 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLevAttention: Time, Space, and Streaming Efficient Algorithm for Heavy Attentions
Oct 07, 2024A central problem related to transformers can be stated as follows: given two $n \times d$ matrices $Q$ and $K$, and a non-negative function $f$, define the matrix $A$ as follows: (1) apply the function $f$ to each entry of the $n \times n$ matrix $Q K^T$, and then (2) normalize each of the row sums of $A$ to be equal to $1$. The matrix $A$ can be computed in $O(n^2 d)$ time assuming $f$ can be applied to a number in constant time, but the quadratic dependence on $n$ is prohibitive in applications where it corresponds to long context lengths. For a large class of functions $f$, we show how to find all the ``large attention scores", i.e., entries of $A$ which are at least a positive value $\varepsilon$, in time with linear dependence on $n$ (i.e., $n \cdot \textrm{poly}(d/\varepsilon)$) for a positive parameter $\varepsilon > 0$. Our class of functions include all functions $f$ of the form $f(x) = |x|^p$, as explored recently in transformer models. Using recently developed tools from randomized numerical linear algebra, we prove that for any $K$, there is a ``universal set" $U \subset [n]$ of size independent of $n$, such that for any $Q$ and any row $i$, the large attention scores $A_{i,j}$ in row $i$ of $A$ all have $j \in U$. We also find $U$ in $n \cdot \textrm{poly}(d/\varepsilon)$ time. Notably, we (1) make no assumptions on the data, (2) our workspace does not grow with $n$, and (3) our algorithms can be computed in streaming and parallel settings. We call the attention mechanism that uses only the subset of keys in the universal set as LevAttention since our algorithm to identify the universal set $U$ is based on leverage scores. We empirically show the benefits of our scheme for vision transformers, showing how to train new models that use our universal set while training as well, showing that our model is able to consistently select ``important keys'' during training.
Random Separating Hyperplane Theorem and Learning Polytopes
Jul 21, 2023The Separating Hyperplane theorem is a fundamental result in Convex Geometry with myriad applications. Our first result, Random Separating Hyperplane Theorem (RSH), is a strengthening of this for polytopes. $\rsh$ asserts that if the distance between $a$ and a polytope $K$ with $k$ vertices and unit diameter in $\Re^d$ is at least $\delta$, where $\delta$ is a fixed constant in $(0,1)$, then a randomly chosen hyperplane separates $a$ and $K$ with probability at least $1/poly(k)$ and margin at least $\Omega \left(\delta/\sqrt{d} \right)$. An immediate consequence of our result is the first near optimal bound on the error increase in the reduction from a Separation oracle to an Optimization oracle over a polytope. RSH has algorithmic applications in learning polytopes. We consider a fundamental problem, denoted the ``Hausdorff problem'', of learning a unit diameter polytope $K$ within Hausdorff distance $\delta$, given an optimization oracle for $K$. Using RSH, we show that with polynomially many random queries to the optimization oracle, $K$ can be approximated within error $O(\delta)$. To our knowledge this is the first provable algorithm for the Hausdorff Problem. Building on this result, we show that if the vertices of $K$ are well-separated, then an optimization oracle can be used to generate a list of points, each within Hausdorff distance $O(\delta)$ of $K$, with the property that the list contains a point close to each vertex of $K$. Further, we show how to prune this list to generate a (unique) approximation to each vertex of the polytope. We prove that in many latent variable settings, e.g., topic modeling, LDA, optimization oracles do exist provided we project to a suitable SVD subspace. Thus, our work yields the first efficient algorithm for finding approximations to the vertices of the latent polytope under the well-separatedness assumption.
Finding a latent k-simplex in O) time via Subset Smoothing
Apr 19, 2019The core problem in many Latent Variable Models, widely used in Unsupervised Learning is to find a latent k-simplex K in Rd given perturbed points from it, many of which lie far outside the simplex. This problem was stated in [2] as an open problem. We address this problem under two deterministic assumptions which replace varied stochastic assumptions specific to relevant individual models. Our first contribution is to show that the convex hull K' of the averages of all delta n sized subsets of data points is close to K. We call this subset-smoothing. While K' can have exponentially many vertices, it is easily seen to have a polynomial time Optimization Oracle which in fact runs in time O(nnz(data)). This is the starting point for our algorithm. The algorithm is simple: it has k stages in each of which we use the oracle to find maximum of a carefully chosen linear function over K'; the optimal x is an approximation to a new vertex of K. The simplicity does not carry over to the proof of correctness. The proof is involved and uses existing and new tools from Numerical Analysis, especially angles between singular spaces of close-by matrices. However, the simplicity of the algorithm, especially the fact the only way we use the data is to do matrix-vector products leads to the claimed time bound. This matches the best known algorithms in the special cases and is better when the input is sparse as indeed is the case in many applications. Our algorithm applies to many special cases, including Topic Models, Approximate Non-negative Matrix factorization, Overlapping community Detection and Clustering.
A provable SVD-based algorithm for learning topics in dominant admixture corpus
Nov 04, 2014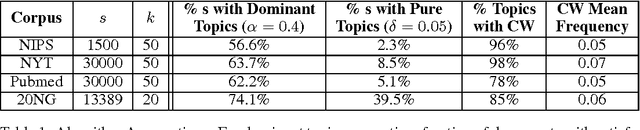
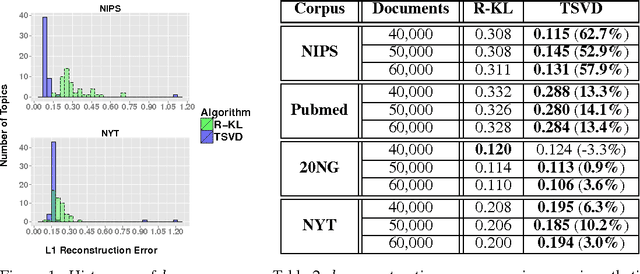
Topic models, such as Latent Dirichlet Allocation (LDA), posit that documents are drawn from admixtures of distributions over words, known as topics. The inference problem of recovering topics from admixtures, is NP-hard. Assuming separability, a strong assumption, [4] gave the first provable algorithm for inference. For LDA model, [6] gave a provable algorithm using tensor-methods. But [4,6] do not learn topic vectors with bounded $l_1$ error (a natural measure for probability vectors). Our aim is to develop a model which makes intuitive and empirically supported assumptions and to design an algorithm with natural, simple components such as SVD, which provably solves the inference problem for the model with bounded $l_1$ error. A topic in LDA and other models is essentially characterized by a group of co-occurring words. Motivated by this, we introduce topic specific Catchwords, group of words which occur with strictly greater frequency in a topic than any other topic individually and are required to have high frequency together rather than individually. A major contribution of the paper is to show that under this more realistic assumption, which is empirically verified on real corpora, a singular value decomposition (SVD) based algorithm with a crucial pre-processing step of thresholding, can provably recover the topics from a collection of documents drawn from Dominant admixtures. Dominant admixtures are convex combination of distributions in which one distribution has a significantly higher contribution than others. Apart from the simplicity of the algorithm, the sample complexity has near optimal dependence on $w_0$, the lowest probability that a topic is dominant, and is better than [4]. Empirical evidence shows that on several real world corpora, both Catchwords and Dominant admixture assumptions hold and the proposed algorithm substantially outperforms the state of the art [5].