 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMitigating Media Bias through Neutral Article Generation
Apr 01, 2021

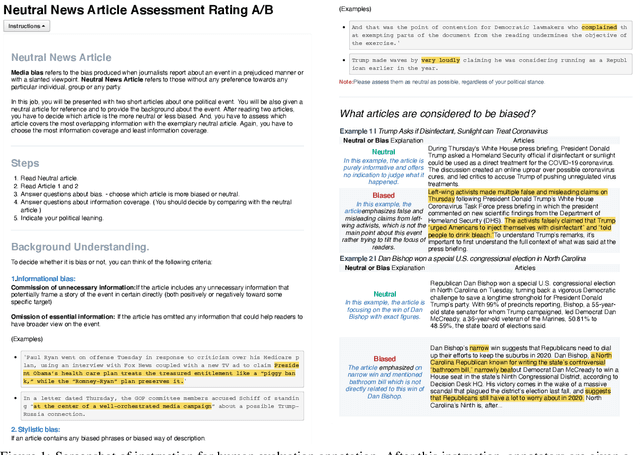

Media bias can lead to increased political polarization, and thus, the need for automatic mitigation methods is growing. Existing mitigation work displays articles from multiple news outlets to provide diverse news coverage, but without neutralizing the bias inherent in each of the displayed articles. Therefore, we propose a new task, a single neutralized article generation out of multiple biased articles, to facilitate more efficient access to balanced and unbiased information. In this paper, we compile a new dataset NeuWS, define an automatic evaluation metric, and provide baselines and multiple analyses to serve as a solid starting point for the proposed task. Lastly, we obtain a human evaluation to demonstrate the alignment between our metric and human judgment.
Are Multilingual Models Effective in Code-Switching?
Mar 24, 2021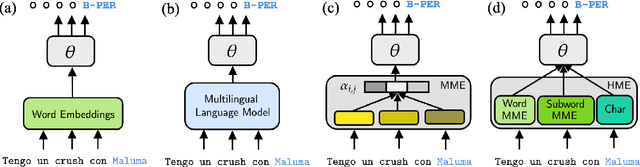
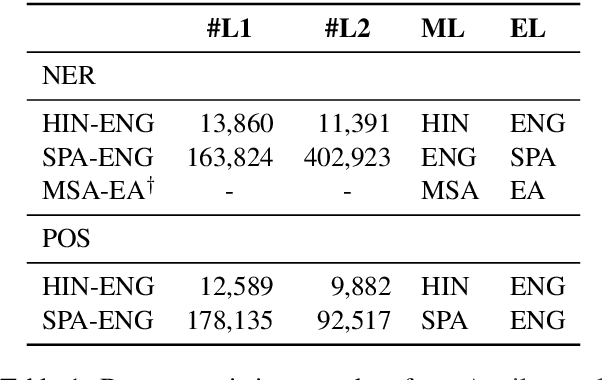
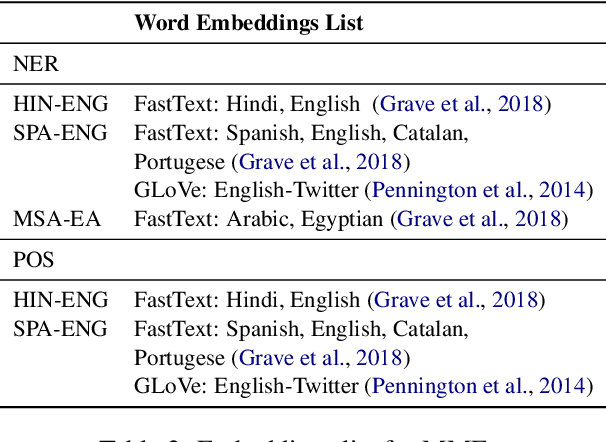
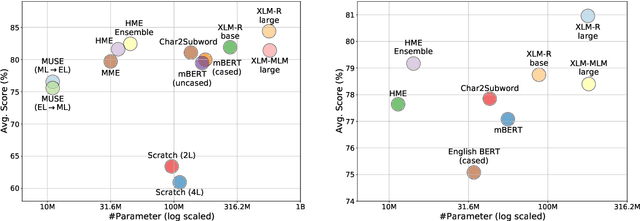
Multilingual language models have shown decent performance in multilingual and cross-lingual natural language understanding tasks. However, the power of these multilingual models in code-switching tasks has not been fully explored. In this paper, we study the effectiveness of multilingual language models to understand their capability and adaptability to the mixed-language setting by considering the inference speed, performance, and number of parameters to measure their practicality. We conduct experiments in three language pairs on named entity recognition and part-of-speech tagging and compare them with existing methods, such as using bilingual embeddings and multilingual meta-embeddings. Our findings suggest that pre-trained multilingual models do not necessarily guarantee high-quality representations on code-switching, while using meta-embeddings achieves similar results with significantly fewer parameters.
Towards Few-Shot Fact-Checking via Perplexity
Mar 17, 2021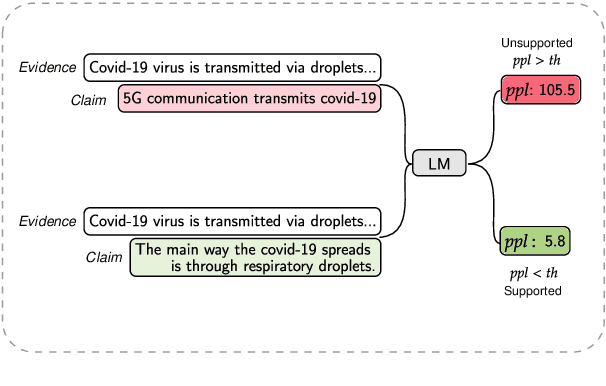

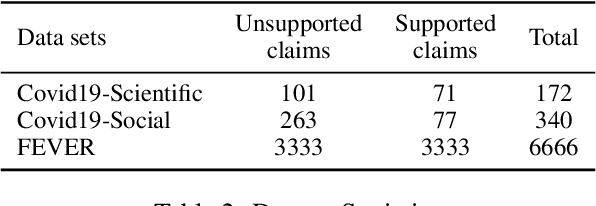
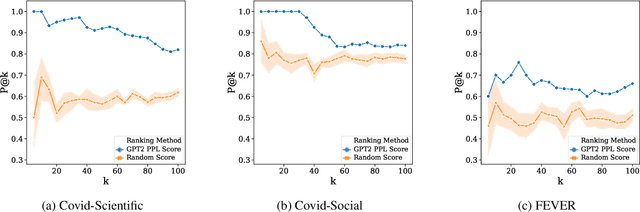
Few-shot learning has drawn researchers' attention to overcome the problem of data scarcity. Recently, large pre-trained language models have shown great performance in few-shot learning for various downstream tasks, such as question answering and machine translation. Nevertheless, little exploration has been made to achieve few-shot learning for the fact-checking task. However, fact-checking is an important problem, especially when the amount of information online is growing exponentially every day. In this paper, we propose a new way of utilizing the powerful transfer learning ability of a language model via a perplexity score. The most notable strength of our methodology lies in its capability in few-shot learning. With only two training samples, our methodology can already outperform the Major Class baseline by more than absolute 10% on the F1-Macro metric across multiple datasets. Through experiments, we empirically verify the plausibility of the rather surprising usage of the perplexity score in the context of fact-checking and highlight the strength of our few-shot methodology by comparing it to strong fine-tuning-based baseline models. Moreover, we construct and publicly release two new fact-checking datasets related to COVID-19.
Continual Learning in Task-Oriented Dialogue Systems
Dec 31, 2020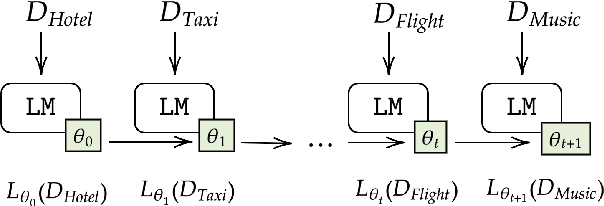
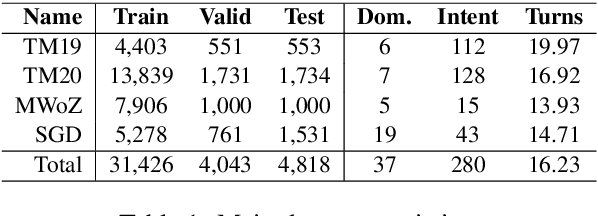

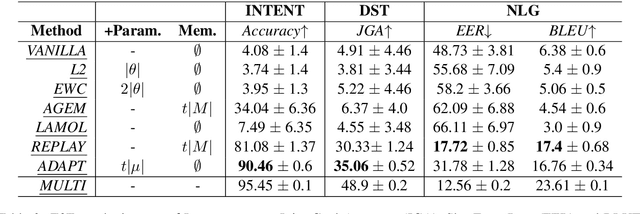
Continual learning in task-oriented dialogue systems can allow us to add new domains and functionalities through time without incurring the high cost of a whole system retraining. In this paper, we propose a continual learning benchmark for task-oriented dialogue systems with 37 domains to be learned continuously in four settings, such as intent recognition, state tracking, natural language generation, and end-to-end. Moreover, we implement and compare multiple existing continual learning baselines, and we propose a simple yet effective architectural method based on residual adapters. Our experiments demonstrate that the proposed architectural method and a simple replay-based strategy perform comparably well but they both achieve inferior performance to the multi-task learning baseline, in where all the data are shown at once, showing that continual learning in task-oriented dialogue systems is a challenging task. Furthermore, we reveal several trade-offs between different continual learning methods in term of parameter usage and memory size, which are important in the design of a task-oriented dialogue system. The proposed benchmark is released together with several baselines to promote more research in this direction.
CrossNER: Evaluating Cross-Domain Named Entity Recognition
Dec 13, 2020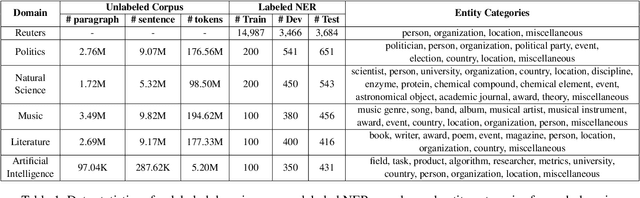
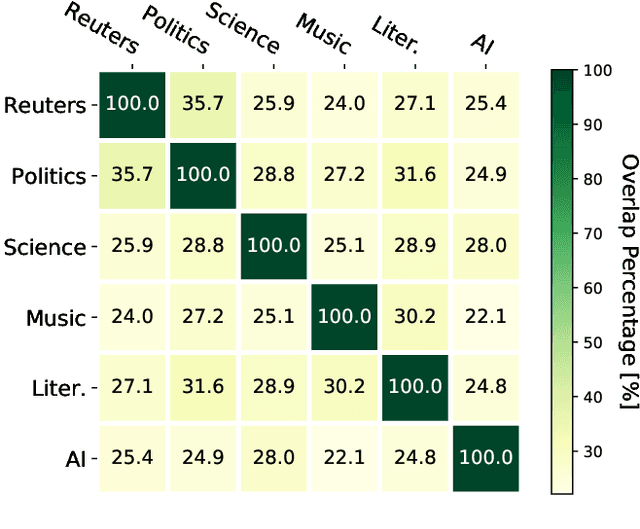
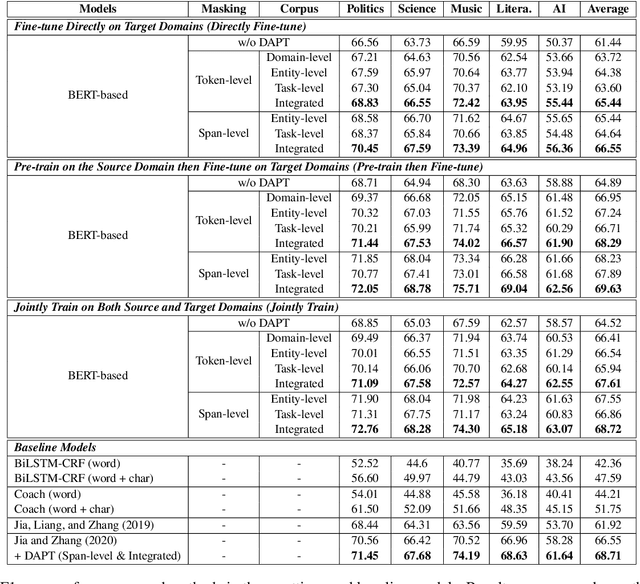
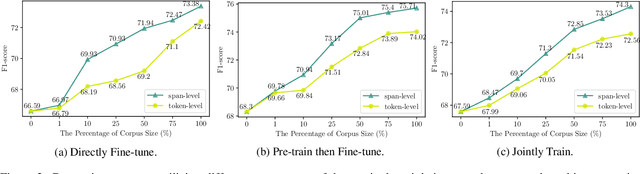
Cross-domain named entity recognition (NER) models are able to cope with the scarcity issue of NER samples in target domains. However, most of the existing NER benchmarks lack domain-specialized entity types or do not focus on a certain domain, leading to a less effective cross-domain evaluation. To address these obstacles, we introduce a cross-domain NER dataset (CrossNER), a fully-labeled collection of NER data spanning over five diverse domains with specialized entity categories for different domains. Additionally, we also provide a domain-related corpus since using it to continue pre-training language models (domain-adaptive pre-training) is effective for the domain adaptation. We then conduct comprehensive experiments to explore the effectiveness of leveraging different levels of the domain corpus and pre-training strategies to do domain-adaptive pre-training for the cross-domain task. Results show that focusing on the fractional corpus containing domain-specialized entities and utilizing a more challenging pre-training strategy in domain-adaptive pre-training are beneficial for the NER domain adaptation, and our proposed method can consistently outperform existing cross-domain NER baselines. Nevertheless, experiments also illustrate the challenge of this cross-domain NER task. We hope that our dataset and baselines will catalyze research in the NER domain adaptation area. The code and data are available at https://github.com/zliucr/CrossNER.
Plug-and-Play Conversational Models
Oct 09, 2020
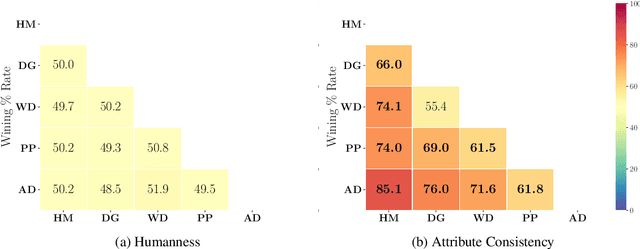

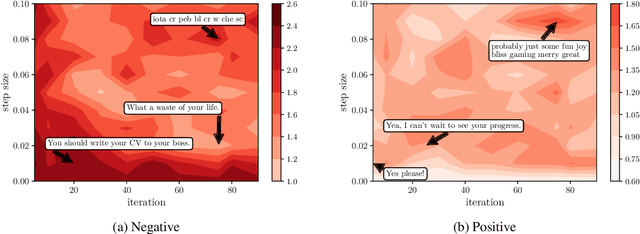
There has been considerable progress made towards conversational models that generate coherent and fluent responses; however, this often involves training large language models on large dialogue datasets, such as Reddit. These large conversational models provide little control over the generated responses, and this control is further limited in the absence of annotated conversational datasets for attribute specific generation that can be used for fine-tuning the model. In this paper, we first propose and evaluate plug-and-play methods for controllable response generation, which does not require dialogue specific datasets and does not rely on fine-tuning a large model. While effective, the decoding procedure induces considerable computational overhead, rendering the conversational model unsuitable for interactive usage. To overcome this, we introduce an approach that does not require further computation at decoding time, while also does not require any fine-tuning of a large language model. We demonstrate, through extensive automatic and human evaluation, a high degree of control over the generated conversational responses with regard to multiple desired attributes, while being fluent.
Learning Knowledge Bases with Parameters for Task-Oriented Dialogue Systems
Sep 28, 2020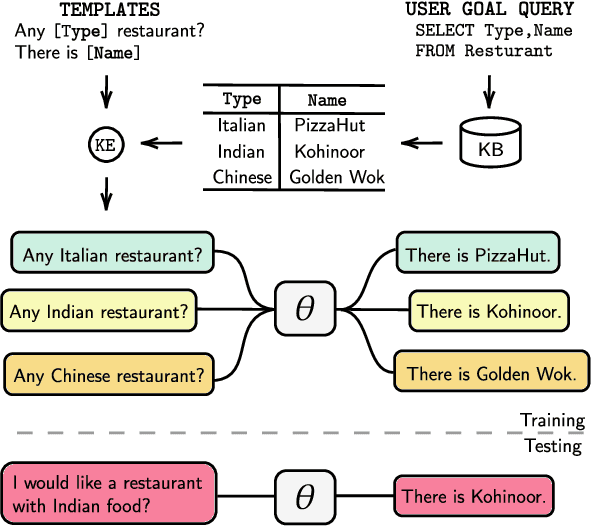

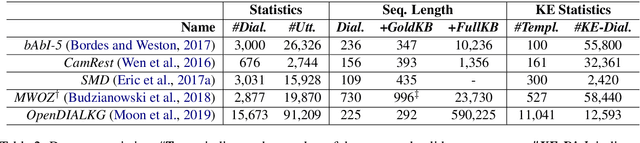
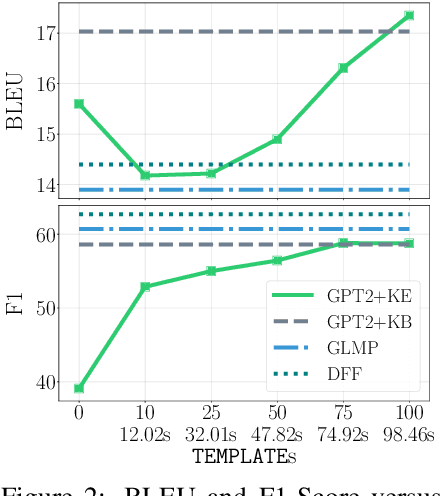
Task-oriented dialogue systems are either modularized with separate dialogue state tracking (DST) and management steps or end-to-end trainable. In either case, the knowledge base (KB) plays an essential role in fulfilling user requests. Modularized systems rely on DST to interact with the KB, which is expensive in terms of annotation and inference time. End-to-end systems use the KB directly as input, but they cannot scale when the KB is larger than a few hundred entries. In this paper, we propose a method to embed the KB, of any size, directly into the model parameters. The resulting model does not require any DST or template responses, nor the KB as input, and it can dynamically update its KB via fine-tuning. We evaluate our solution in five task-oriented dialogue datasets with small, medium, and large KB size. Our experiments show that end-to-end models can effectively embed knowledge bases in their parameters and achieve competitive performance in all evaluated datasets.
MinTL: Minimalist Transfer Learning for Task-Oriented Dialogue Systems
Sep 28, 2020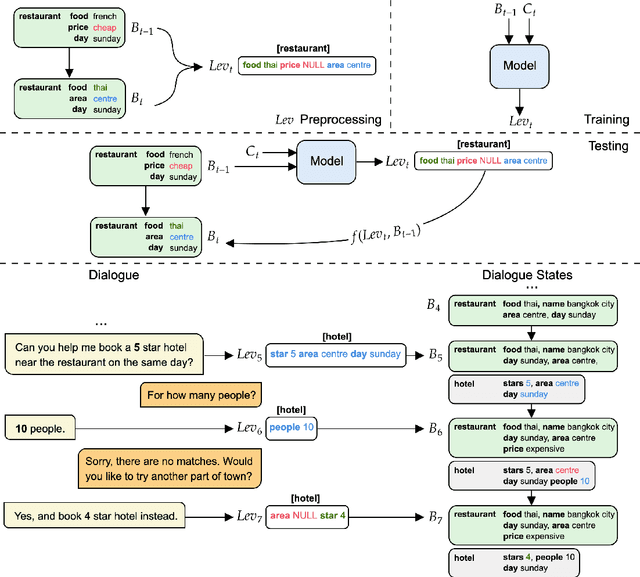
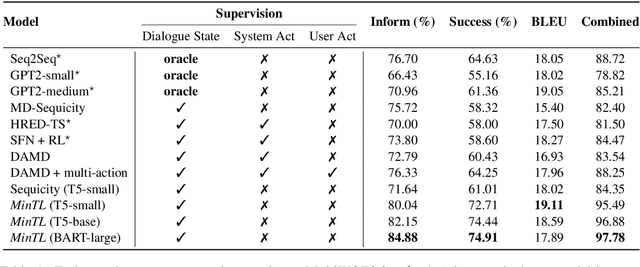
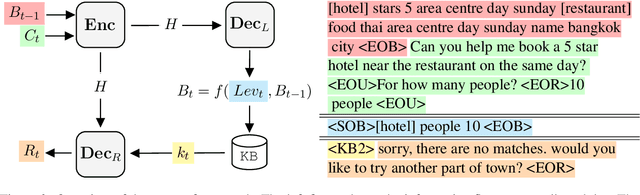
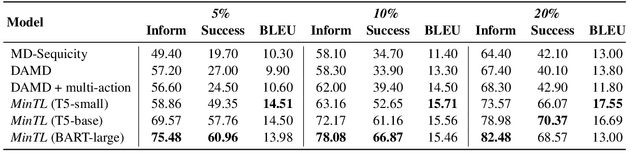
In this paper, we propose Minimalist Transfer Learning (MinTL) to simplify the system design process of task-oriented dialogue systems and alleviate the over-dependency on annotated data. MinTL is a simple yet effective transfer learning framework, which allows us to plug-and-play pre-trained seq2seq models, and jointly learn dialogue state tracking and dialogue response generation. Unlike previous approaches, which use a copy mechanism to "carryover" the old dialogue states to the new one, we introduce Levenshtein belief spans (Lev), that allows efficient dialogue state tracking with a minimal generation length. We instantiate our learning framework with two pre-trained backbones: T5 and BART, and evaluate them on MultiWOZ. Extensive experiments demonstrate that: 1) our systems establish new state-of-the-art results on end-to-end response generation, 2) MinTL-based systems are more robust than baseline methods in the low resource setting, and they achieve competitive results with only 20\% training data, and 3) Lev greatly improves the inference efficiency.
The Adapter-Bot: All-In-One Controllable Conversational Model
Aug 28, 2020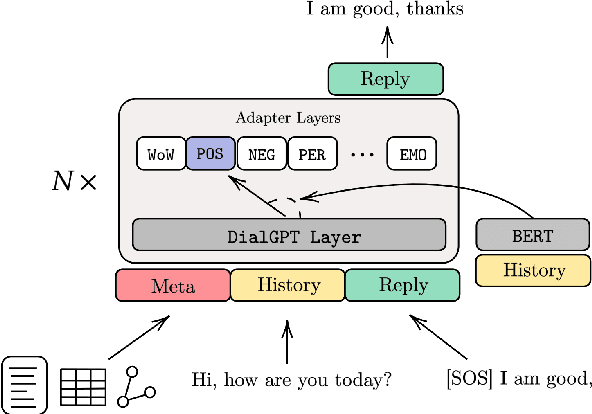

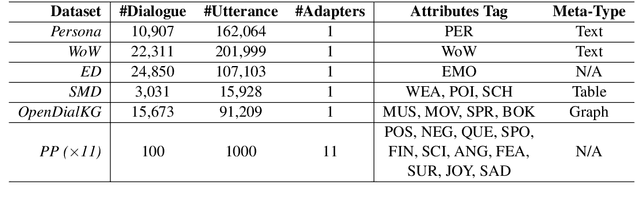
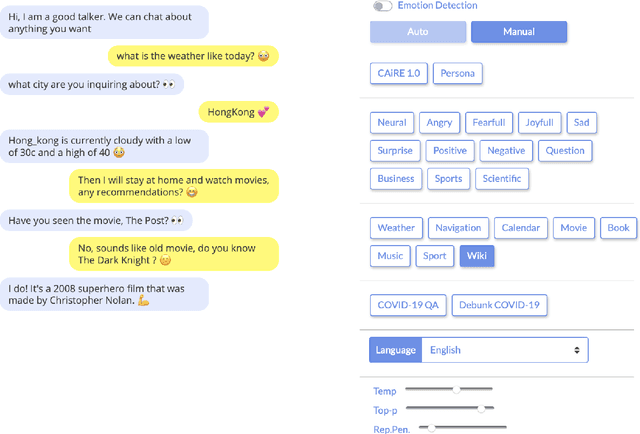
Considerable progress has been made towards conversational models that generate coherent and fluent responses by training large language models on large dialogue datasets. These models have little or no control of the generated responses and miss two important features: continuous dialogue skills integration and seamlessly leveraging diverse knowledge sources. In this paper, we propose the Adapter-Bot, a dialogue model that uses a fixed backbone conversational model such as DialGPT (Zhang et al., 2019) and triggers on-demand dialogue skills (e.g., emphatic response, weather information, movie recommendation) via different adapters (Houlsby et al., 2019). Each adapter can be trained independently, thus allowing a continual integration of skills without retraining the entire model. Depending on the skills, the model is able to process multiple knowledge types, such as text, tables, and graphs, in a seamless manner. The dialogue skills can be triggered automatically via a dialogue manager, or manually, thus allowing high-level control of the generated responses. At the current stage, we have implemented 12 response styles (e.g., positive, negative etc.), 8 goal-oriented skills (e.g. weather information, movie recommendation, etc.), and personalized and emphatic responses. We evaluate our model using automatic evaluation by comparing it with existing state-of-the-art conversational models, and we have released an interactive system at adapter.bot.ust.hk.
Language Models as Few-Shot Learner for Task-Oriented Dialogue Systems
Aug 20, 2020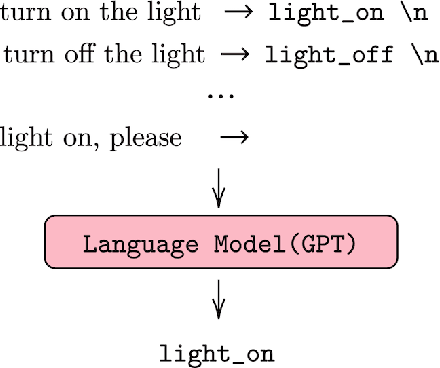
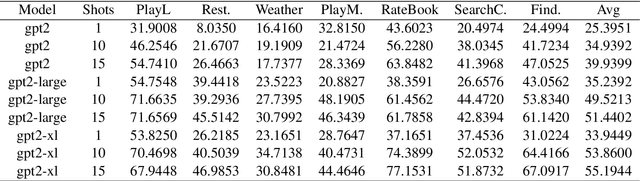
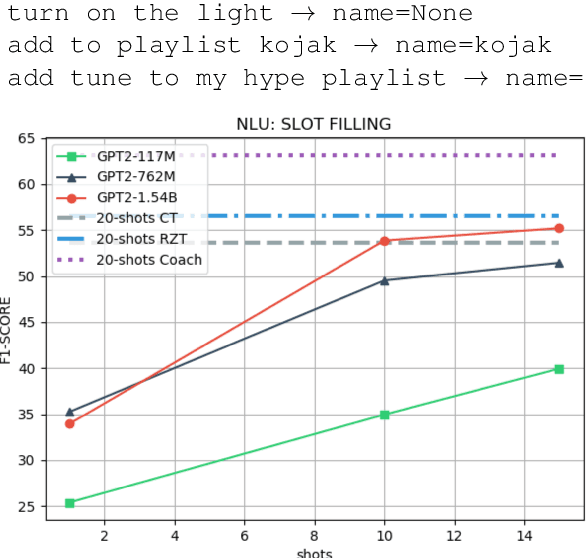
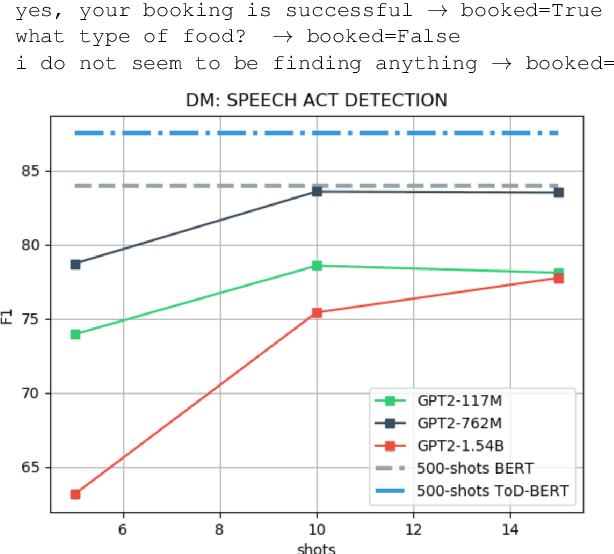
Task-oriented dialogue systems use four connected modules, namely, Natural Language Understanding (NLU), a Dialogue State Tracking (DST), Dialogue Policy (DP) and Natural Language Generation (NLG). A research challenge is to learn each module with the least amount of samples (i.e., few-shots) given the high cost related to the data collection. The most common and effective technique to solve this problem is transfer learning, where large language models, either pre-trained on text or task-specific data, are fine-tuned on the few samples. These methods require fine-tuning steps and a set of parameters for each task. Differently, language models, such as GPT-2 (Radford et al., 2019) and GPT-3 (Brown et al., 2020), allow few-shot learning by priming the model with few examples. In this paper, we evaluate the priming few-shot ability of language models in the NLU, DST, DP and NLG tasks. Importantly, we highlight the current limitations of this approach, and we discuss the possible implication for future work.