 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTalkinNeRF: Animatable Neural Fields for Full-Body Talking Humans
Sep 25, 2024



We introduce a novel framework that learns a dynamic neural radiance field (NeRF) for full-body talking humans from monocular videos. Prior work represents only the body pose or the face. However, humans communicate with their full body, combining body pose, hand gestures, as well as facial expressions. In this work, we propose TalkinNeRF, a unified NeRF-based network that represents the holistic 4D human motion. Given a monocular video of a subject, we learn corresponding modules for the body, face, and hands, that are combined together to generate the final result. To capture complex finger articulation, we learn an additional deformation field for the hands. Our multi-identity representation enables simultaneous training for multiple subjects, as well as robust animation under completely unseen poses. It can also generalize to novel identities, given only a short video as input. We demonstrate state-of-the-art performance for animating full-body talking humans, with fine-grained hand articulation and facial expressions.
Centralized Selection with Preferences in the Presence of Biases
Sep 07, 2024



This paper considers the scenario in which there are multiple institutions, each with a limited capacity for candidates, and candidates, each with preferences over the institutions. A central entity evaluates the utility of each candidate to the institutions, and the goal is to select candidates for each institution in a way that maximizes utility while also considering the candidates' preferences. The paper focuses on the setting in which candidates are divided into multiple groups and the observed utilities of candidates in some groups are biased--systematically lower than their true utilities. The first result is that, in these biased settings, prior algorithms can lead to selections with sub-optimal true utility and significant discrepancies in the fraction of candidates from each group that get their preferred choices. Subsequently, an algorithm is presented along with proof that it produces selections that achieve near-optimal group fairness with respect to preferences while also nearly maximizing the true utility under distributional assumptions. Further, extensive empirical validation of these results in real-world and synthetic settings, in which the distributional assumptions may not hold, are presented.
Towards Fairness in Online Service with k Servers and its Application on Fair Food Delivery
Dec 18, 2023The k-SERVER problem is one of the most prominent problems in online algorithms with several variants and extensions. However, simplifying assumptions like instantaneous server movements and zero service time has hitherto limited its applicability to real-world problems. In this paper, we introduce a realistic generalization of k-SERVER without such assumptions - the k-FOOD problem, where requests with source-destination locations and an associated pickup time window arrive in an online fashion, and each has to be served by exactly one of the available k servers. The k-FOOD problem offers the versatility to model a variety of real-world use cases such as food delivery, ride sharing, and quick commerce. Moreover, motivated by the need for fairness in online platforms, we introduce the FAIR k-FOOD problem with the max-min objective. We establish that both k-FOOD and FAIR k-FOOD problems are strongly NP-hard and develop an optimal offline algorithm that arises naturally from a time-expanded flow network. Subsequently, we propose an online algorithm DOC4FOOD involving virtual movements of servers to the nearest request location. Experiments on a real-world food-delivery dataset, alongside synthetic datasets, establish the efficacy of the proposed algorithm against state-of-the-art fair food delivery algorithms.
Bias in Evaluation Processes: An Optimization-Based Model
Oct 26, 2023



Biases with respect to socially-salient attributes of individuals have been well documented in evaluation processes used in settings such as admissions and hiring. We view such an evaluation process as a transformation of a distribution of the true utility of an individual for a task to an observed distribution and model it as a solution to a loss minimization problem subject to an information constraint. Our model has two parameters that have been identified as factors leading to biases: the resource-information trade-off parameter in the information constraint and the risk-averseness parameter in the loss function. We characterize the distributions that arise from our model and study the effect of the parameters on the observed distribution. The outputs of our model enrich the class of distributions that can be used to capture variation across groups in the observed evaluations. We empirically validate our model by fitting real-world datasets and use it to study the effect of interventions in a downstream selection task. These results contribute to an understanding of the emergence of bias in evaluation processes and provide tools to guide the deployment of interventions to mitigate biases.
Random Separating Hyperplane Theorem and Learning Polytopes
Jul 21, 2023The Separating Hyperplane theorem is a fundamental result in Convex Geometry with myriad applications. Our first result, Random Separating Hyperplane Theorem (RSH), is a strengthening of this for polytopes. $\rsh$ asserts that if the distance between $a$ and a polytope $K$ with $k$ vertices and unit diameter in $\Re^d$ is at least $\delta$, where $\delta$ is a fixed constant in $(0,1)$, then a randomly chosen hyperplane separates $a$ and $K$ with probability at least $1/poly(k)$ and margin at least $\Omega \left(\delta/\sqrt{d} \right)$. An immediate consequence of our result is the first near optimal bound on the error increase in the reduction from a Separation oracle to an Optimization oracle over a polytope. RSH has algorithmic applications in learning polytopes. We consider a fundamental problem, denoted the ``Hausdorff problem'', of learning a unit diameter polytope $K$ within Hausdorff distance $\delta$, given an optimization oracle for $K$. Using RSH, we show that with polynomially many random queries to the optimization oracle, $K$ can be approximated within error $O(\delta)$. To our knowledge this is the first provable algorithm for the Hausdorff Problem. Building on this result, we show that if the vertices of $K$ are well-separated, then an optimization oracle can be used to generate a list of points, each within Hausdorff distance $O(\delta)$ of $K$, with the property that the list contains a point close to each vertex of $K$. Further, we show how to prune this list to generate a (unique) approximation to each vertex of the polytope. We prove that in many latent variable settings, e.g., topic modeling, LDA, optimization oracles do exist provided we project to a suitable SVD subspace. Thus, our work yields the first efficient algorithm for finding approximations to the vertices of the latent polytope under the well-separatedness assumption.
Universal Weak Coreset
May 26, 2023Coresets for $k$-means and $k$-median problems yield a small summary of the data, which preserve the clustering cost with respect to any set of $k$ centers. Recently coresets have also been constructed for constrained $k$-means and $k$-median problems. However, the notion of coresets has the drawback that (i) they can only be applied in settings where the input points are allowed to have weights, and (ii) in general metric spaces, the size of the coresets can depend logarithmically on the number of points. The notion of weak coresets, which have less stringent requirements than coresets, has been studied in the context of classical $k$-means and $k$-median problems. A weak coreset is a pair $(J,S)$ of subsets of points, where $S$ acts as a summary of the point set and $J$ as a set of potential centers. This pair satisfies the properties that (i) $S$ is a good summary of the data as long as the $k$ centers are chosen from $J$ only, and (ii) there is a good choice of $k$ centers in $J$ with cost close to the optimal cost. We develop this framework, which we call universal weak coresets, for constrained clustering settings. In conjunction with recent coreset constructions for constrained settings, our designs give greater data compression, are conceptually simpler, and apply to a wide range of constrained $k$-median and $k$-means problems.
Machine Translation by Projecting Text into the Same Phonetic-Orthographic Space Using a Common Encoding
May 21, 2023The use of subword embedding has proved to be a major innovation in Neural Machine Translation (NMT). It helps NMT to learn better context vectors for Low Resource Languages (LRLs) so as to predict the target words by better modelling the morphologies of the two languages and also the morphosyntax transfer. Even so, their performance for translation in Indian language to Indian language scenario is still not as good as for resource-rich languages. One reason for this is the relative morphological richness of Indian languages, while another is that most of them fall into the extremely low resource or zero-shot categories. Since most major Indian languages use Indic or Brahmi origin scripts, the text written in them is highly phonetic in nature and phonetically similar in terms of abstract letters and their arrangements. We use these characteristics of Indian languages and their scripts to propose an approach based on common multilingual Latin-based encodings (WX notation) that take advantage of language similarity while addressing the morphological complexity issue in NMT. These multilingual Latin-based encodings in NMT, together with Byte Pair Embedding (BPE) allow us to better exploit their phonetic and orthographic as well as lexical similarities to improve the translation quality by projecting different but similar languages on the same orthographic-phonetic character space. We verify the proposed approach by demonstrating experiments on similar language pairs (Gujarati-Hindi, Marathi-Hindi, Nepali-Hindi, Maithili-Hindi, Punjabi-Hindi, and Urdu-Hindi) under low resource conditions. The proposed approach shows an improvement in a majority of cases, in one case as much as ~10 BLEU points compared to baseline techniques for similar language pairs. We also get up to ~1 BLEU points improvement on distant and zero-shot language pairs.
Exploiting Multilingualism in Low-resource Neural Machine Translation via Adversarial Learning
Mar 31, 2023



Generative Adversarial Networks (GAN) offer a promising approach for Neural Machine Translation (NMT). However, feeding multiple morphologically languages into a single model during training reduces the NMT's performance. In GAN, similar to bilingual models, multilingual NMT only considers one reference translation for each sentence during model training. This single reference translation limits the GAN model from learning sufficient information about the source sentence representation. Thus, in this article, we propose Denoising Adversarial Auto-encoder-based Sentence Interpolation (DAASI) approach to perform sentence interpolation by learning the intermediate latent representation of the source and target sentences of multilingual language pairs. Apart from latent representation, we also use the Wasserstein-GAN approach for the multilingual NMT model by incorporating the model generated sentences of multiple languages for reward computation. This computed reward optimizes the performance of the GAN-based multilingual model in an effective manner. We demonstrate the experiments on low-resource language pairs and find that our approach outperforms the existing state-of-the-art approaches for multilingual NMT with a performance gain of up to 4 BLEU points. Moreover, we use our trained model on zero-shot language pairs under an unsupervised scenario and show the robustness of the proposed approach.
Exploiting Language Relatedness in Machine Translation Through Domain Adaptation Techniques
Mar 03, 2023



One of the significant challenges of Machine Translation (MT) is the scarcity of large amounts of data, mainly parallel sentence aligned corpora. If the evaluation is as rigorous as resource-rich languages, both Neural Machine Translation (NMT) and Statistical Machine Translation (SMT) can produce good results with such large amounts of data. However, it is challenging to improve the quality of MT output for low resource languages, especially in NMT and SMT. In order to tackle the challenges faced by MT, we present a novel approach of using a scaled similarity score of sentences, especially for related languages based on a 5-gram KenLM language model with Kneser-ney smoothing technique for filtering in-domain data from out-of-domain corpora that boost the translation quality of MT. Furthermore, we employ other domain adaptation techniques such as multi-domain, fine-tuning and iterative back-translation approach to compare our novel approach on the Hindi-Nepali language pair for NMT and SMT. Our approach succeeds in increasing ~2 BLEU point on multi-domain approach, ~3 BLEU point on fine-tuning for NMT and ~2 BLEU point on iterative back-translation approach.
A Regression Approach to Learning-Augmented Online Algorithms
May 25, 2022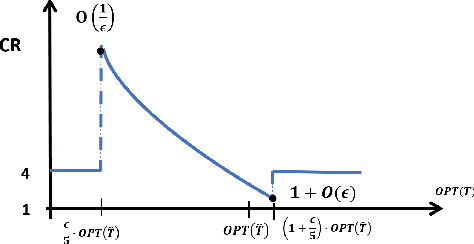
The emerging field of learning-augmented online algorithms uses ML techniques to predict future input parameters and thereby improve the performance of online algorithms. Since these parameters are, in general, real-valued functions, a natural approach is to use regression techniques to make these predictions. We introduce this approach in this paper, and explore it in the context of a general online search framework that captures classic problems like (generalized) ski rental, bin packing, minimum makespan scheduling, etc. We show nearly tight bounds on the sample complexity of this regression problem, and extend our results to the agnostic setting. From a technical standpoint, we show that the key is to incorporate online optimization benchmarks in the design of the loss function for the regression problem, thereby diverging from the use of off-the-shelf regression tools with standard bounds on statistical error.