 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePermutation-Invariant Set Autoencoders with Fixed-Size Embeddings for Multi-Agent Learning
Feb 24, 2023



The problem of permutation-invariant learning over set representations is particularly relevant in the field of multi-agent systems -- a few potential applications include unsupervised training of aggregation functions in graph neural networks (GNNs), neural cellular automata on graphs, and prediction of scenes with multiple objects. Yet existing approaches to set encoding and decoding tasks present a host of issues, including non-permutation-invariance, fixed-length outputs, reliance on iterative methods, non-deterministic outputs, computationally expensive loss functions, and poor reconstruction accuracy. In this paper we introduce a Permutation-Invariant Set Autoencoder (PISA), which tackles these problems and produces encodings with significantly lower reconstruction error than existing baselines. PISA also provides other desirable properties, including a similarity-preserving latent space, and the ability to insert or remove elements from the encoding. After evaluating PISA against baseline methods, we demonstrate its usefulness in a multi-agent application. Using PISA as a subcomponent, we introduce a novel GNN architecture which serves as a generalised communication scheme, allowing agents to use communication to gain full observability of a system.
Accelerating Multi-Agent Planning Using Graph Transformers with Bounded Suboptimality
Jan 20, 2023



Conflict-Based Search is one of the most popular methods for multi-agent path finding. Though it is complete and optimal, it does not scale well. Recent works have been proposed to accelerate it by introducing various heuristics. However, whether these heuristics can apply to non-grid-based problem settings while maintaining their effectiveness remains an open question. In this work, we find that the answer is prone to be no. To this end, we propose a learning-based component, i.e., the Graph Transformer, as a heuristic function to accelerate the planning. The proposed method is provably complete and bounded-suboptimal with any desired factor. We conduct extensive experiments on two environments with dense graphs. Results show that the proposed Graph Transformer can be trained in problem instances with relatively few agents and generalizes well to a larger number of agents, while achieving better performance than state-of-the-art methods.
Heterogeneous Multi-Robot Reinforcement Learning
Jan 17, 2023Cooperative multi-robot tasks can benefit from heterogeneity in the robots' physical and behavioral traits. In spite of this, traditional Multi-Agent Reinforcement Learning (MARL) frameworks lack the ability to explicitly accommodate policy heterogeneity, and typically constrain agents to share neural network parameters. This enforced homogeneity limits application in cases where the tasks benefit from heterogeneous behaviors. In this paper, we crystallize the role of heterogeneity in MARL policies. Towards this end, we introduce Heterogeneous Graph Neural Network Proximal Policy Optimization (HetGPPO), a paradigm for training heterogeneous MARL policies that leverages a Graph Neural Network for differentiable inter-agent communication. HetGPPO allows communicating agents to learn heterogeneous behaviors while enabling fully decentralized training in partially observable environments. We complement this with a taxonomical overview that exposes more heterogeneity classes than previously identified. To motivate the need for our model, we present a characterization of techniques that homogeneous models can leverage to emulate heterogeneous behavior, and show how this "apparent heterogeneity" is brittle in real-world conditions. Through simulations and real-world experiments, we show that: (i) when homogeneous methods fail due to strong heterogeneous requirements, HetGPPO succeeds, and, (ii) when homogeneous methods are able to learn apparently heterogeneous behaviors, HetGPPO achieves higher resilience to both training and deployment noise.
Decentralized Channel Management in WLANs with Graph Neural Networks
Oct 30, 2022



Wireless local area networks (WLANs) manage multiple access points (APs) and assign scarce radio frequency resources to APs for satisfying traffic demands of associated user devices. This paper considers the channel allocation problem in WLANs that minimizes the mutual interference among APs, and puts forth a learning-based solution that can be implemented in a decentralized manner. We formulate the channel allocation problem as an unsupervised learning problem, parameterize the control policy of radio channels with graph neural networks (GNNs), and train GNNs with the policy gradient method in a model-free manner. The proposed approach allows for a decentralized implementation due to the distributed nature of GNNs and is equivariant to network permutations. The former provides an efficient and scalable solution for large network scenarios, and the latter renders our algorithm independent of the AP reordering. Empirical results are presented to evaluate the proposed approach and corroborate theoretical findings.
Environment Optimization for Multi-Agent Navigation
Sep 22, 2022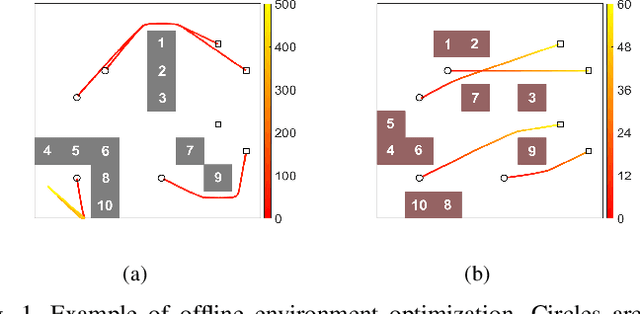
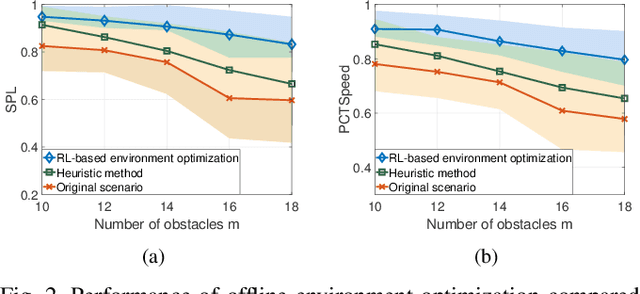
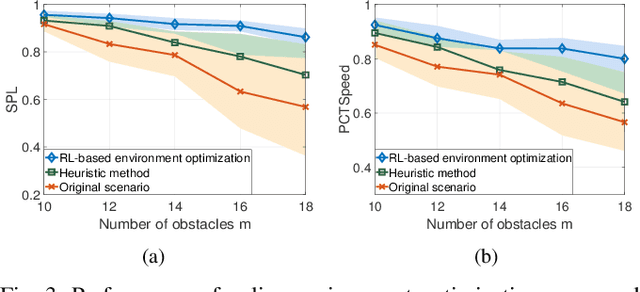
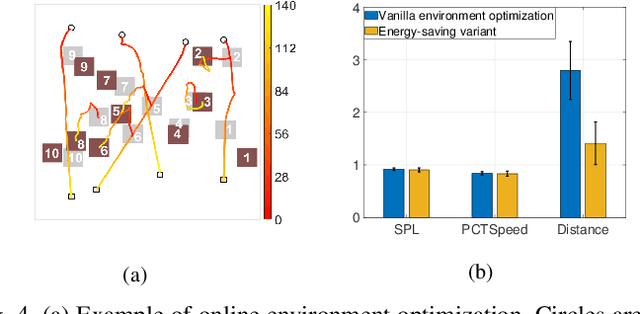
Traditional approaches to the design of multi-agent navigation algorithms consider the environment as a fixed constraint, despite the obvious influence of spatial constraints on agents' performance. Yet hand-designing improved environment layouts and structures is inefficient and potentially expensive. The goal of this paper is to consider the environment as a decision variable in a system-level optimization problem, where both agent performance and environment cost can be accounted for. We begin by proposing a novel environment optimization problem. We show, through formal proofs, under which conditions the environment can change while guaranteeing completeness (i.e., all agents reach their navigation goals). Our solution leverages a model-free reinforcement learning approach. In order to accommodate a broad range of implementation scenarios, we include both online and offline optimization, and both discrete and continuous environment representations. Numerical results corroborate our theoretical findings and validate our approach.
Learning to Navigate using Visual Sensor Networks
Aug 05, 2022
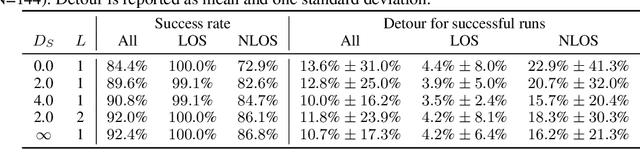
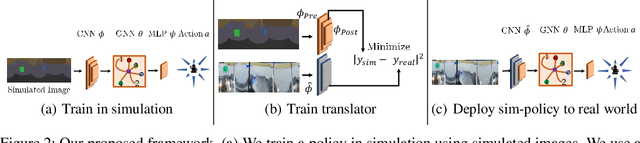
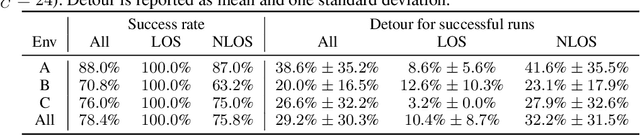
We consider the problem of navigating a mobile robot towards a target in an unknown environment that is endowed with visual sensors, where neither the robot nor the sensors have access to global positioning information and only use first-person-view images. While prior work in sensor network-based navigation uses explicit mapping and planning techniques, and is often aided by external positioning systems, we propose a vision-only based learning approach that leverages a Graph Neural Network (GNN) to encode and communicate relevant viewpoint information to the mobile robot. During navigation, the robot is guided by a model that we train through imitation learning to approximate optimal motion primitives, thereby predicting the effective cost-to-go (to the target). In our experiments, we first demonstrate generalizability to previously unseen environments with various sensor layouts. The results show that communication among the sensors and robot facilitates a significant improvement in success rate while decreasing path detour mean and variability. This is done without requiring a global map, positioning data, nor pre-calibration of the sensor network. Second, we perform a zero-shot transfer of our model from simulation to the real world. To this end, we train a`translator' model that translates between {latent encodings of} real and simulated images so that the navigation policy (which is trained entirely in simulation) can be used directly on the real robot, without additional fine-tuning. Physical experiments demonstrate the feasibility of our approach in various cluttered environments.
On the properties of path additions for traffic routing
Jul 10, 2022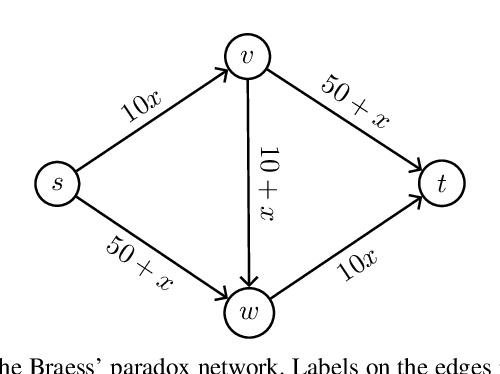
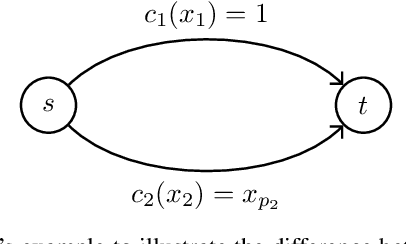
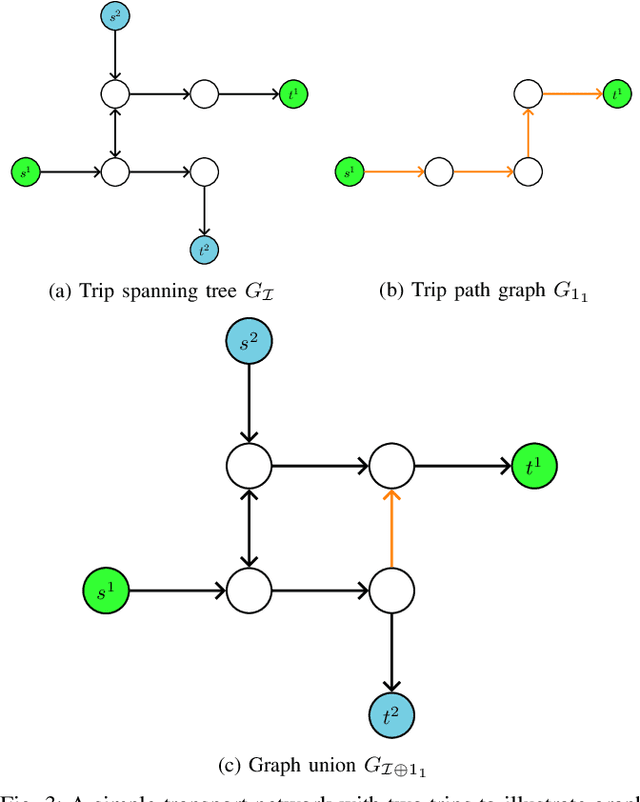
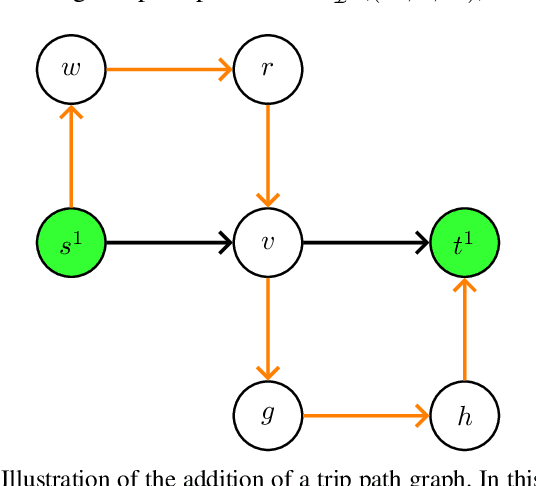
In this paper we investigate the impact of path additions to transport networks with optimised traffic routing. In particular, we study the behaviour of total travel time, and consider both self-interested routing paradigms, such as User Equilibrium (UE) routing, as well as cooperative paradigms, such as classic Multi-Commodity (MC) network flow and System Optimal (SO) routing. We provide a formal framework for designing transport networks through iterative path additions, introducing the concepts of trip spanning tree and trip path graph. Using this formalisation, we prove multiple properties of the objective function for transport network design. Since the underlying routing problem is NP-Hard, we investigate properties that provide guarantees in approximate algorithm design. Firstly, while Braess' paradox has shown that total travel time is not monotonic non-increasing with respect to path additions under self-interested routing (UE), we prove that, instead, monotonicity holds for cooperative routing (MC and SO). This result has the important implication that cooperative agents make the best use of redundant infrastructure. Secondly, we prove via a counterexample that the intuitive statement `adding a path to a transport network always grants greater or equal benefit to users than adding it to a superset of that network' is false. In other words we prove that, for all the routing formulations studied, total travel time is not supermodular with respect to path additions. While this counter-intuitive result yields a hardness property for algorithm design, we provide particular instances where, instead, the property of supermodularity holds. Our study on monotonicity and supermodularity of total travel time with respect to path additions provides formal proofs and scenarios that constitute important insights for transport network designers.
VMAS: A Vectorized Multi-Agent Simulator for Collective Robot Learning
Jul 07, 2022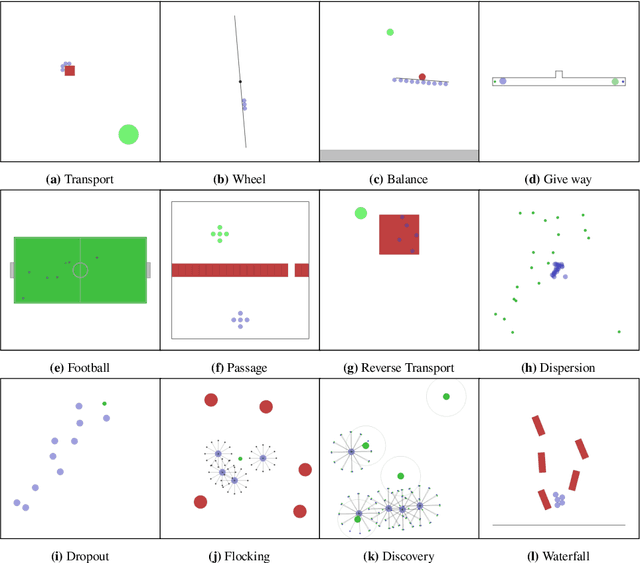
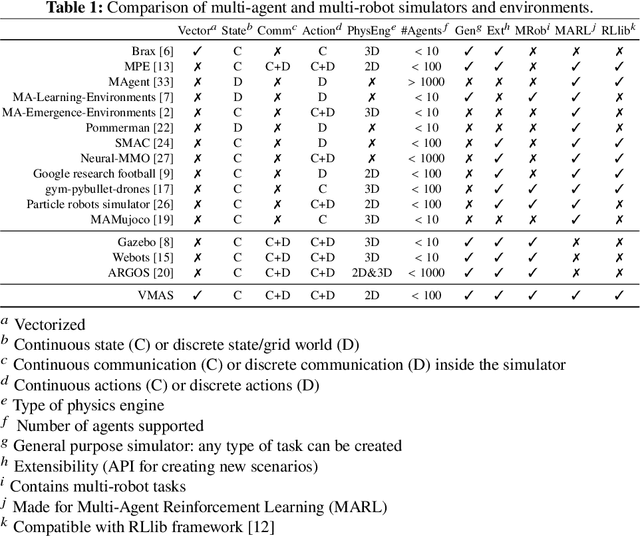
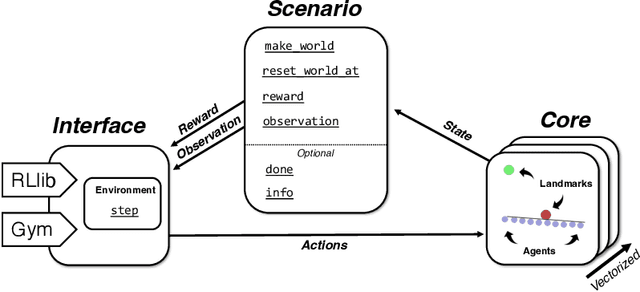
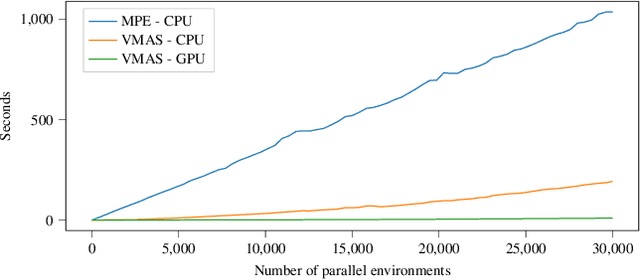
While many multi-robot coordination problems can be solved optimally by exact algorithms, solutions are often not scalable in the number of robots. Multi-Agent Reinforcement Learning (MARL) is gaining increasing attention in the robotics community as a promising solution to tackle such problems. Nevertheless, we still lack the tools that allow us to quickly and efficiently find solutions to large-scale collective learning tasks. In this work, we introduce the Vectorized Multi-Agent Simulator (VMAS). VMAS is an open-source framework designed for efficient MARL benchmarking. It is comprised of a vectorized 2D physics engine written in PyTorch and a set of twelve challenging multi-robot scenarios. Additional scenarios can be implemented through a simple and modular interface. We demonstrate how vectorization enables parallel simulation on accelerated hardware without added complexity. When comparing VMAS to OpenAI MPE, we show how MPE's execution time increases linearly in the number of simulations while VMAS is able to execute 30,000 parallel simulations in under 10s, proving more than 100x faster. Using VMAS's RLlib interface, we benchmark our multi-robot scenarios using various Proximal Policy Optimization (PPO)-based MARL algorithms. VMAS's scenarios prove challenging in orthogonal ways for state-of-the-art MARL algorithms. The VMAS framework is available at https://github.com/proroklab/VectorizedMultiAgentSimulator. A video of VMAS scenarios and experiments is available at https://youtu.be/aaDRYfiesAY}{here}\footnote{\url{https://youtu.be/aaDRYfiesAY.
A Critical Review of Communications in Multi-Robot Systems
Jun 19, 2022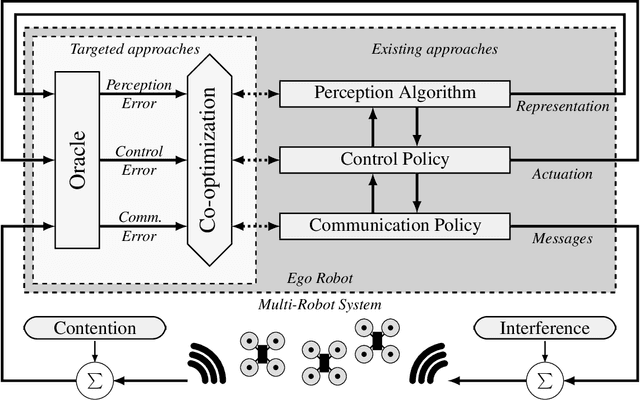
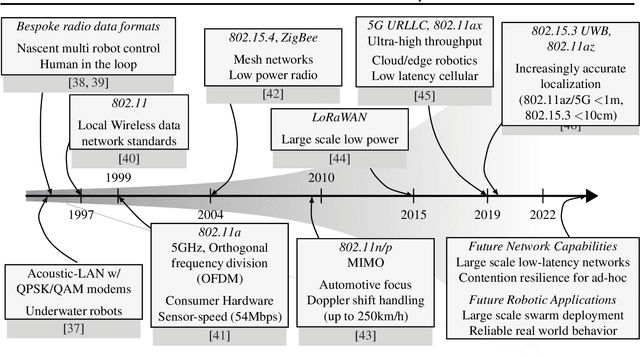
Purpose of Review. This review summarizes the broad roles that communication formats and technologies have played in enabling multi-robot systems. We approach this field from two perspectives: of robotic applications that need communication capabilities in order to accomplish tasks, and of networking technologies that have enabled newer and more advanced multi-robot systems. Recent Findings. Through this review, we identify a dearth of work that holistically tackles the problem of co-design and co-optimization of robots and the networks they employ. We also highlight the role that data-driven and machine learning approaches play in evolving communication pipelines for multi-robot systems. In particular, we refer to recent work that diverges from hand-designed communication patterns, and also discuss the "sim-to-real" gap in this context. Summary. We present a critical view of the way robotic algorithms and their networking systems have evolved, and make the case for a more synergistic approach. Finally, we also identify four broad Open Problems for research and development, while offering a data-driven perspective for solving some of them.
QGNN: Value Function Factorisation with Graph Neural Networks
May 25, 2022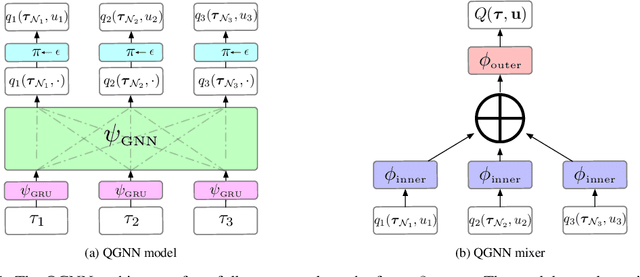
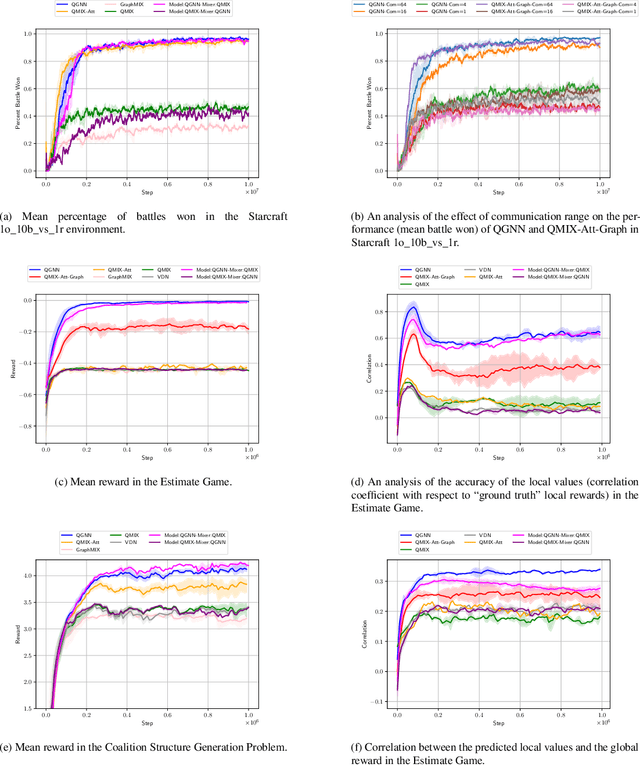
In multi-agent reinforcement learning, the use of a global objective is a powerful tool for incentivising cooperation. Unfortunately, it is not sample-efficient to train individual agents with a global reward, because it does not necessarily correlate with an agent's individual actions. This problem can be solved by factorising the global value function into local value functions. Early work in this domain performed factorisation by conditioning local value functions purely on local information. Recently, it has been shown that providing both local information and an encoding of the global state can promote cooperative behaviour. In this paper we propose QGNN, the first value factorisation method to use a graph neural network (GNN) based model. The multi-layer message passing architecture of QGNN provides more representational complexity than models in prior work, allowing it to produce a more effective factorisation. QGNN also introduces a permutation invariant mixer which is able to match the performance of other methods, even with significantly fewer parameters. We evaluate our method against several baselines, including QMIX-Att, GraphMIX, QMIX, VDN, and hybrid architectures. Our experiments include Starcraft, the standard benchmark for credit assignment; Estimate Game, a custom environment that explicitly models inter-agent dependencies; and Coalition Structure Generation, a foundational problem with real-world applications. The results show that QGNN outperforms state-of-the-art value factorisation baselines consistently.