 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerating Plans that Predict Themselves
Feb 14, 2018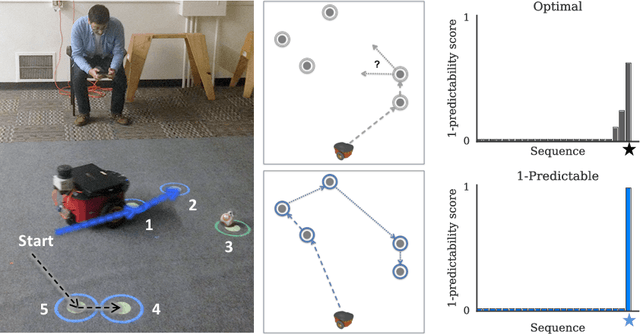
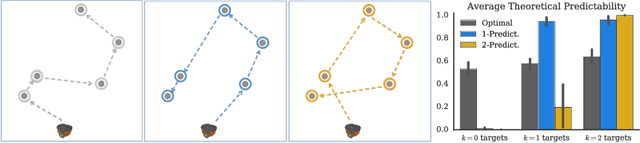
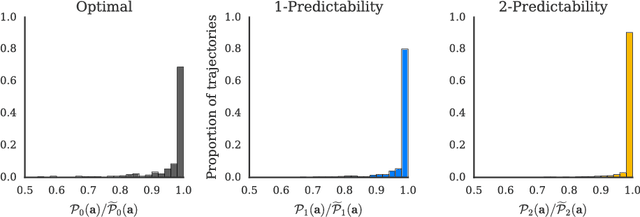
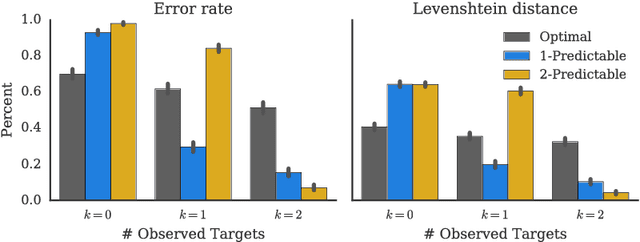
Collaboration requires coordination, and we coordinate by anticipating our teammates' future actions and adapting to their plan. In some cases, our teammates' actions early on can give us a clear idea of what the remainder of their plan is, i.e. what action sequence we should expect. In others, they might leave us less confident, or even lead us to the wrong conclusion. Our goal is for robot actions to fall in the first category: we want to enable robots to select their actions in such a way that human collaborators can easily use them to correctly anticipate what will follow. While previous work has focused on finding initial plans that convey a set goal, here we focus on finding two portions of a plan such that the initial portion conveys the final one. We introduce $t$-\ACty{}: a measure that quantifies the accuracy and confidence with which human observers can predict the remaining robot plan from the overall task goal and the observed initial $t$ actions in the plan. We contribute a method for generating $t$-predictable plans: we search for a full plan that accomplishes the task, but in which the first $t$ actions make it as easy as possible to infer the remaining ones. The result is often different from the most efficient plan, in which the initial actions might leave a lot of ambiguity as to how the task will be completed. Through an online experiment and an in-person user study with physical robots, we find that our approach outperforms a traditional efficiency-based planner in objective and subjective collaboration metrics.
* Published at the Workshop on Algorithmic Foundations of Robotics (WAFR 2016)
Goal Inference Improves Objective and Perceived Performance in Human-Robot Collaboration
Feb 06, 2018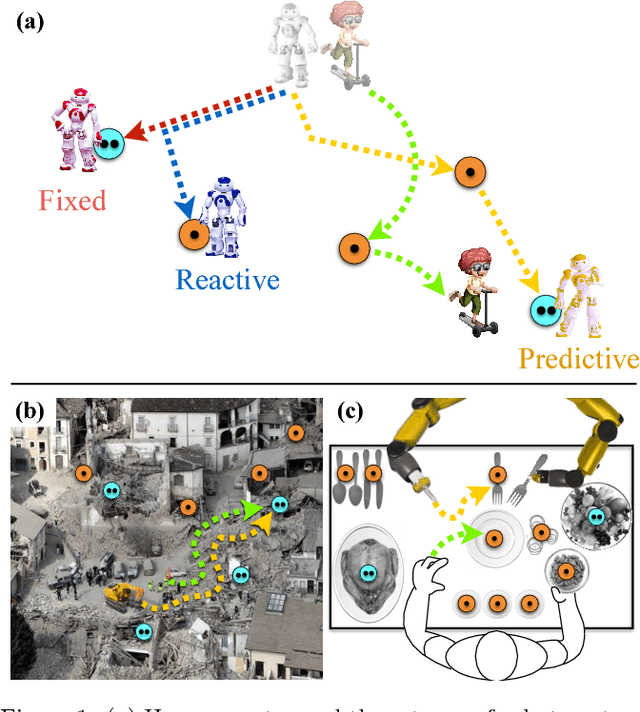
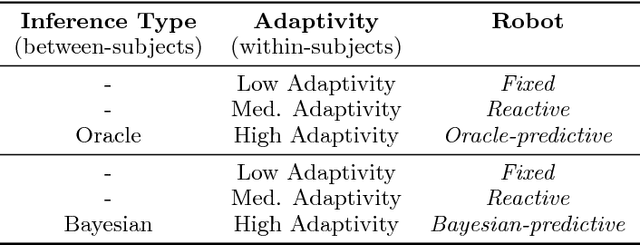
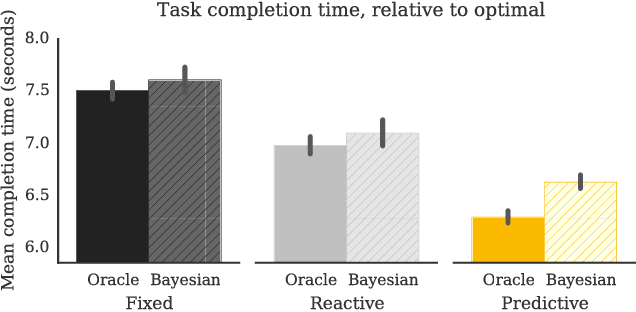
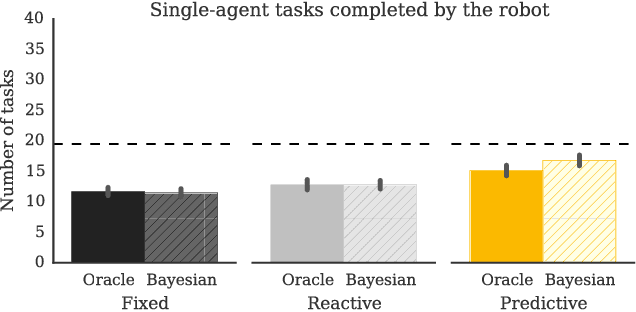
The study of human-robot interaction is fundamental to the design and use of robotics in real-world applications. Robots will need to predict and adapt to the actions of human collaborators in order to achieve good performance and improve safety and end-user adoption. This paper evaluates a human-robot collaboration scheme that combines the task allocation and motion levels of reasoning: the robotic agent uses Bayesian inference to predict the next goal of its human partner from his or her ongoing motion, and re-plans its own actions in real time. This anticipative adaptation is desirable in many practical scenarios, where humans are unable or unwilling to take on the cognitive overhead required to explicitly communicate their intent to the robot. A behavioral experiment indicates that the combination of goal inference and dynamic task planning significantly improves both objective and perceived performance of the human-robot team. Participants were highly sensitive to the differences between robot behaviors, preferring to work with a robot that adapted to their actions over one that did not.
* Published at the International Conference on Autonomous Agents and Multiagent Systems (AAMAS 2016)
Pragmatic-Pedagogic Value Alignment
Feb 05, 2018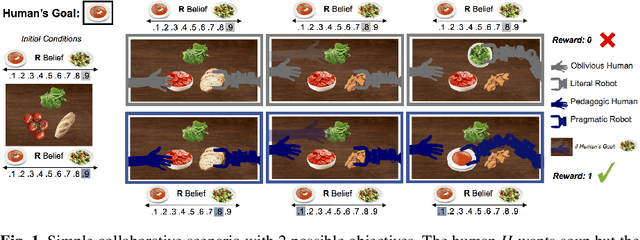

As intelligent systems gain autonomy and capability, it becomes vital to ensure that their objectives match those of their human users; this is known as the value-alignment problem. In robotics, value alignment is key to the design of collaborative robots that can integrate into human workflows, successfully inferring and adapting to their users' objectives as they go. We argue that a meaningful solution to value alignment must combine multi-agent decision theory with rich mathematical models of human cognition, enabling robots to tap into people's natural collaborative capabilities. We present a solution to the cooperative inverse reinforcement learning (CIRL) dynamic game based on well-established cognitive models of decision making and theory of mind. The solution captures a key reciprocity relation: the human will not plan her actions in isolation, but rather reason pedagogically about how the robot might learn from them; the robot, in turn, can anticipate this and interpret the human's actions pragmatically. To our knowledge, this work constitutes the first formal analysis of value alignment grounded in empirically validated cognitive models.
* Published at the International Symposium on Robotics Research (ISRR 2017)
Do You Want Your Autonomous Car To Drive Like You?
Feb 05, 2018
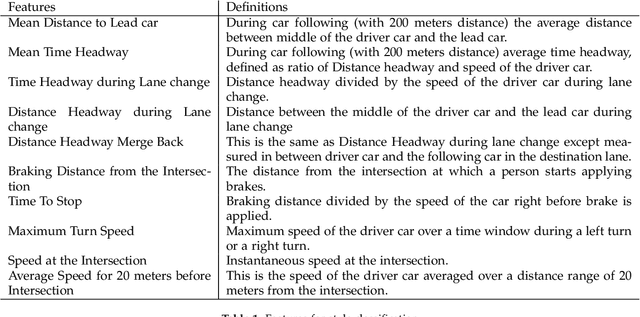
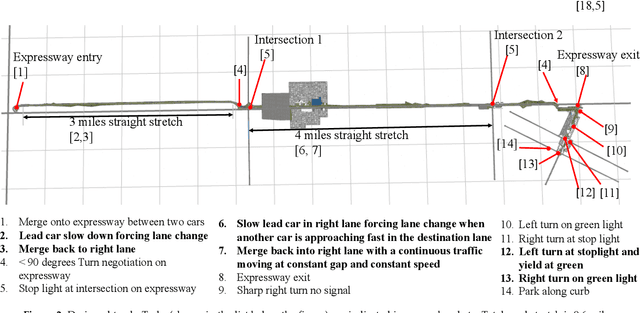
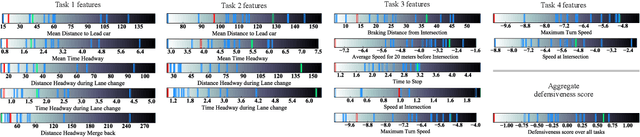
With progress in enabling autonomous cars to drive safely on the road, it is time to start asking how they should be driving. A common answer is that they should be adopting their users' driving style. This makes the assumption that users want their autonomous cars to drive like they drive - aggressive drivers want aggressive cars, defensive drivers want defensive cars. In this paper, we put that assumption to the test. We find that users tend to prefer a significantly more defensive driving style than their own. Interestingly, they prefer the style they think is their own, even though their actual driving style tends to be more aggressive. We also find that preferences do depend on the specific driving scenario, opening the door for new ways of learning driving style preference.
Learning from Richer Human Guidance: Augmenting Comparison-Based Learning with Feature Queries
Feb 05, 2018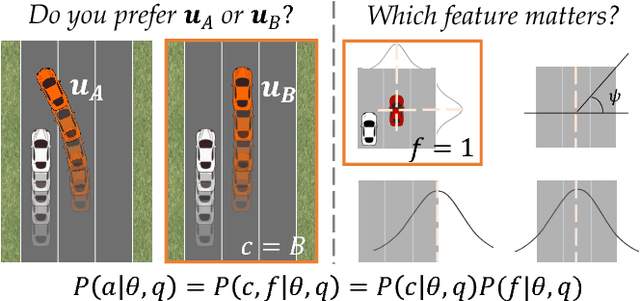
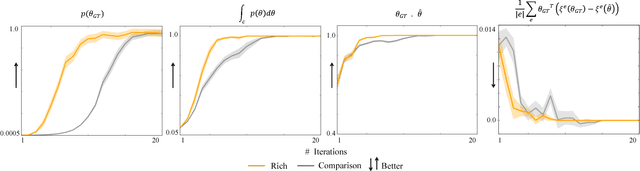
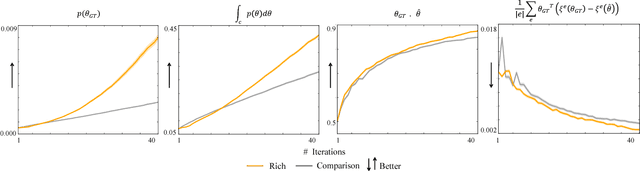
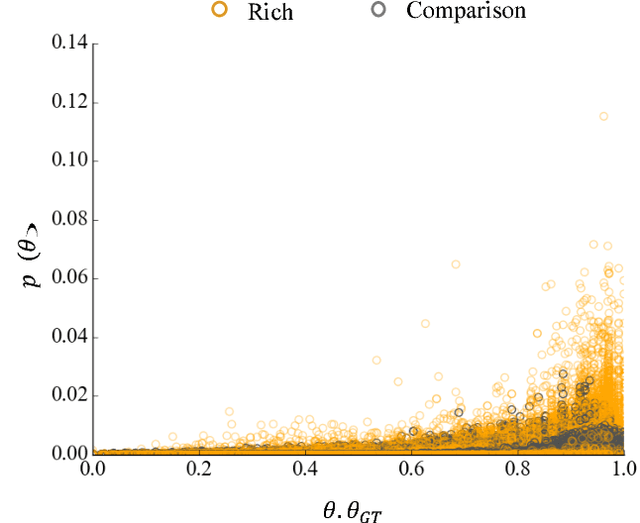
We focus on learning the desired objective function for a robot. Although trajectory demonstrations can be very informative of the desired objective, they can also be difficult for users to provide. Answers to comparison queries, asking which of two trajectories is preferable, are much easier for users, and have emerged as an effective alternative. Unfortunately, comparisons are far less informative. We propose that there is much richer information that users can easily provide and that robots ought to leverage. We focus on augmenting comparisons with feature queries, and introduce a unified formalism for treating all answers as observations about the true desired reward. We derive an active query selection algorithm, and test these queries in simulation and on real users. We find that richer, feature-augmented queries can extract more information faster, leading to robots that better match user preferences in their behavior.
Expressive Robot Motion Timing
Feb 05, 2018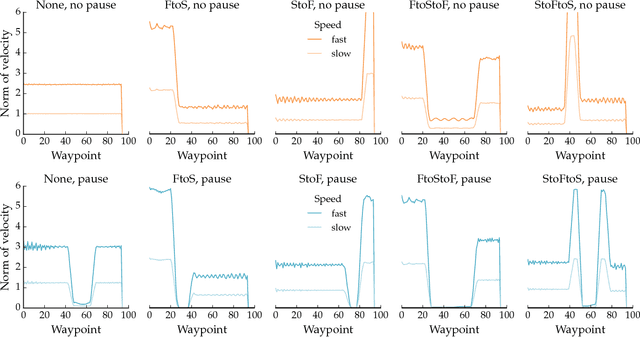
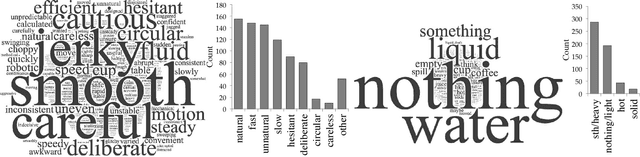
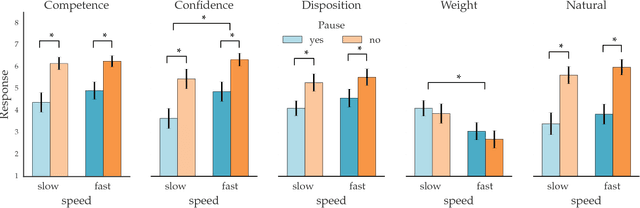
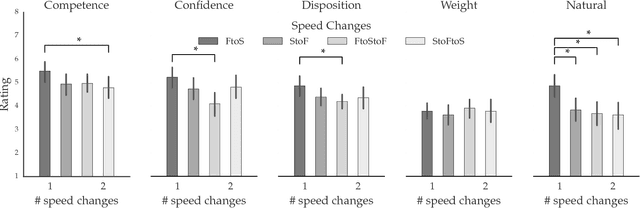
Our goal is to enable robots to \emph{time} their motion in a way that is purposefully expressive of their internal states, making them more transparent to people. We start by investigating what types of states motion timing is capable of expressing, focusing on robot manipulation and keeping the path constant while systematically varying the timing. We find that users naturally pick up on certain properties of the robot (like confidence), of the motion (like naturalness), or of the task (like the weight of the object that the robot is carrying). We then conduct a hypothesis-driven experiment to tease out the directions and magnitudes of these effects, and use our findings to develop candidate mathematical models for how users make these inferences from the timing. We find a strong correlation between the models and real user data, suggesting that robots can leverage these models to autonomously optimize the timing of their motion to be expressive.
Robot Planning with Mathematical Models of Human State and Action
Jul 04, 2017



Robots interacting with the physical world plan with models of physics. We advocate that robots interacting with people need to plan with models of cognition. This writeup summarizes the insights we have gained in integrating computational cognitive models of people into robotics planning and control. It starts from a general game-theoretic formulation of interaction, and analyzes how different approximations result in different useful coordination behaviors for the robot during its interaction with people.