 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAugmenting BERT-style Models with Predictive Coding to Improve Discourse-level Representations
Sep 10, 2021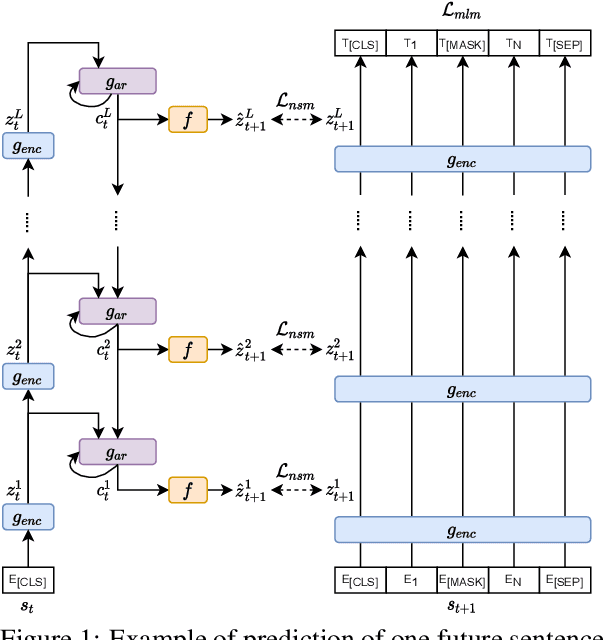
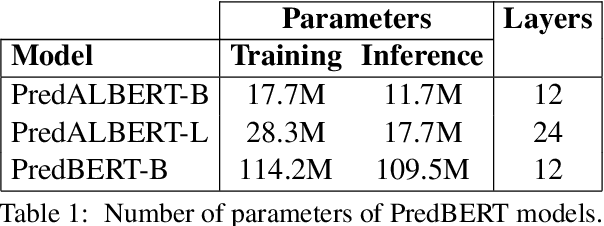
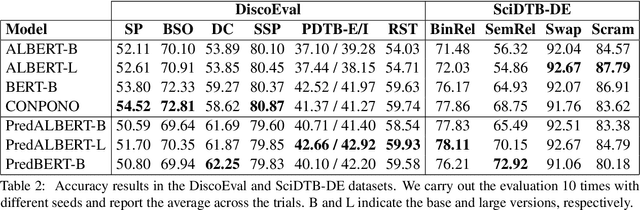
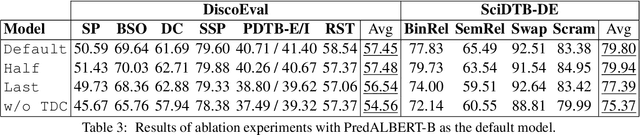
Current language models are usually trained using a self-supervised scheme, where the main focus is learning representations at the word or sentence level. However, there has been limited progress in generating useful discourse-level representations. In this work, we propose to use ideas from predictive coding theory to augment BERT-style language models with a mechanism that allows them to learn suitable discourse-level representations. As a result, our proposed approach is able to predict future sentences using explicit top-down connections that operate at the intermediate layers of the network. By experimenting with benchmarks designed to evaluate discourse-related knowledge using pre-trained sentence representations, we demonstrate that our approach improves performance in 6 out of 11 tasks by excelling in discourse relationship detection.
DeepSocNav: Social Navigation by Imitating Human Behaviors
Jul 19, 2021
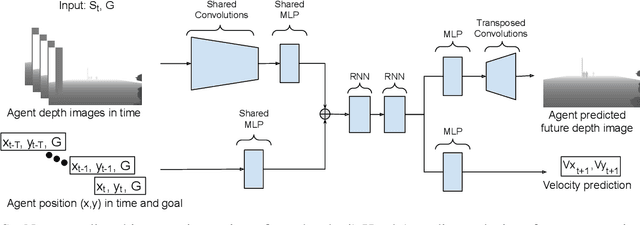
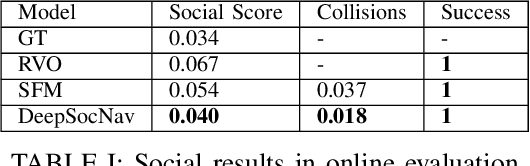
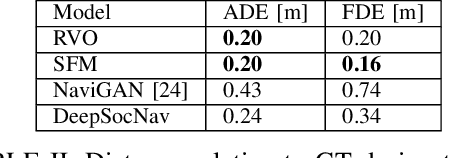
Current datasets to train social behaviors are usually borrowed from surveillance applications that capture visual data from a bird's-eye perspective. This leaves aside precious relationships and visual cues that could be captured through a first-person view of a scene. In this work, we propose a strategy to exploit the power of current game engines, such as Unity, to transform pre-existing bird's-eye view datasets into a first-person view, in particular, a depth view. Using this strategy, we are able to generate large volumes of synthetic data that can be used to pre-train a social navigation model. To test our ideas, we present DeepSocNav, a deep learning based model that takes advantage of the proposed approach to generate synthetic data. Furthermore, DeepSocNav includes a self-supervised strategy that is included as an auxiliary task. This consists of predicting the next depth frame that the agent will face. Our experiments show the benefits of the proposed model that is able to outperform relevant baselines in terms of social navigation scores.
TNT: Text-Conditioned Network with Transductive Inference for Few-Shot Video Classification
Jun 21, 2021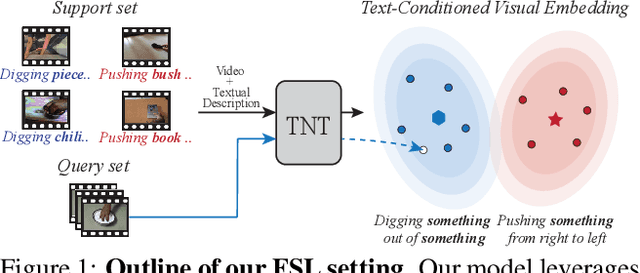
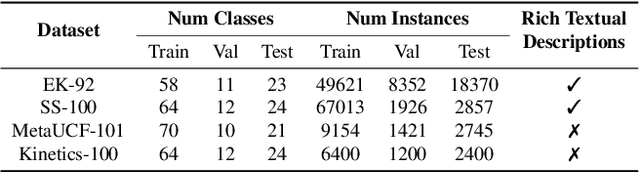
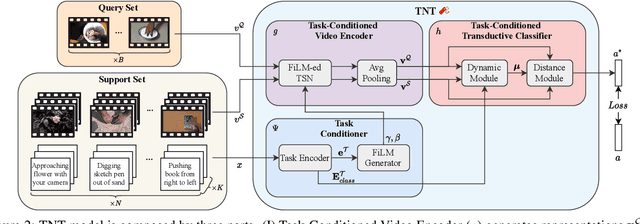
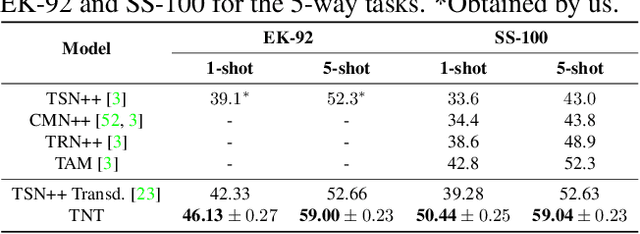
Recently, few-shot learning has received increasing interest. Existing efforts have been focused on image classification, with very few attempts dedicated to the more challenging few-shot video classification problem. These few attempts aim to effectively exploit the temporal dimension in videos for better learning in low data regimes. However, they have largely ignored a key characteristic of video which could be vital for few-shot recognition, that is, videos are often accompanied by rich text descriptions. In this paper, for the first time, we propose to leverage these human-provided textual descriptions as privileged information when training a few-shot video classification model. Specifically, we formulate a text-based task conditioner to adapt video features to the few-shot learning task. Our model follows a transductive setting where query samples and support textual descriptions can be used to update the support set class prototype to further improve the task-adaptation ability of the model. Our model obtains state-of-the-art performance on four challenging benchmarks in few-shot video action classification.
Optimizing Reusable Knowledge for Continual Learning via Metalearning
Jun 09, 2021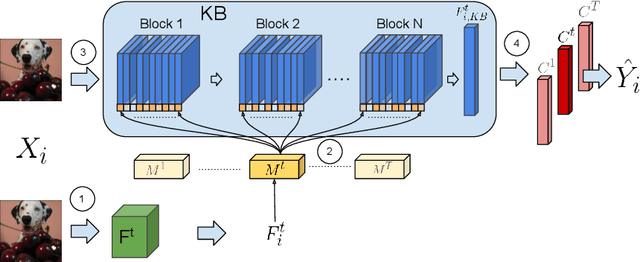
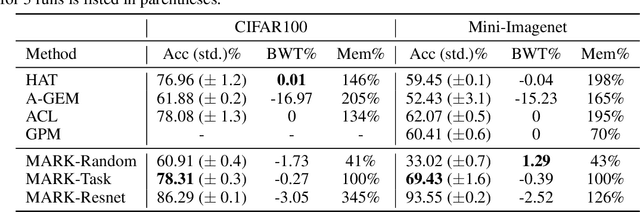
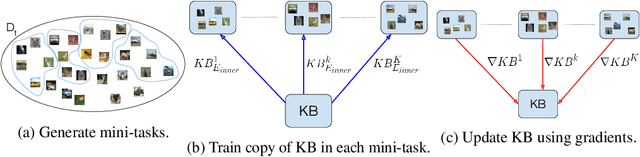
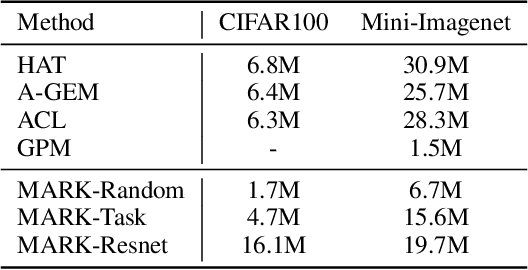
When learning tasks over time, artificial neural networks suffer from a problem known as Catastrophic Forgetting (CF). This happens when the weights of a network are overwritten during the training of a new task causing forgetting of old information. To address this issue, we propose MetA Reusable Knowledge or MARK, a new method that fosters weight reusability instead of overwriting when learning a new task. Specifically, MARK keeps a set of shared weights among tasks. We envision these shared weights as a common Knowledge Base (KB) that is not only used to learn new tasks, but also enriched with new knowledge as the model learns new tasks. Key components behind MARK are two-fold. On the one hand, a metalearning approach provides the key mechanism to incrementally enrich the KB with new knowledge and to foster weight reusability among tasks. On the other hand, a set of trainable masks provides the key mechanism to selectively choose from the KB relevant weights to solve each task. By using MARK, we achieve state of the art results in several popular benchmarks, surpassing the best performing methods in terms of average accuracy by over 10% on the 20-Split-MiniImageNet dataset, while achieving almost zero forgetfulness using 55% of the number of parameters. Furthermore, an ablation study provides evidence that, indeed, MARK is learning reusable knowledge that is selectively used by each task.
Inspecting the concept knowledge graph encoded by modern language models
Jun 02, 2021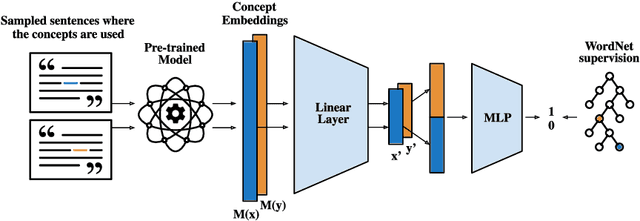
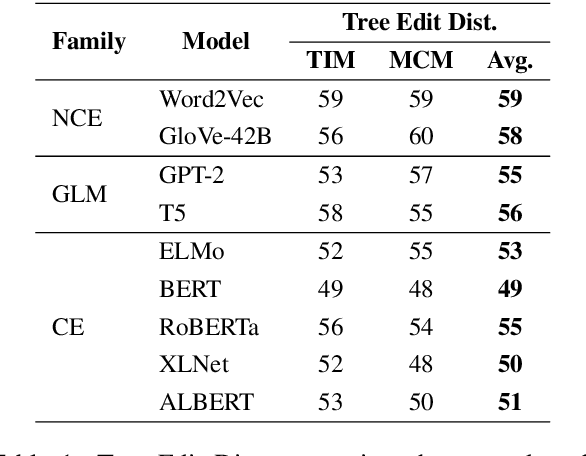
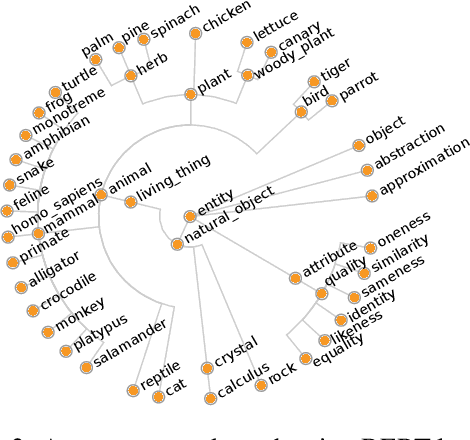
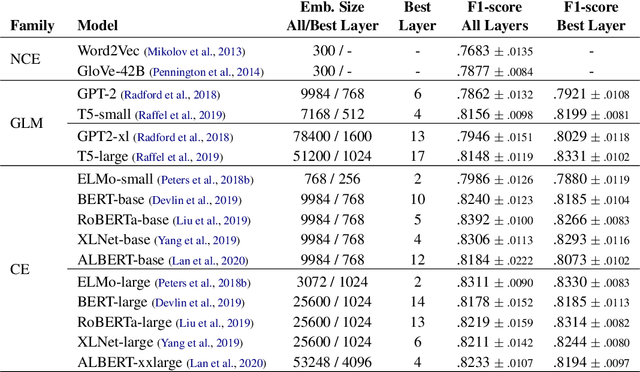
The field of natural language understanding has experienced exponential progress in the last few years, with impressive results in several tasks. This success has motivated researchers to study the underlying knowledge encoded by these models. Despite this, attempts to understand their semantic capabilities have not been successful, often leading to non-conclusive, or contradictory conclusions among different works. Via a probing classifier, we extract the underlying knowledge graph of nine of the most influential language models of the last years, including word embeddings, text generators, and context encoders. This probe is based on concept relatedness, grounded on WordNet. Our results reveal that all the models encode this knowledge, but suffer from several inaccuracies. Furthermore, we show that the different architectures and training strategies lead to different model biases. We conduct a systematic evaluation to discover specific factors that explain why some concepts are challenging. We hope our insights will motivate the development of models that capture concepts more precisely.
A Survey on Deep Learning and Explainability for Automatic Image-based Medical Report Generation
Oct 20, 2020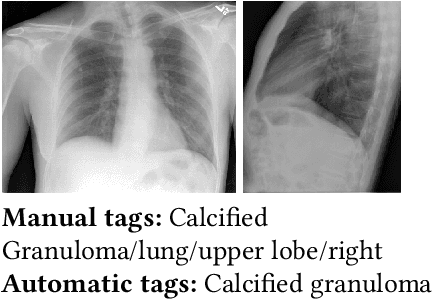
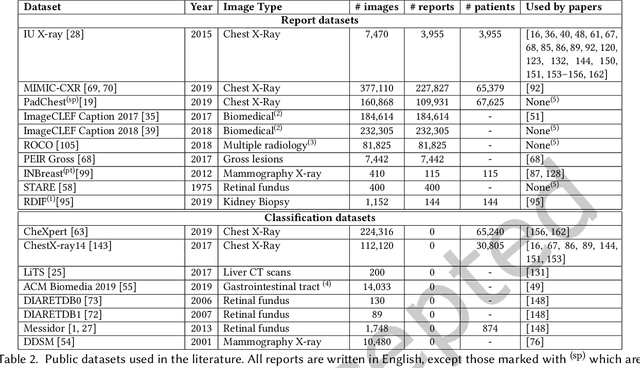
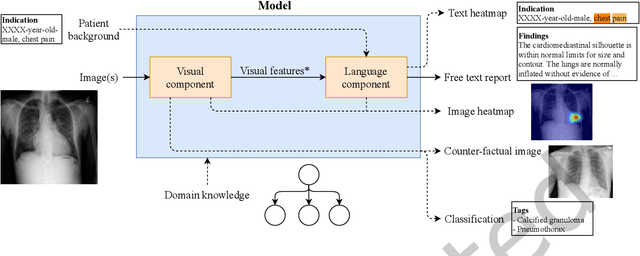
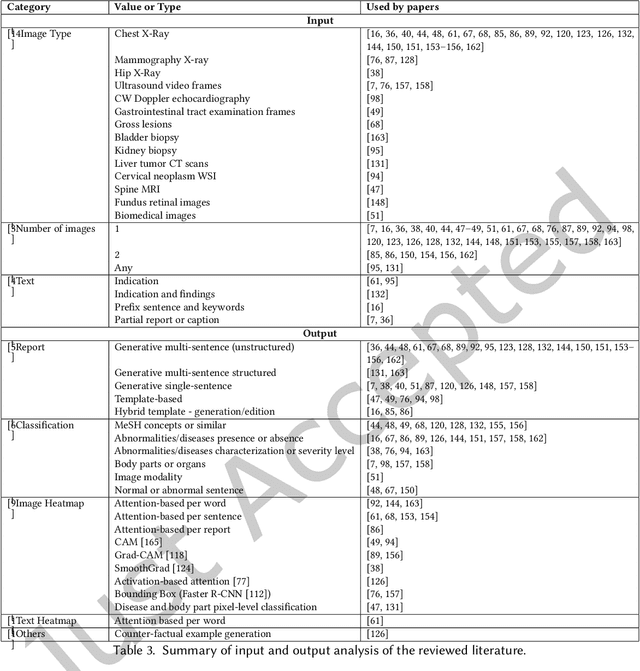
Every year physicians face an increasing demand of image-based diagnosis from patients, a problem that can be addressed with recent artificial intelligence methods. In this context, we survey works in the area of automatic report generation from medical images, with emphasis on methods using deep neural networks, with respect to: (1) Datasets, (2) Architecture Design, (3) Explainability and (4) Evaluation Metrics. Our survey identifies interesting developments, but also remaining challenges. Among them, the current evaluation of generated reports is especially weak, since it mostly relies on traditional Natural Language Processing (NLP) metrics, which do not accurately capture medical correctness.
Translating Natural Language Instructions for Behavioral Robot Navigation with a Multi-Head Attention Mechanism
Jun 07, 2020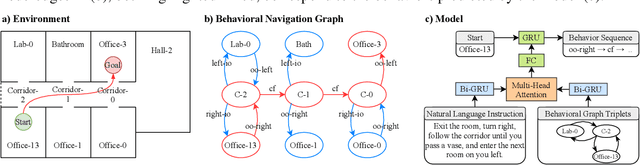

We propose a multi-head attention mechanism as a blending layer in a neural network model that translates natural language to a high level behavioral language for indoor robot navigation. We follow the framework established by (Zang et al., 2018a) that proposes the use of a navigation graph as a knowledge base for the task. Our results show significant performance gains when translating instructions on previously unseen environments, therefore, improving the generalization capabilities of the model.
Differentiable Adaptive Computation Time for Visual Reasoning
May 22, 2020
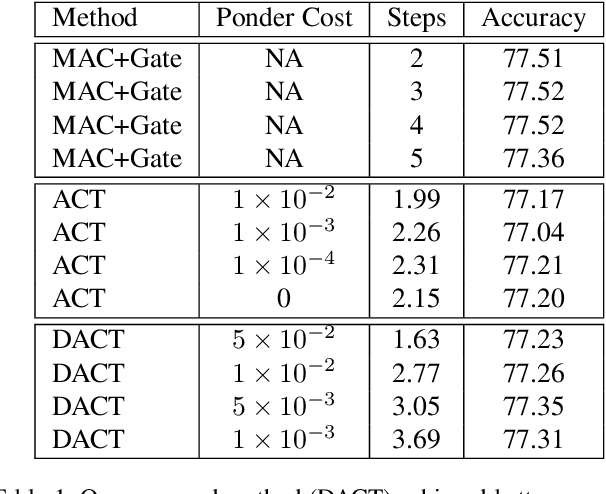
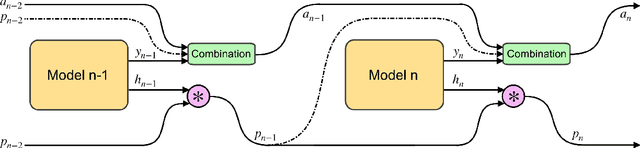
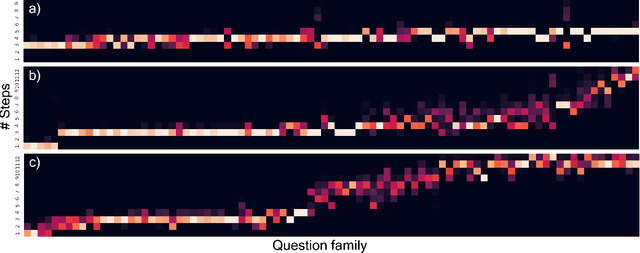
This paper presents a novel attention-based algorithm for achieving adaptive computation called DACT, which, unlike existing ones, is end-to-end differentiable. Our method can be used in conjunction with many networks; in particular, we study its application to the widely known MAC architecture, obtaining a significant reduction in the number of recurrent steps needed to achieve similar accuracies, therefore improving its performance to computation ratio. Furthermore, we show that by increasing the maximum number of steps used, we surpass the accuracy of even our best non-adaptive MAC in the CLEVR dataset, demonstrating that our approach is able to control the number of steps without significant loss of performance. Additional advantages provided by our approach include considerably improving interpretability by discarding useless steps and providing more insights into the underlying reasoning process. Finally, we present adaptive computation as an equivalent to an ensemble of models, similar to a mixture of expert formulation. Both the code and the configuration files for our experiments are made available to support further research in this area.
A Behavioral Approach to Visual Navigation with Graph Localization Networks
Mar 01, 2019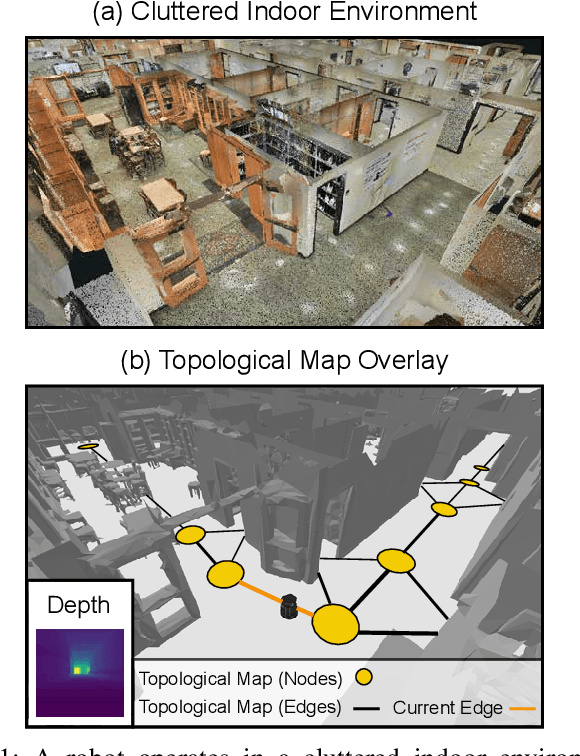
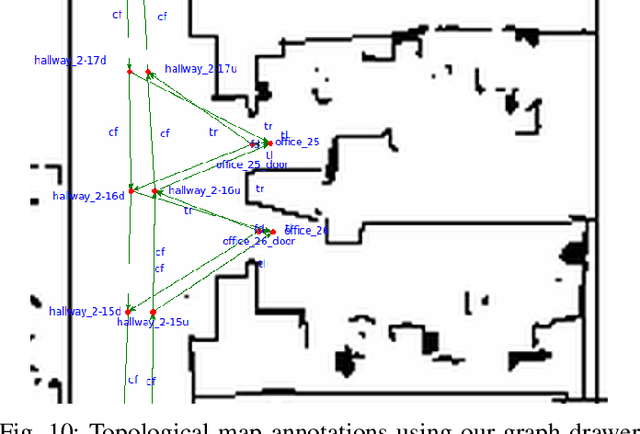


Inspired by research in psychology, we introduce a behavioral approach for visual navigation using topological maps. Our goal is to enable a robot to navigate from one location to another, relying only on its visual input and the topological map of the environment. We propose using graph neural networks for localizing the agent in the map, and decompose the action space into primitive behaviors implemented as convolutional or recurrent neural networks. Using the Gibson simulator, we verify that our approach outperforms relevant baselines and is able to navigate in both seen and unseen environments.
Translating Navigation Instructions in Natural Language to a High-Level Plan for Behavioral Robot Navigation
Sep 24, 2018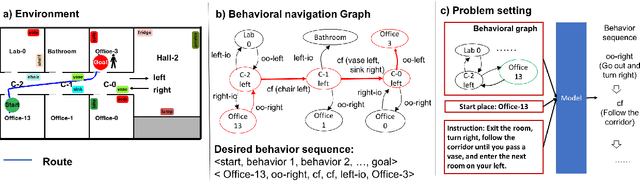

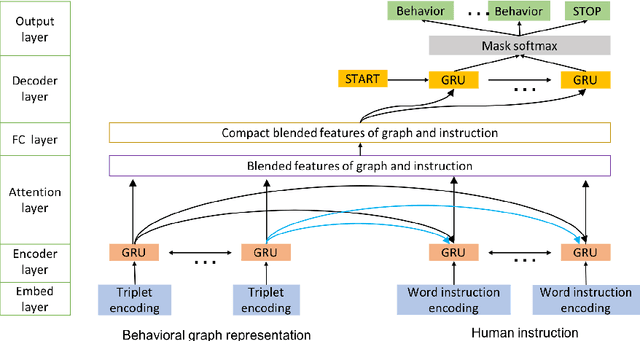
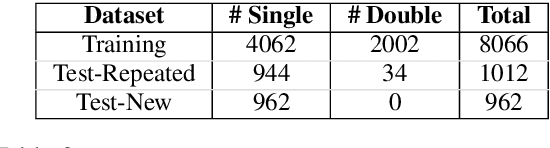
We propose an end-to-end deep learning model for translating free-form natural language instructions to a high-level plan for behavioral robot navigation. We use attention models to connect information from both the user instructions and a topological representation of the environment. We evaluate our model's performance on a new dataset containing 10,050 pairs of navigation instructions. Our model significantly outperforms baseline approaches. Furthermore, our results suggest that it is possible to leverage the environment map as a relevant knowledge base to facilitate the translation of free-form navigational instruction.