 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWorkBench: a Benchmark Dataset for Agents in a Realistic Workplace Setting
May 01, 2024We introduce WorkBench: a benchmark dataset for evaluating agents' ability to execute tasks in a workplace setting. WorkBench contains a sandbox environment with five databases, 26 tools, and 690 tasks. These tasks represent common business activities, such as sending emails and scheduling meetings. The tasks in WorkBench are challenging as they require planning, tool selection, and often multiple actions. If a task has been successfully executed, one (or more) of the database values may change. The correct outcome for each task is unique and unambiguous, which allows for robust, automated evaluation. We call this key contribution outcome-centric evaluation. We evaluate five existing ReAct agents on WorkBench, finding they successfully complete as few as 3% of tasks (Llama2-70B), and just 43% for the best-performing (GPT-4). We further find that agents' errors can result in the wrong action being taken, such as an email being sent to the wrong person. WorkBench reveals weaknesses in agents' ability to undertake common business activities, raising questions about their use in high-stakes workplace settings. WorkBench is publicly available as a free resource at https://github.com/olly-styles/WorkBench.
CuratorNet: Visually-aware Recommendation of Art Images
Sep 30, 2020
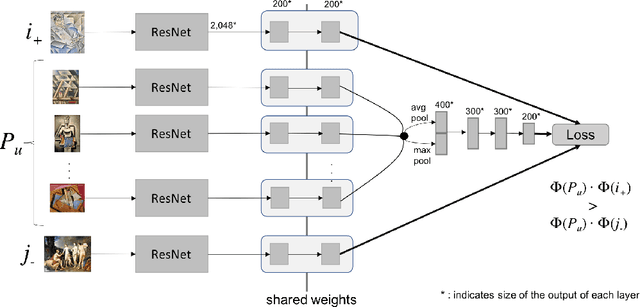

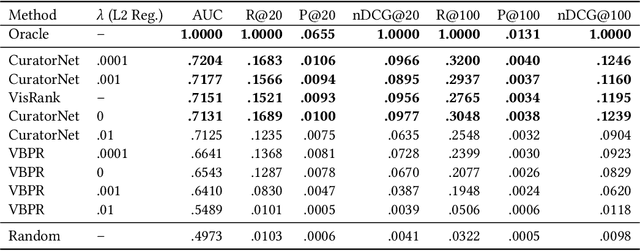
Although there are several visually-aware recommendation models in domains like fashion or even movies, the art domain lacks thesame level of research attention, despite the recent growth of the online artwork market. To reduce this gap, in this article we introduceCuratorNet, a neural network architecture for visually-aware recommendation of art images. CuratorNet is designed at the core withthe goal of maximizing generalization: the network has a fixed set of parameters that only need to be trained once, and thereafter themodel is able to generalize to new users or items never seen before, without further training. This is achieved by leveraging visualcontent: items are mapped to item vectors through visual embeddings, and users are mapped to user vectors by aggregating the visualcontent of items they have consumed. Besides the model architecture, we also introduce novel triplet sampling strategies to build atraining set for rank learning in the art domain, resulting in more effective learning than naive random sampling. With an evaluationover a real-world dataset of physical paintings, we show that CuratorNet achieves the best performance among several baselines,including the state-of-the-art model VBPR. CuratorNet is motivated and evaluated in the art domain, but its architecture and trainingscheme could be adapted to recommend images in other areas
Translating Natural Language Instructions for Behavioral Robot Navigation with a Multi-Head Attention Mechanism
Jun 07, 2020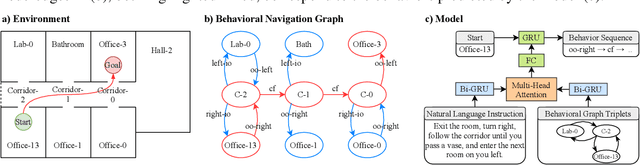

We propose a multi-head attention mechanism as a blending layer in a neural network model that translates natural language to a high level behavioral language for indoor robot navigation. We follow the framework established by (Zang et al., 2018a) that proposes the use of a navigation graph as a knowledge base for the task. Our results show significant performance gains when translating instructions on previously unseen environments, therefore, improving the generalization capabilities of the model.