 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBayesian Inference with Certifiable Adversarial Robustness
Feb 23, 2021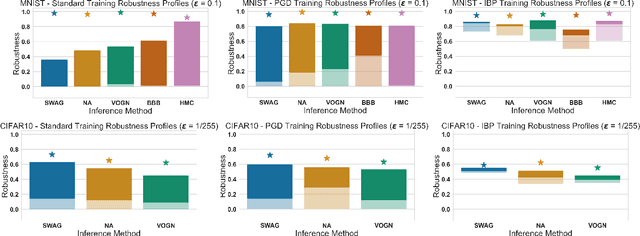
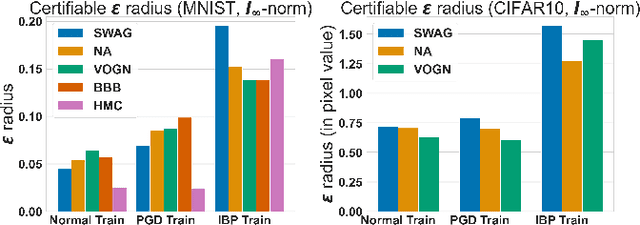
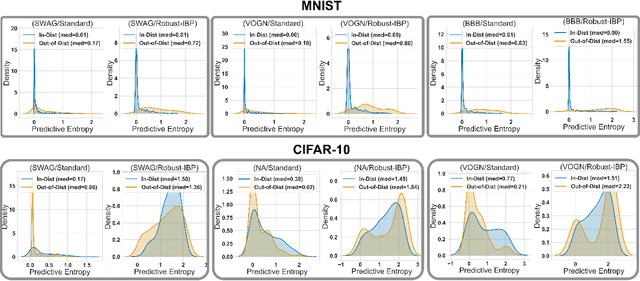
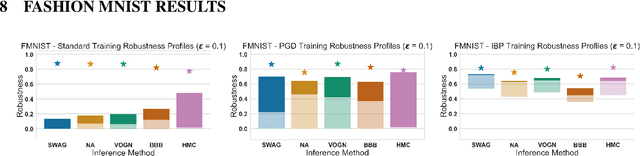
We consider adversarial training of deep neural networks through the lens of Bayesian learning, and present a principled framework for adversarial training of Bayesian Neural Networks (BNNs) with certifiable guarantees. We rely on techniques from constraint relaxation of non-convex optimisation problems and modify the standard cross-entropy error model to enforce posterior robustness to worst-case perturbations in $\epsilon$-balls around input points. We illustrate how the resulting framework can be combined with methods commonly employed for approximate inference of BNNs. In an empirical investigation, we demonstrate that the presented approach enables training of certifiably robust models on MNIST, FashionMNIST and CIFAR-10 and can also be beneficial for uncertainty calibration. Our method is the first to directly train certifiable BNNs, thus facilitating their deployment in safety-critical applications.
Probabilistic Safety for Bayesian Neural Networks
Apr 21, 2020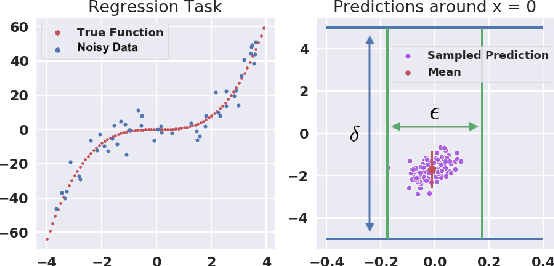
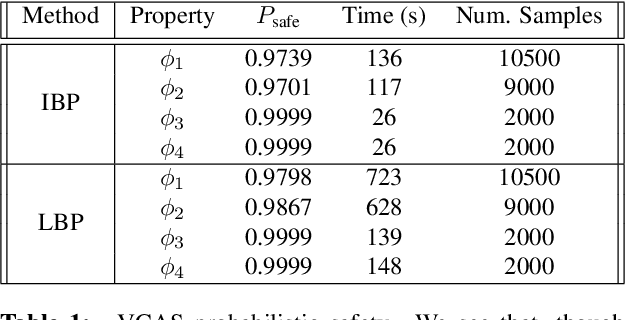
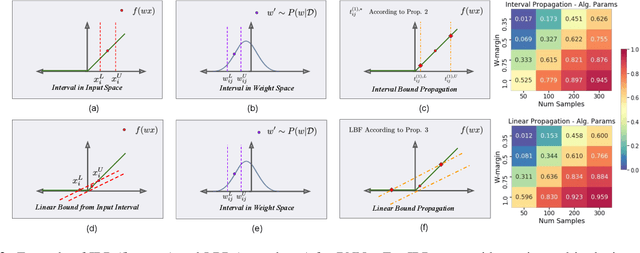
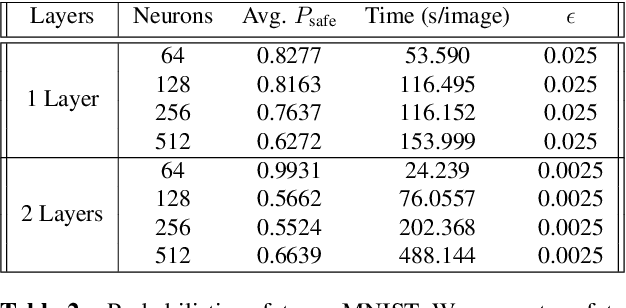
We study probabilistic safety for Bayesian Neural Networks (BNNs) under adversarial input perturbations. Given a compact set of input points, T \subseteq R^m, we study the probability w.r.t. the BNN posterior that all the points in T are mapped to the same, given region S in the output space. In particular, this can be used to evaluate the probability that a network sampled from the BNN is vulnerable to adversarial attacks. We rely on relaxation techniques from non-convex optimization to develop a method for computing a lower bound on probabilistic safety for BNNs, deriving explicit procedures for the case of interval and linear function propagation techniques. We apply our methods to BNNs trained on a regression task, airborne collision avoidance, and MNIST, empirically showing that our approach allows one to certify probabilistic safety of BNNs with thousands of neurons.
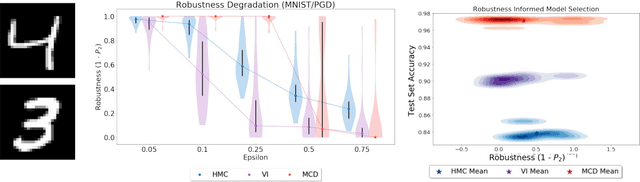
Robustness of Bayesian Neural Networks to Gradient-Based Attacks
Feb 12, 2020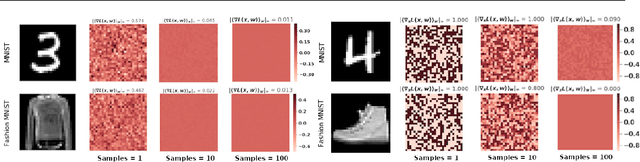
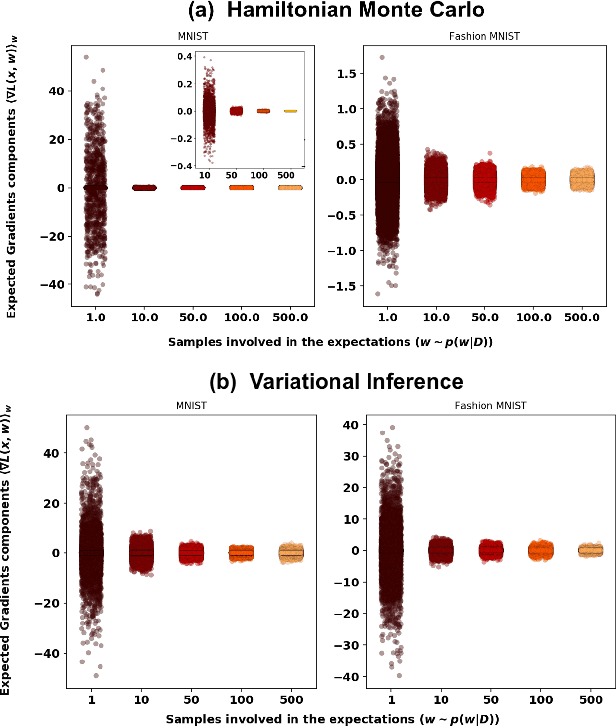
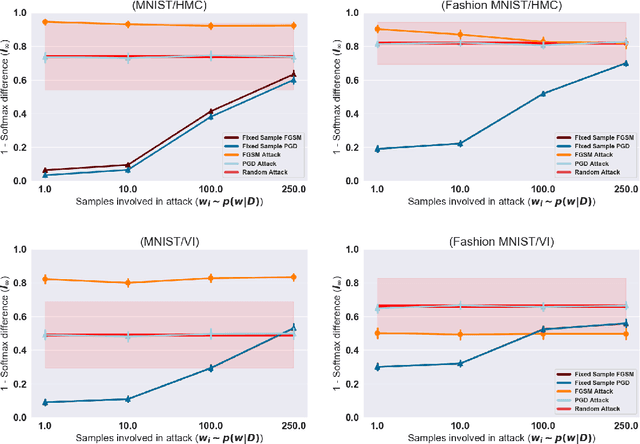
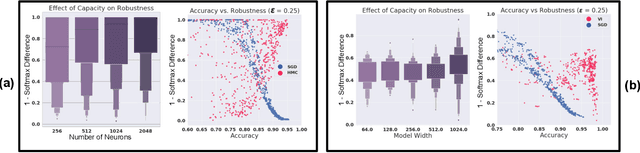
Vulnerability to adversarial attacks is one of the principal hurdles to the adoption of deep learning in safety-critical applications. Despite significant efforts, both practical and theoretical, the problem remains open. In this paper, we analyse the geometry of adversarial attacks in the large-data, overparametrized limit for Bayesian Neural Networks (BNNs). We show that, in the limit, vulnerability to gradient-based attacks arises as a result of degeneracy in the data distribution, i.e., when the data lies on a lower-dimensional submanifold of the ambient space. As a direct consequence, we demonstrate that in the limit BNN posteriors are robust to gradient-based adversarial attacks. Experimental results on the MNIST and Fashion MNIST datasets with BNNs trained with Hamiltonian Monte Carlo and Variational Inference support this line of argument, showing that BNNs can display both high accuracy and robustness to gradient based adversarial attacks.
Safety Guarantees for Planning Based on Iterative Gaussian Processes
Jan 17, 2020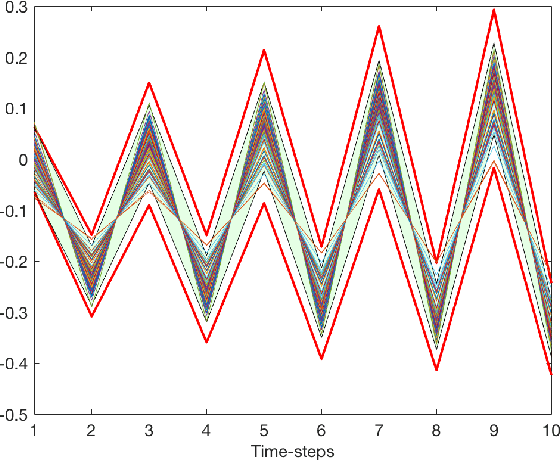

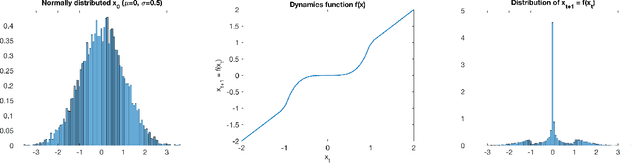
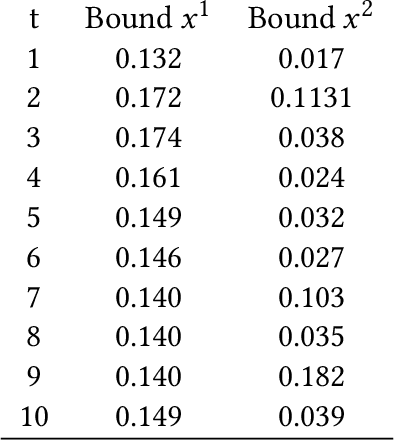
Gaussian Processes (GPs) are widely employed in control and learning because of their principled treatment of uncertainty. However, tracking uncertainty for iterative, multi-step predictions in general leads to an analytically intractable problem. While approximation methods exist, they do not come with guarantees, making it difficult to estimate their reliability and to trust their predictions. In this work, we derive formal probability error bounds for iterative prediction and planning with GPs. Building on GP properties, we bound the probability that random trajectories lie in specific regions around the predicted values. Namely, given a tolerance $\epsilon > 0 $, we compute regions around the predicted trajectory values, such that GP trajectories are guaranteed to lie inside them with probability at least $1-\epsilon$. We verify experimentally that our method tracks the predictive uncertainty correctly, even when current approximation techniques fail. Furthermore, we show how the proposed bounds can be employed within a safe reinforcement learning framework to verify the safety of candidate control policies, guiding the synthesis of provably safe controllers.
Robustness Quantification for Classification with Gaussian Processes
May 28, 2019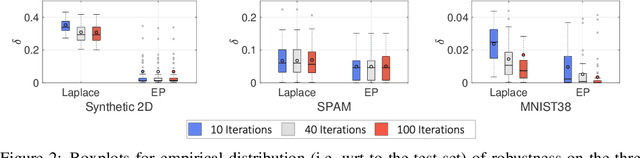
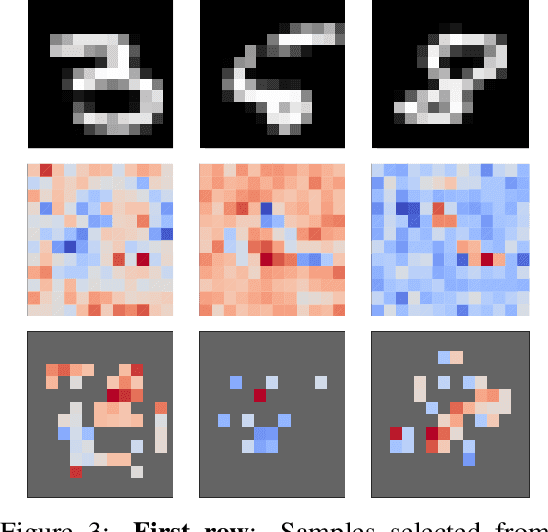
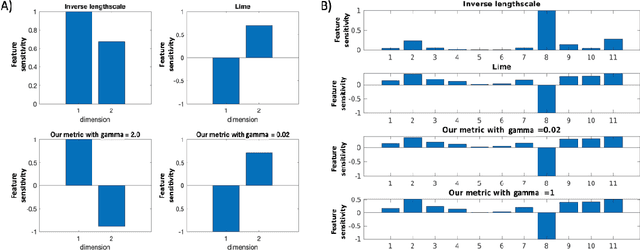
We consider Bayesian classification with Gaussian processes (GPs) and define robustness of a classifier in terms of the worst-case difference in the classification probabilities with respect to input perturbations. For a subset of the input space $T\subseteq \mathbb{R}^m$ such properties reduce to computing the infimum and supremum of the classification probabilities for all points in $T$. Unfortunately, computing the above values is very challenging, as the classification probabilities cannot be expressed analytically. Nevertheless, using the theory of Gaussian processes, we develop a framework that, for a given dataset $\mathcal{D}$, a compact set of input points $T\subseteq \mathbb{R}^m$ and an error threshold $\epsilon>0$, computes lower and upper bounds of the classification probabilities by over-approximating the exact range with an error bounded by $\epsilon$. We provide experimental comparison of several approximate inference methods for classification on tasks associated to MNIST and SPAM datasets showing that our results enable quantification of uncertainty in adversarial classification settings.
Statistical Guarantees for the Robustness of Bayesian Neural Networks
Mar 05, 2019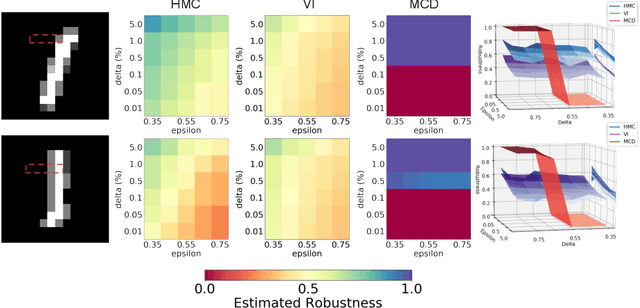
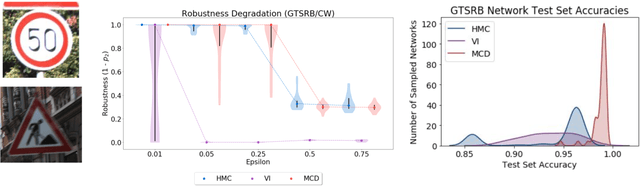
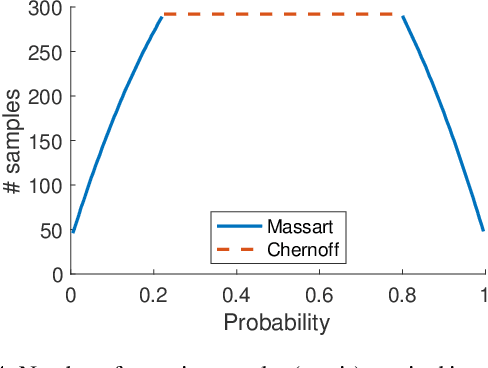
We introduce a probabilistic robustness measure for Bayesian Neural Networks (BNNs), defined as the probability that, given a test point, there exists a point within a bounded set such that the BNN prediction differs between the two. Such a measure can be used, for instance, to quantify the probability of the existence of adversarial examples. Building on statistical verification techniques for probabilistic models, we develop a framework that allows us to estimate probabilistic robustness for a BNN with statistical guarantees, i.e., with a priori error and confidence bounds. We provide experimental comparison for several approximate BNN inference techniques on image classification tasks associated to MNIST and a two-class subset of the GTSRB dataset. Our results enable quantification of uncertainty of BNN predictions in adversarial settings.
Robustness Guarantees for Bayesian Inference with Gaussian Processes
Oct 24, 2018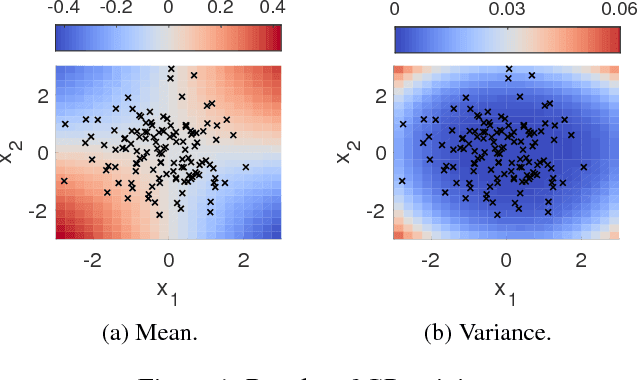
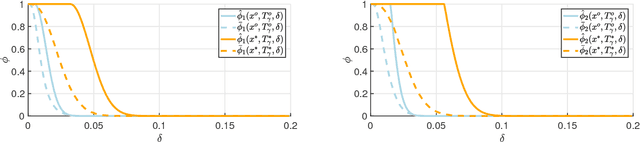
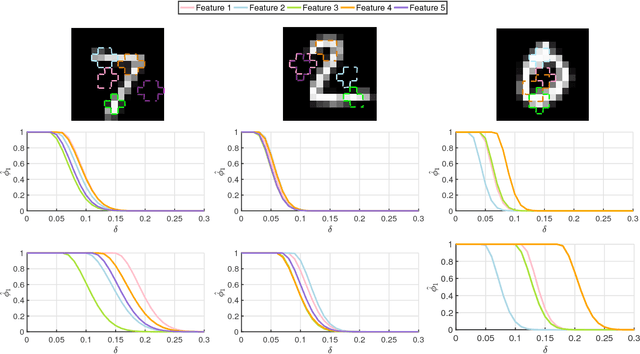
Bayesian inference and Gaussian processes are widely used in applications ranging from robotics and control to biological systems. Many of these applications are safety-critical and require a characterization of the uncertainty associated with the learning model and formal guarantees on its predictions. In this paper we define a robustness measure for Bayesian inference against input perturbations, given by the probability that, for a test point and a compact set in the input space containing the test point, the prediction of the learning model will remain $\delta-$close for all the points in the set, for $\delta>0.$ Such measures can be used to provide formal guarantees for the absence of adversarial examples. By employing the theory of Gaussian processes, we derive tight upper bounds on the resulting robustness by utilising the Borell-TIS inequality, and propose algorithms for their computation. We evaluate our techniques on two examples, a GP regression problem and a fully-connected deep neural network, where we rely on weak convergence to GPs to study adversarial examples on the MNIST dataset.