 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuantifying Adaptability in Pre-trained Language Models with 500 Tasks
Dec 06, 2021
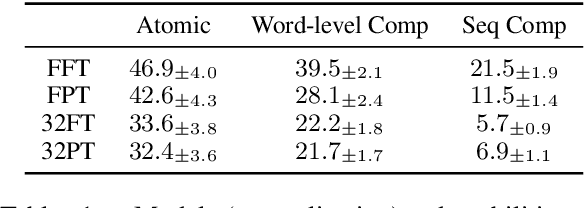
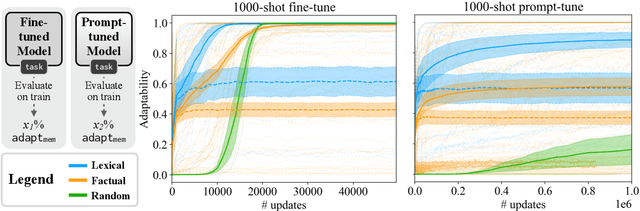

When a neural language model (LM) is adapted to perform a new task, what aspects of the task predict the eventual performance of the model? In NLP, systematic features of LM generalization to individual examples are well characterized, but systematic aspects of LM adaptability to new tasks are not nearly as well understood. We present a large-scale empirical study of the features and limits of LM adaptability using a new benchmark, TaskBench500, built from 500 procedurally generated sequence modeling tasks. These tasks combine core aspects of language processing, including lexical semantics, sequence processing, memorization, logical reasoning, and world knowledge. Using TaskBench500, we evaluate three facets of adaptability, finding that: (1) adaptation procedures differ dramatically in their ability to memorize small datasets; (2) within a subset of task types, adaptation procedures exhibit compositional adaptability to complex tasks; and (3) failure to match training label distributions is explained by mismatches in the intrinsic difficulty of predicting individual labels. Our experiments show that adaptability to new tasks, like generalization to new examples, can be systematically described and understood, and we conclude with a discussion of additional aspects of adaptability that could be studied using the new benchmark.
Detecting Inspiring Content on Social Media
Sep 06, 2021
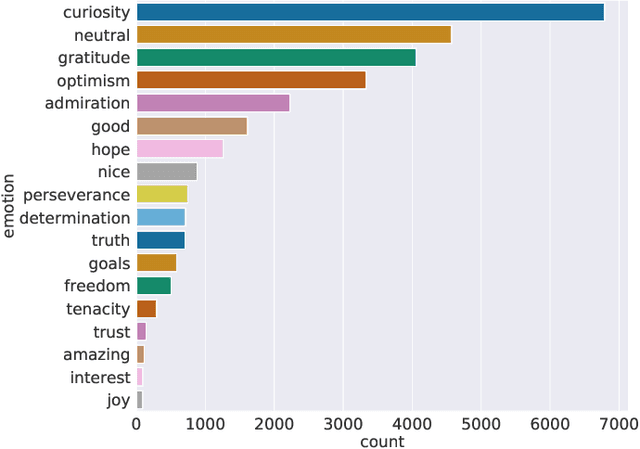
Inspiration moves a person to see new possibilities and transforms the way they perceive their own potential. Inspiration has received little attention in psychology, and has not been researched before in the NLP community. To the best of our knowledge, this work is the first to study inspiration through machine learning methods. We aim to automatically detect inspiring content from social media data. To this end, we analyze social media posts to tease out what makes a post inspiring and what topics are inspiring. We release a dataset of 5,800 inspiring and 5,800 non-inspiring English-language public post unique ids collected from a dump of Reddit public posts made available by a third party and use linguistic heuristics to automatically detect which social media English-language posts are inspiring.
Database Reasoning Over Text
Jun 02, 2021
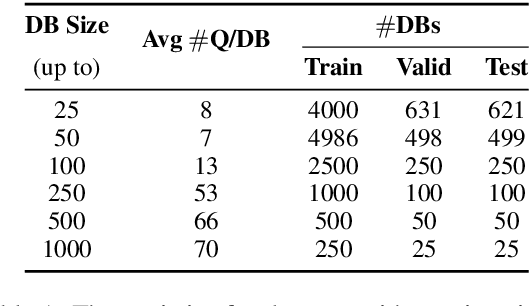

Neural models have shown impressive performance gains in answering queries from natural language text. However, existing works are unable to support database queries, such as "List/Count all female athletes who were born in 20th century", which require reasoning over sets of relevant facts with operations such as join, filtering and aggregation. We show that while state-of-the-art transformer models perform very well for small databases, they exhibit limitations in processing noisy data, numerical operations, and queries that aggregate facts. We propose a modular architecture to answer these database-style queries over multiple spans from text and aggregating these at scale. We evaluate the architecture using WikiNLDB, a novel dataset for exploring such queries. Our architecture scales to databases containing thousands of facts whereas contemporary models are limited by how many facts can be encoded. In direct comparison on small databases, our approach increases overall answer accuracy from 85% to 90%. On larger databases, our approach retains its accuracy whereas transformer baselines could not encode the context.
Neural Databases
Oct 14, 2020
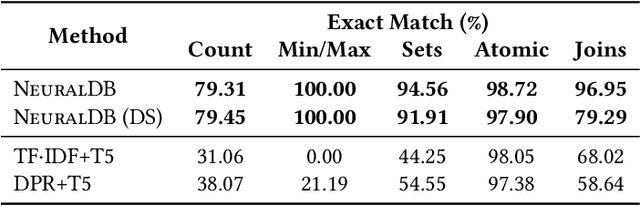
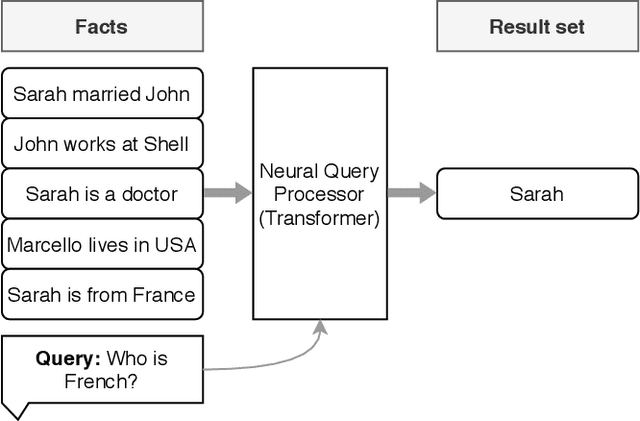

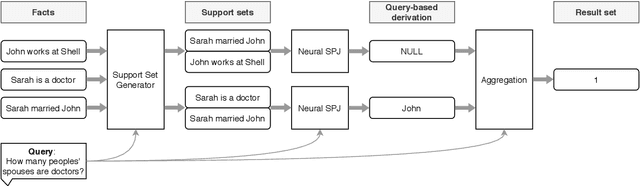
In recent years, neural networks have shown impressive performance gains on long-standing AI problems, and in particular, answering queries from natural language text. These advances raise the question of whether they can be extended to a point where we can relax the fundamental assumption of database management, namely, that our data is represented as fields of a pre-defined schema. This paper presents a first step in answering that question. We describe NeuralDB, a database system with no pre-defined schema, in which updates and queries are given in natural language. We develop query processing techniques that build on the primitives offered by the state of the art Natural Language Processing methods. We begin by demonstrating that at the core, recent NLP transformers, powered by pre-trained language models, can answer select-project-join queries if they are given the exact set of relevant facts. However, they cannot scale to non-trivial databases and cannot perform aggregation queries. Based on these findings, we describe a NeuralDB architecture that runs multiple Neural SPJ operators in parallel, each with a set of database sentences that can produce one of the answers to the query. The result of these operators is fed to an aggregation operator if needed. We describe an algorithm that learns how to create the appropriate sets of facts to be fed into each of the Neural SPJ operators. Importantly, this algorithm can be trained by the Neural SPJ operator itself. We experimentally validate the accuracy of NeuralDB and its components, showing that we can answer queries over thousands of sentences with very high accuracy.
Preserving Integrity in Online Social Networks
Sep 25, 2020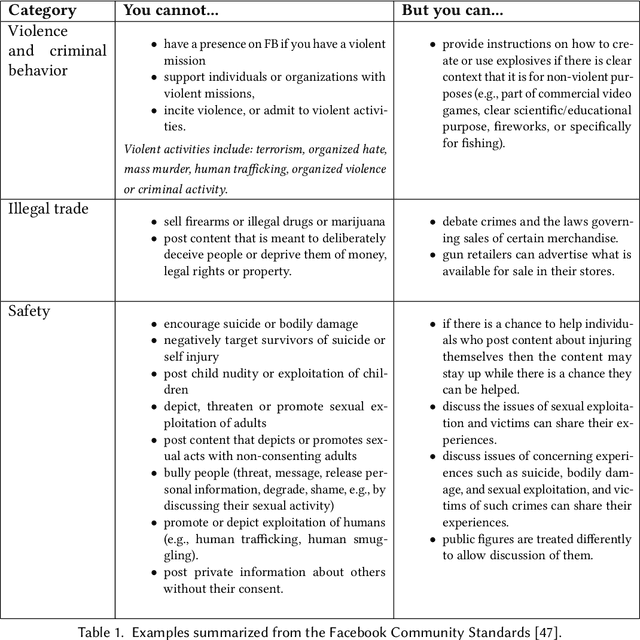
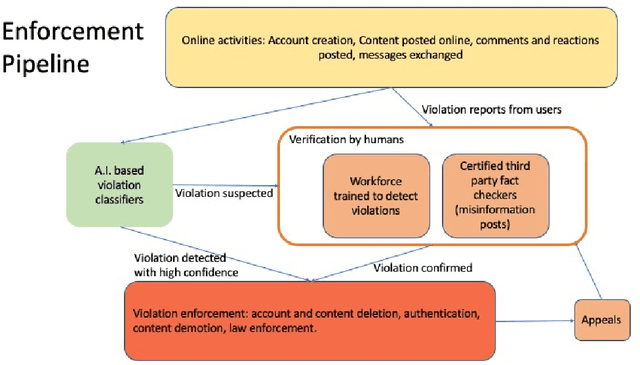
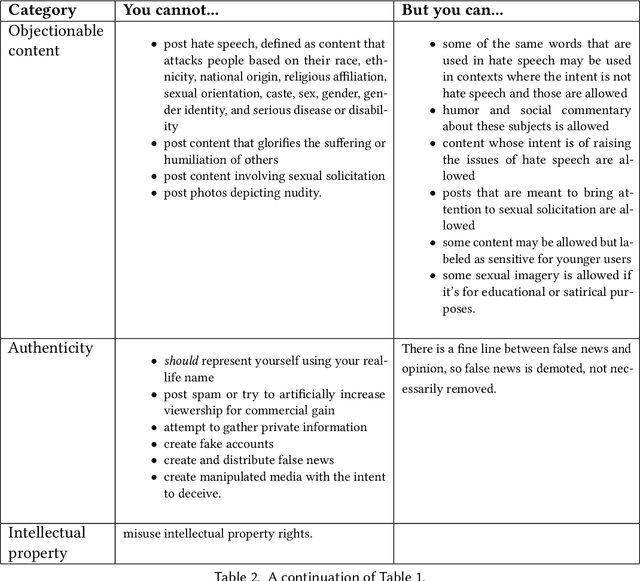
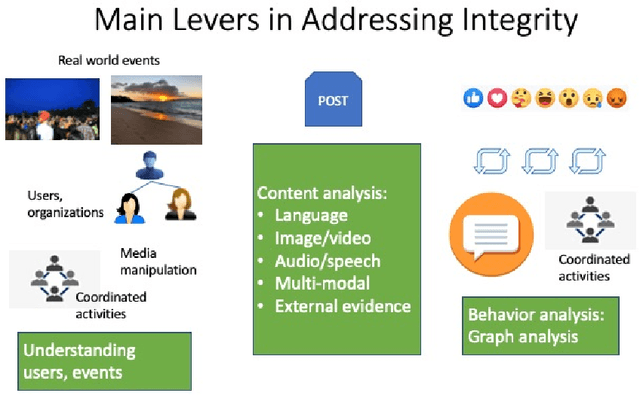
Online social networks provide a platform for sharing information and free expression. However, these networks are also used for malicious purposes, such as distributing misinformation and hate speech, selling illegal drugs, and coordinating sex trafficking or child exploitation. This paper surveys the state of the art in keeping online platforms and their users safe from such harm, also known as the problem of preserving integrity. This survey comes from the perspective of having to combat a broad spectrum of integrity violations at Facebook. We highlight the techniques that have been proven useful in practice and that deserve additional attention from the academic community. Instead of discussing the many individual violation types, we identify key aspects of the social-media eco-system, each of which is common to a wide variety violation types. Furthermore, each of these components represents an area for research and development, and the innovations that are found can be applied widely.
Happiness Entailment: Automating Suggestions for Well-Being
Jul 23, 2019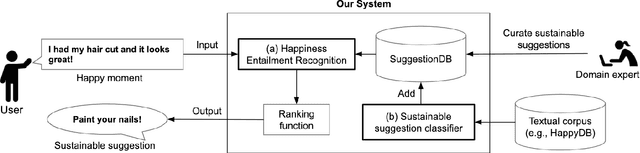

Understanding what makes people happy is a central topic in psychology. Prior work has mostly focused on developing self-reporting assessment tools for individuals and relies on experts to analyze the periodic reported assessments. One of the goals of the analysis is to understand what actions are necessary to encourage modifications in the behaviors of the individuals to improve their overall well-being. In this paper, we outline a complementary approach; on the assumption that the user journals her happy moments as short texts, a system can analyze these texts and propose sustainable suggestions for the user that may lead to an overall improvement in her well-being. We prototype one necessary component of such a system, the Happiness Entailment Recognition (HER) module, which takes as input a short text describing an event, a candidate suggestion, and outputs a determination about whether the suggestion is more likely to be good for this user based on the event described. This component is implemented as a neural network model with two encoders, one for the user input and one for the candidate actionable suggestion, with additional layers to capture psychologically significant features in the happy moment and suggestion.
Open Information Extraction from Question-Answer Pairs
Apr 06, 2019



Open Information Extraction (OpenIE) extracts meaningful structured tuples from free-form text. Most previous work on OpenIE considers extracting data from one sentence at a time. We describe NeurON, a system for extracting tuples from question-answer pairs. Since real questions and answers often contain precisely the information that users care about, such information is particularly desirable to extend a knowledge base with. NeurON addresses several challenges. First, an answer text is often hard to understand without knowing the question, and second, relevant information can span multiple sentences. To address these, NeurON formulates extraction as a multi-source sequence-to-sequence learning task, wherein it combines distributed representations of a question and an answer to generate knowledge facts. We describe experiments on two real-world datasets that demonstrate that NeurON can find a significant number of new and interesting facts to extend a knowledge base compared to state-of-the-art OpenIE methods.
Voyageur: An Experiential Travel Search Engine
Mar 04, 2019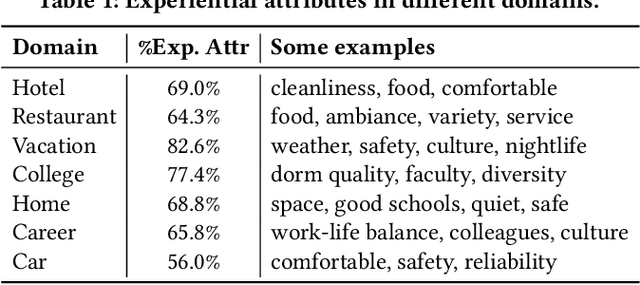
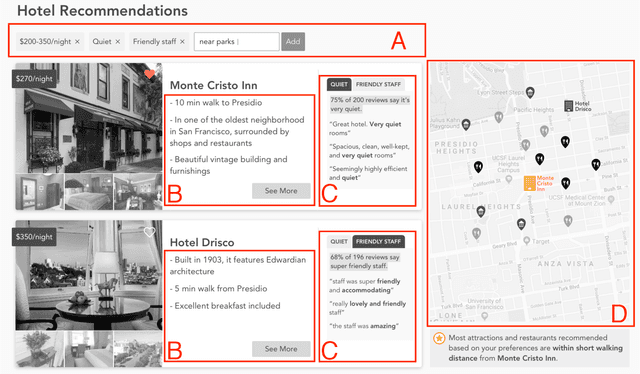
We describe Voyageur, which is an application of experiential search to the domain of travel. Unlike traditional search engines for online services, experiential search focuses on the experiential aspects of the service under consideration. In particular, Voyageur needs to handle queries for subjective aspects of the service (e.g., quiet hotel, friendly staff) and combine these with objective attributes, such as price and location. Voyageur also highlights interesting facts and tips about the services the user is considering to provide them with further insights into their choices.
Scalable Semantic Querying of Text
May 03, 2018
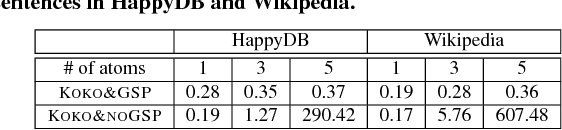
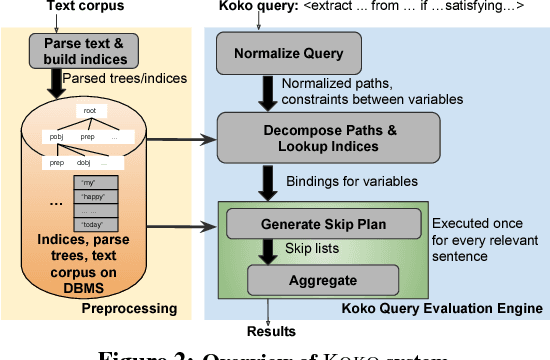
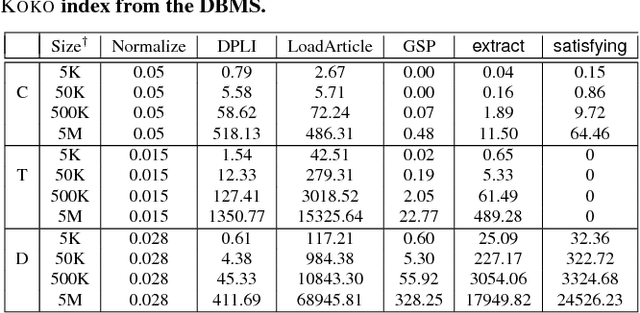
We present the KOKO system that takes declarative information extraction to a new level by incorporating advances in natural language processing techniques in its extraction language. KOKO is novel in that its extraction language simultaneously supports conditions on the surface of the text and on the structure of the dependency parse tree of sentences, thereby allowing for more refined extractions. KOKO also supports conditions that are forgiving to linguistic variation of expressing concepts and allows to aggregate evidence from the entire document in order to filter extractions. To scale up, KOKO exploits a multi-indexing scheme and heuristics for efficient extractions. We extensively evaluate KOKO over publicly available text corpora. We show that KOKO indices take up the smallest amount of space, are notably faster and more effective than a number of prior indexing schemes. Finally, we demonstrate KOKO's scale up on a corpus of 5 million Wikipedia articles.
HappyDB: A Corpus of 100,000 Crowdsourced Happy Moments
Jan 25, 2018
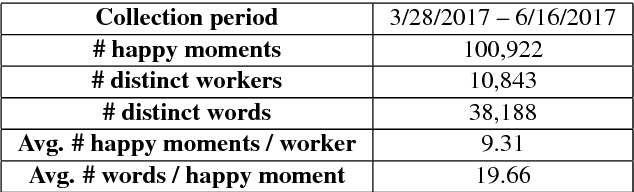
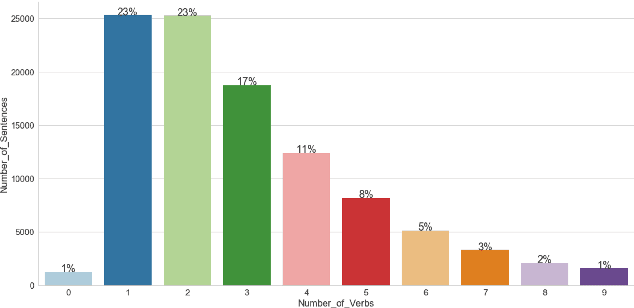
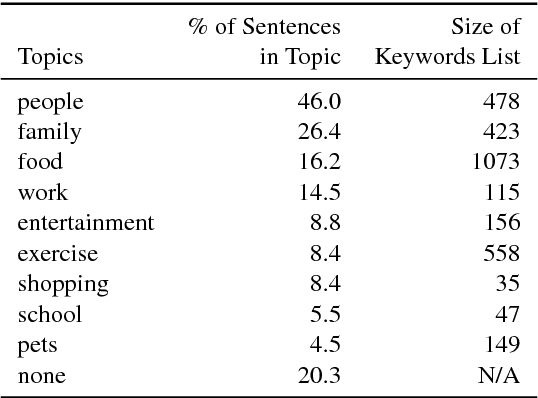
The science of happiness is an area of positive psychology concerned with understanding what behaviors make people happy in a sustainable fashion. Recently, there has been interest in developing technologies that help incorporate the findings of the science of happiness into users' daily lives by steering them towards behaviors that increase happiness. With the goal of building technology that can understand how people express their happy moments in text, we crowd-sourced HappyDB, a corpus of 100,000 happy moments that we make publicly available. This paper describes HappyDB and its properties, and outlines several important NLP problems that can be studied with the help of the corpus. We also apply several state-of-the-art analysis techniques to analyze HappyDB. Our results demonstrate the need for deeper NLP techniques to be developed which makes HappyDB an exciting resource for follow-on research.