 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLattice Rescoring Strategies for Long Short Term Memory Language Models in Speech Recognition
Nov 15, 2017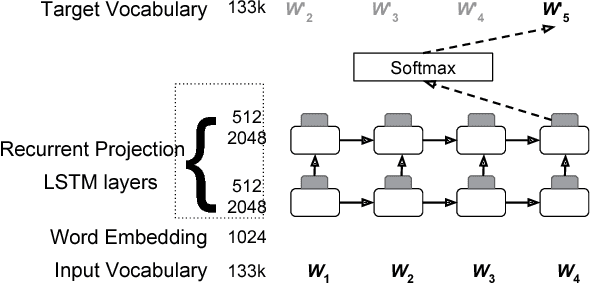

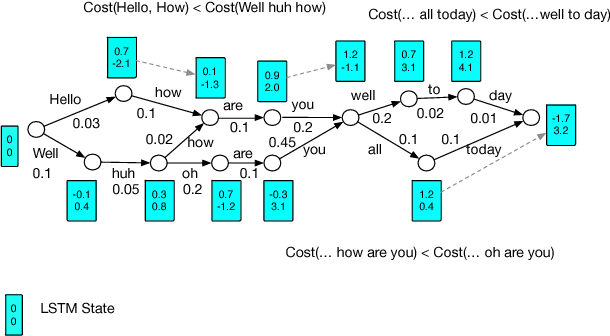
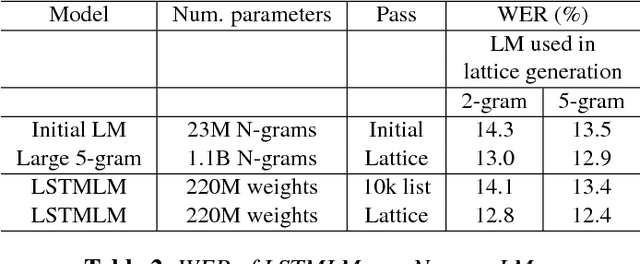
Recurrent neural network (RNN) language models (LMs) and Long Short Term Memory (LSTM) LMs, a variant of RNN LMs, have been shown to outperform traditional N-gram LMs on speech recognition tasks. However, these models are computationally more expensive than N-gram LMs for decoding, and thus, challenging to integrate into speech recognizers. Recent research has proposed the use of lattice-rescoring algorithms using RNNLMs and LSTMLMs as an efficient strategy to integrate these models into a speech recognition system. In this paper, we evaluate existing lattice rescoring algorithms along with new variants on a YouTube speech recognition task. Lattice rescoring using LSTMLMs reduces the word error rate (WER) for this task by 8\% relative to the WER obtained using an N-gram LM.
* Accepted at ASRU 2017
Federated Learning: Strategies for Improving Communication Efficiency
Oct 30, 2017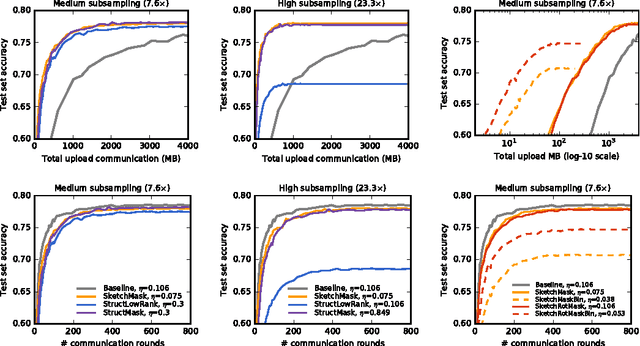
Federated Learning is a machine learning setting where the goal is to train a high-quality centralized model while training data remains distributed over a large number of clients each with unreliable and relatively slow network connections. We consider learning algorithms for this setting where on each round, each client independently computes an update to the current model based on its local data, and communicates this update to a central server, where the client-side updates are aggregated to compute a new global model. The typical clients in this setting are mobile phones, and communication efficiency is of the utmost importance. In this paper, we propose two ways to reduce the uplink communication costs: structured updates, where we directly learn an update from a restricted space parametrized using a smaller number of variables, e.g. either low-rank or a random mask; and sketched updates, where we learn a full model update and then compress it using a combination of quantization, random rotations, and subsampling before sending it to the server. Experiments on both convolutional and recurrent networks show that the proposed methods can reduce the communication cost by two orders of magnitude.
Distributed Mean Estimation with Limited Communication
Sep 25, 2017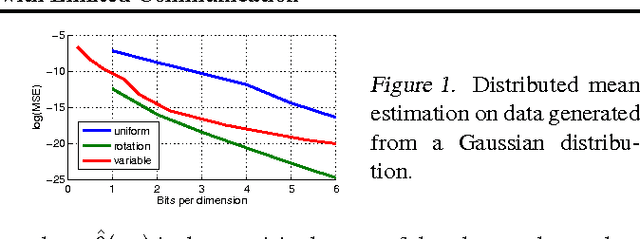
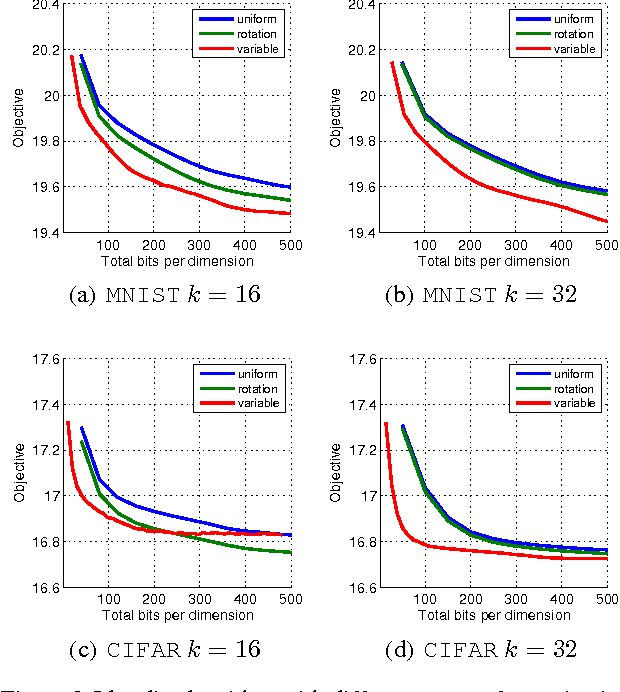
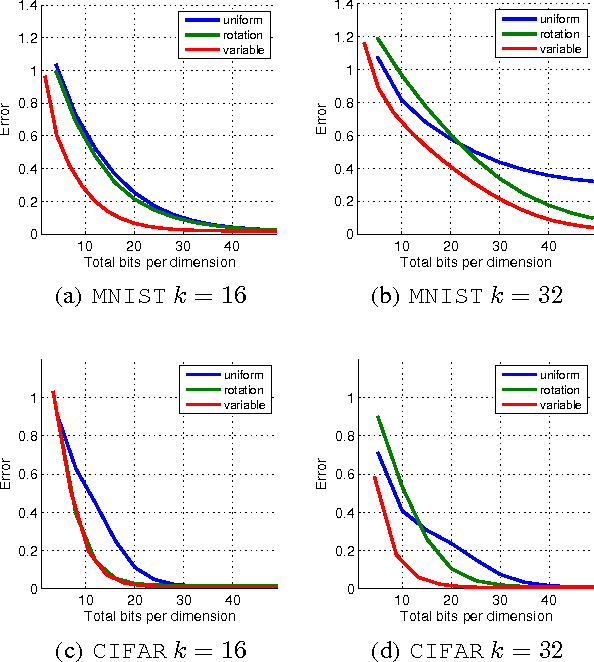
Motivated by the need for distributed learning and optimization algorithms with low communication cost, we study communication efficient algorithms for distributed mean estimation. Unlike previous works, we make no probabilistic assumptions on the data. We first show that for $d$ dimensional data with $n$ clients, a naive stochastic binary rounding approach yields a mean squared error (MSE) of $\Theta(d/n)$ and uses a constant number of bits per dimension per client. We then extend this naive algorithm in two ways: we show that applying a structured random rotation before quantization reduces the error to $\mathcal{O}((\log d)/n)$ and a better coding strategy further reduces the error to $\mathcal{O}(1/n)$ and uses a constant number of bits per dimension per client. We also show that the latter coding strategy is optimal up to a constant in the minimax sense i.e., it achieves the best MSE for a given communication cost. We finally demonstrate the practicality of our algorithms by applying them to distributed Lloyd's algorithm for k-means and power iteration for PCA.
Model-Powered Conditional Independence Test
Sep 18, 2017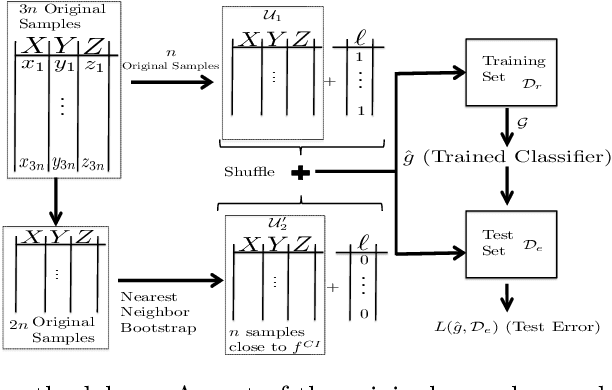
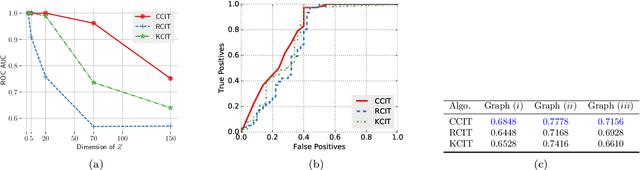
We consider the problem of non-parametric Conditional Independence testing (CI testing) for continuous random variables. Given i.i.d samples from the joint distribution $f(x,y,z)$ of continuous random vectors $X,Y$ and $Z,$ we determine whether $X \perp Y | Z$. We approach this by converting the conditional independence test into a classification problem. This allows us to harness very powerful classifiers like gradient-boosted trees and deep neural networks. These models can handle complex probability distributions and allow us to perform significantly better compared to the prior state of the art, for high-dimensional CI testing. The main technical challenge in the classification problem is the need for samples from the conditional product distribution $f^{CI}(x,y,z) = f(x|z)f(y|z)f(z)$ -- the joint distribution if and only if $X \perp Y | Z.$ -- when given access only to i.i.d. samples from the true joint distribution $f(x,y,z)$. To tackle this problem we propose a novel nearest neighbor bootstrap procedure and theoretically show that our generated samples are indeed close to $f^{CI}$ in terms of total variational distance. We then develop theoretical results regarding the generalization bounds for classification for our problem, which translate into error bounds for CI testing. We provide a novel analysis of Rademacher type classification bounds in the presence of non-i.i.d near-independent samples. We empirically validate the performance of our algorithm on simulated and real datasets and show performance gains over previous methods.
Sample complexity of population recovery
Jun 05, 2017
The problem of population recovery refers to estimating a distribution based on incomplete or corrupted samples. Consider a random poll of sample size $n$ conducted on a population of individuals, where each pollee is asked to answer $d$ binary questions. We consider one of the two polling impediments: (a) in lossy population recovery, a pollee may skip each question with probability $\epsilon$, (b) in noisy population recovery, a pollee may lie on each question with probability $\epsilon$. Given $n$ lossy or noisy samples, the goal is to estimate the probabilities of all $2^d$ binary vectors simultaneously within accuracy $\delta$ with high probability. This paper settles the sample complexity of population recovery. For lossy model, the optimal sample complexity is $\tilde\Theta(\delta^{-2\max\{\frac{\epsilon}{1-\epsilon},1\}})$, improving the state of the art by Moitra and Saks in several ways: a lower bound is established, the upper bound is improved and the result depends at most on the logarithm of the dimension. Surprisingly, the sample complexity undergoes a phase transition from parametric to nonparametric rate when $\epsilon$ exceeds $1/2$. For noisy population recovery, the sharp sample complexity turns out to be more sensitive to dimension and scales as $\exp(\Theta(d^{1/3} \log^{2/3}(1/\delta)))$ except for the trivial cases of $\epsilon=0,1/2$ or $1$. For both models, our estimators simply compute the empirical mean of a certain function, which is found by pre-solving a linear program (LP). Curiously, the dual LP can be understood as Le Cam's method for lower-bounding the minimax risk, thus establishing the statistical optimality of the proposed estimators. The value of the LP is determined by complex-analytic methods.
Maximum Selection and Ranking under Noisy Comparisons
May 15, 2017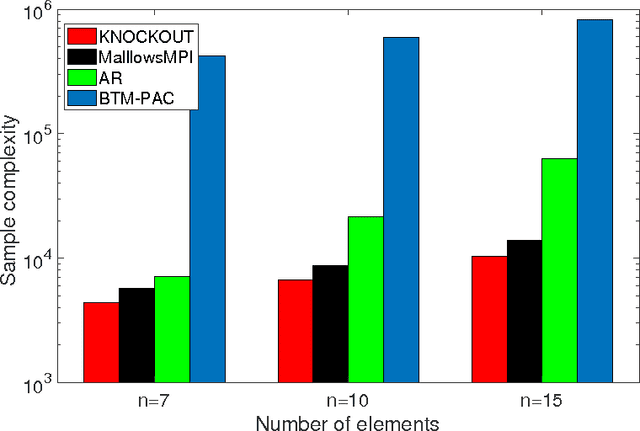
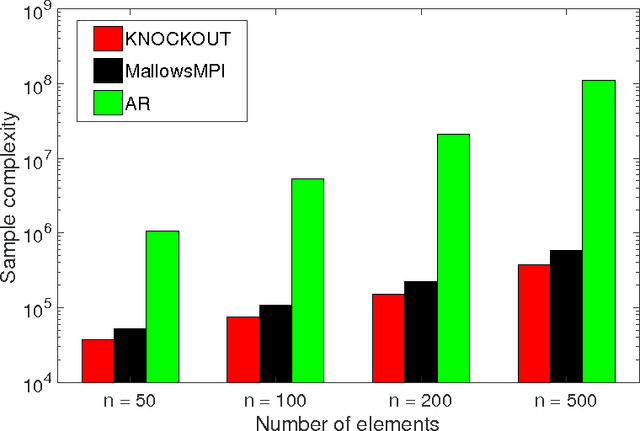
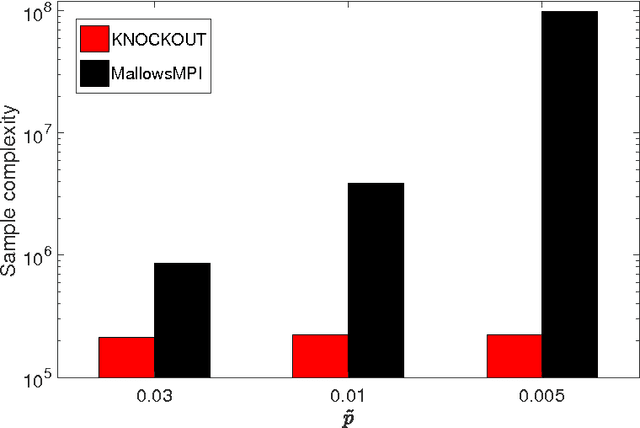
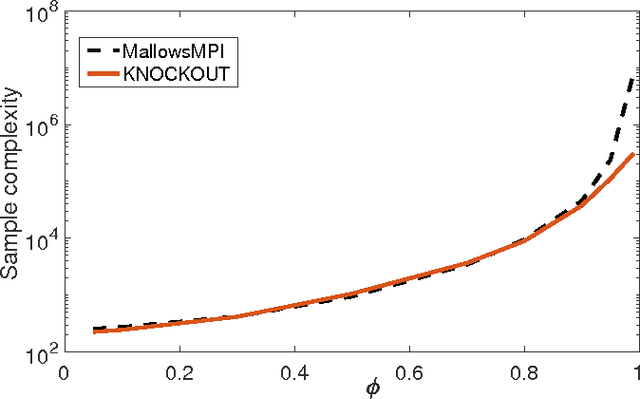
We consider $(\epsilon,\delta)$-PAC maximum-selection and ranking for general probabilistic models whose comparisons probabilities satisfy strong stochastic transitivity and stochastic triangle inequality. Modifying the popular knockout tournament, we propose a maximum-selection algorithm that uses $\mathcal{O}\left(\frac{n}{\epsilon^2}\log \frac{1}{\delta}\right)$ comparisons, a number tight up to a constant factor. We then derive a general framework that improves the performance of many ranking algorithms, and combine it with merge sort and binary search to obtain a ranking algorithm that uses $\mathcal{O}\left(\frac{n\log n (\log \log n)^3}{\epsilon^2}\right)$ comparisons for any $\delta\ge\frac1n$, a number optimal up to a $(\log \log n)^3$ factor.
A Unified Maximum Likelihood Approach for Optimal Distribution Property Estimation
Nov 28, 2016
The advent of data science has spurred interest in estimating properties of distributions over large alphabets. Fundamental symmetric properties such as support size, support coverage, entropy, and proximity to uniformity, received most attention, with each property estimated using a different technique and often intricate analysis tools. We prove that for all these properties, a single, simple, plug-in estimator---profile maximum likelihood (PML)---performs as well as the best specialized techniques. This raises the possibility that PML may optimally estimate many other symmetric properties.
Orthogonal Random Features
Oct 28, 2016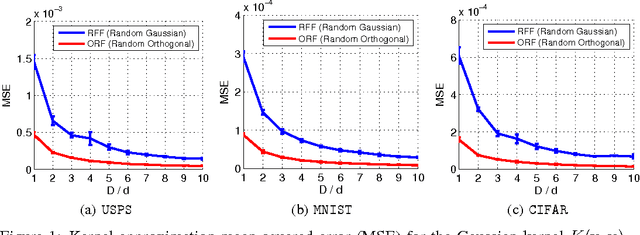
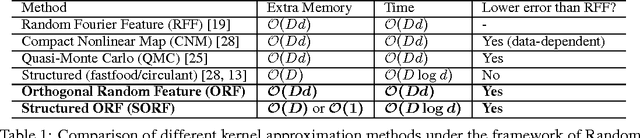
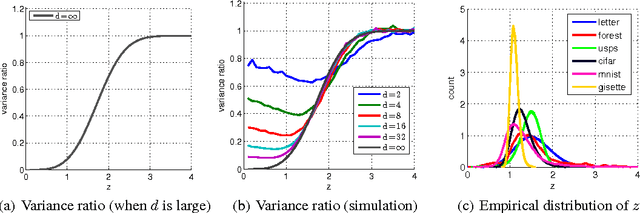
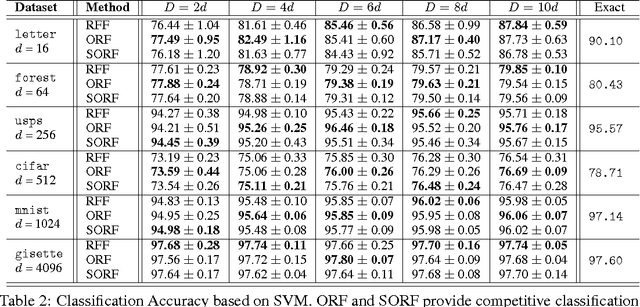
We present an intriguing discovery related to Random Fourier Features: in Gaussian kernel approximation, replacing the random Gaussian matrix by a properly scaled random orthogonal matrix significantly decreases kernel approximation error. We call this technique Orthogonal Random Features (ORF), and provide theoretical and empirical justification for this behavior. Motivated by this discovery, we further propose Structured Orthogonal Random Features (SORF), which uses a class of structured discrete orthogonal matrices to speed up the computation. The method reduces the time cost from $\mathcal{O}(d^2)$ to $\mathcal{O}(d \log d)$, where $d$ is the data dimensionality, with almost no compromise in kernel approximation quality compared to ORF. Experiments on several datasets verify the effectiveness of ORF and SORF over the existing methods. We also provide discussions on using the same type of discrete orthogonal structure for a broader range of applications.
Estimating Renyi Entropy of Discrete Distributions
Mar 10, 2016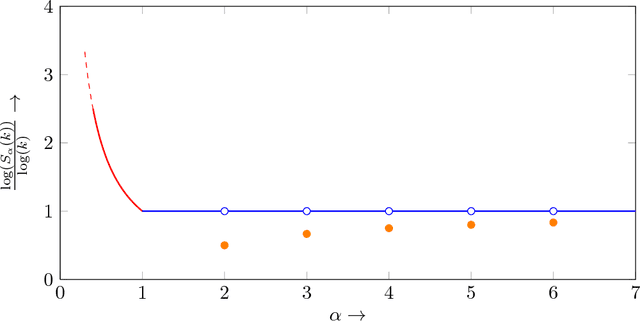
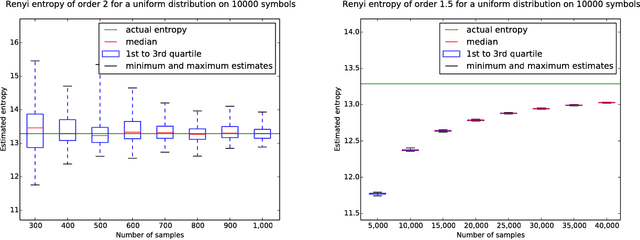
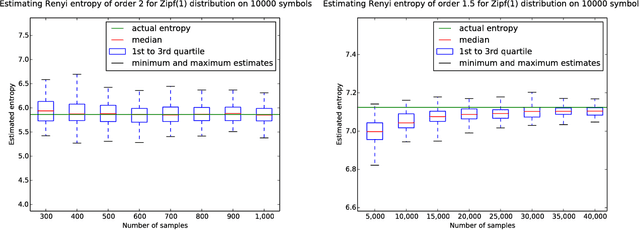
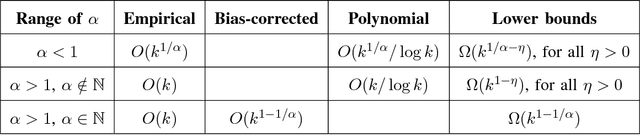
It was recently shown that estimating the Shannon entropy $H({\rm p})$ of a discrete $k$-symbol distribution ${\rm p}$ requires $\Theta(k/\log k)$ samples, a number that grows near-linearly in the support size. In many applications $H({\rm p})$ can be replaced by the more general R\'enyi entropy of order $\alpha$, $H_\alpha({\rm p})$. We determine the number of samples needed to estimate $H_\alpha({\rm p})$ for all $\alpha$, showing that $\alpha < 1$ requires a super-linear, roughly $k^{1/\alpha}$ samples, noninteger $\alpha>1$ requires a near-linear $k$ samples, but, perhaps surprisingly, integer $\alpha>1$ requires only $\Theta(k^{1-1/\alpha})$ samples. Furthermore, developing on a recently established connection between polynomial approximation and estimation of additive functions of the form $\sum_{x} f({\rm p}_x)$, we reduce the sample complexity for noninteger values of $\alpha$ by a factor of $\log k$ compared to the empirical estimator. The estimators achieving these bounds are simple and run in time linear in the number of samples. Our lower bounds provide explicit constructions of distributions with different R\'enyi entropies that are hard to distinguish.
Estimating the number of unseen species: A bird in the hand is worth $\log n $ in the bush
Mar 03, 2016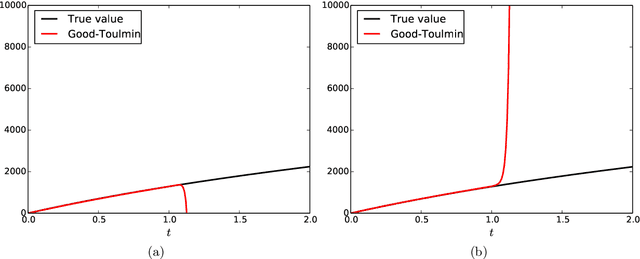

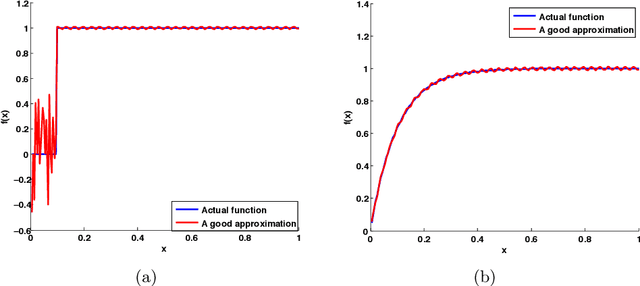
Estimating the number of unseen species is an important problem in many scientific endeavors. Its most popular formulation, introduced by Fisher, uses $n$ samples to predict the number $U$ of hitherto unseen species that would be observed if $t\cdot n$ new samples were collected. Of considerable interest is the largest ratio $t$ between the number of new and existing samples for which $U$ can be accurately predicted. In seminal works, Good and Toulmin constructed an intriguing estimator that predicts $U$ for all $t\le 1$, thereby showing that the number of species can be estimated for a population twice as large as that observed. Subsequently Efron and Thisted obtained a modified estimator that empirically predicts $U$ even for some $t>1$, but without provable guarantees. We derive a class of estimators that $\textit{provably}$ predict $U$ not just for constant $t>1$, but all the way up to $t$ proportional to $\log n$. This shows that the number of species can be estimated for a population $\log n$ times larger than that observed, a factor that grows arbitrarily large as $n$ increases. We also show that this range is the best possible and that the estimators' mean-square error is optimal up to constants for any $t$. Our approach yields the first provable guarantee for the Efron-Thisted estimator and, in addition, a variant which achieves stronger theoretical and experimental performance than existing methodologies on a variety of synthetic and real datasets. The estimators we derive are simple linear estimators that are computable in time proportional to $n$. The performance guarantees hold uniformly for all distributions, and apply to all four standard sampling models commonly used across various scientific disciplines: multinomial, Poisson, hypergeometric, and Bernoulli product.