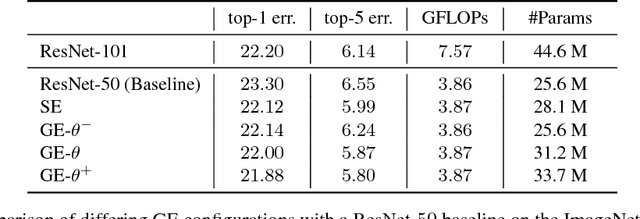
While the use of bottom-up local operators in convolutional neural networks (CNNs) matches well some of the statistics of natural images, it may also prevent such models from capturing contextual long-range feature interactions. In this work, we propose a simple, lightweight approach for better context exploitation in CNNs. We do so by introducing a pair of operators: gather, which efficiently aggregates feature responses from a large spatial extent, and excite, which redistributes the pooled information to local features. The operators are cheap, both in terms of number of added parameters and computational complexity, and can be integrated directly in existing architectures to improve their performance. Experiments on several datasets show that gather-excite can bring benefits comparable to increasing the depth of a CNN at a fraction of the cost. For example, we find ResNet-50 with gather-excite operators is able to outperform its 101-layer counterpart on ImageNet with no additional learnable parameters. We also propose a parametric gather-excite operator pair which yields further performance gains, relate it to the recently-introduced Squeeze-and-Excitation Networks, and analyse the effects of these changes to the CNN feature activation statistics.
Learning to Read by Spelling: Towards Unsupervised Text Recognition
Sep 23, 2018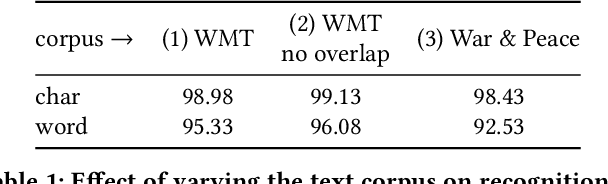
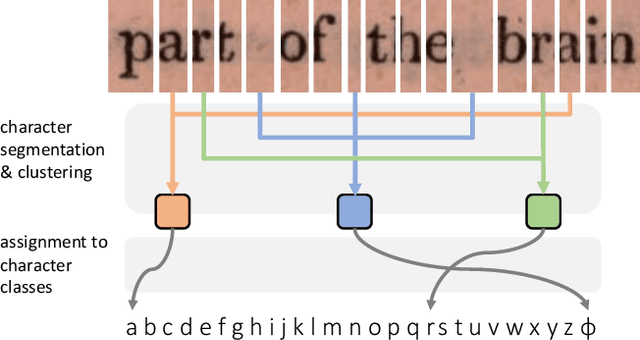


This work presents a method for visual text recognition without using any paired supervisory data. We formulate the text recognition task as one of aligning the conditional distribution of strings predicted from given text images, with lexically valid strings sampled from target corpora. This enables fully automated, and unsupervised learning from just line-level text-images, and unpaired text-string samples, obviating the need for large aligned datasets. We present detailed analysis for various aspects of the proposed method, namely - (1) the impact of the length of training sequences on convergence, (2) relation between character frequencies and the order in which they are learnt, and (3) demonstrate the generalisation ability of our recognition network to inputs of arbitrary lengths. Finally, we demonstrate excellent text recognition accuracy on both synthetically generated text images, and scanned images of real printed books, using no labelled training examples.