 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMonte-Carlo Tree Search for Multi-Agent Pathfinding: Preliminary Results
Jul 25, 2023In this work we study a well-known and challenging problem of Multi-agent Pathfinding, when a set of agents is confined to a graph, each agent is assigned a unique start and goal vertices and the task is to find a set of collision-free paths (one for each agent) such that each agent reaches its respective goal. We investigate how to utilize Monte-Carlo Tree Search (MCTS) to solve the problem. Although MCTS was shown to demonstrate superior performance in a wide range of problems like playing antagonistic games (e.g. Go, Chess etc.), discovering faster matrix multiplication algorithms etc., its application to the problem at hand was not well studied before. To this end we introduce an original variant of MCTS, tailored to multi-agent pathfinding. The crux of our approach is how the reward, that guides MCTS, is computed. Specifically, we use individual paths to assist the agents with the the goal-reaching behavior, while leaving them freedom to get off the track if it is needed to avoid collisions. We also use a dedicated decomposition technique to reduce the branching factor of the tree search procedure. Empirically we show that the suggested method outperforms the baseline planning algorithm that invokes heuristic search, e.g. A*, at each re-planning step.
Reinforcement Learning with Success Induced Task Prioritization
Dec 30, 2022Many challenging reinforcement learning (RL) problems require designing a distribution of tasks that can be applied to train effective policies. This distribution of tasks can be specified by the curriculum. A curriculum is meant to improve the results of learning and accelerate it. We introduce Success Induced Task Prioritization (SITP), a framework for automatic curriculum learning, where a task sequence is created based on the success rate of each task. In this setting, each task is an algorithmically created environment instance with a unique configuration. The algorithm selects the order of tasks that provide the fastest learning for agents. The probability of selecting any of the tasks for the next stage of learning is determined by evaluating its performance score in previous stages. Experiments were carried out in the Partially Observable Grid Environment for Multiple Agents (POGEMA) and Procgen benchmark. We demonstrate that SITP matches or surpasses the results of other curriculum design methods. Our method can be implemented with handful of minor modifications to any standard RL framework and provides useful prioritization with minimal computational overhead.
Collecting Interactive Multi-modal Datasets for Grounded Language Understanding
Nov 18, 2022


Human intelligence can remarkably adapt quickly to new tasks and environments. Starting from a very young age, humans acquire new skills and learn how to solve new tasks either by imitating the behavior of others or by following provided natural language instructions. To facilitate research which can enable similar capabilities in machines, we made the following contributions (1) formalized the collaborative embodied agent using natural language task; (2) developed a tool for extensive and scalable data collection; and (3) collected the first dataset for interactive grounded language understanding.
Learning to Solve Voxel Building Embodied Tasks from Pixels and Natural Language Instructions
Nov 01, 2022The adoption of pre-trained language models to generate action plans for embodied agents is a promising research strategy. However, execution of instructions in real or simulated environments requires verification of the feasibility of actions as well as their relevance to the completion of a goal. We propose a new method that combines a language model and reinforcement learning for the task of building objects in a Minecraft-like environment according to the natural language instructions. Our method first generates a set of consistently achievable sub-goals from the instructions and then completes associated sub-tasks with a pre-trained RL policy. The proposed method formed the RL baseline at the IGLU 2022 competition.
POGEMA: Partially Observable Grid Environment for Multiple Agents
Jun 22, 2022
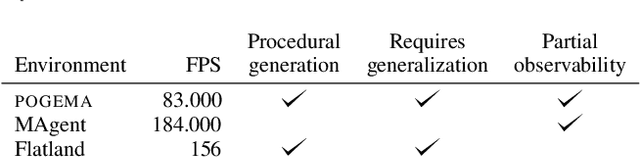
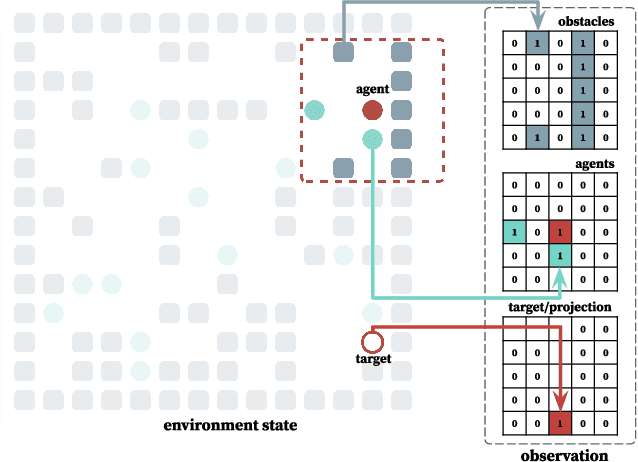
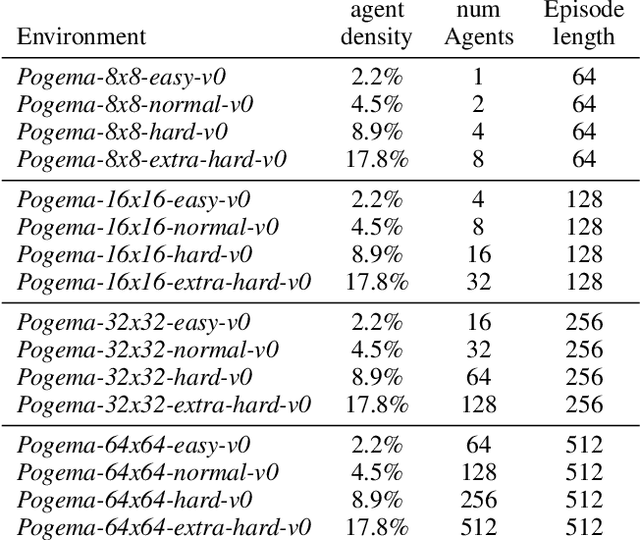
We introduce POGEMA (https://github.com/AIRI-Institute/pogema) a sandbox for challenging partially observable multi-agent pathfinding (PO-MAPF) problems . This is a grid-based environment that was specifically designed to be a flexible, tunable and scalable benchmark. It can be tailored to a variety of PO-MAPF, which can serve as an excellent testing ground for planning and learning methods, and their combination, which will allow us to move towards filling the gap between AI planning and learning.
IGLU Gridworld: Simple and Fast Environment for Embodied Dialog Agents
May 31, 2022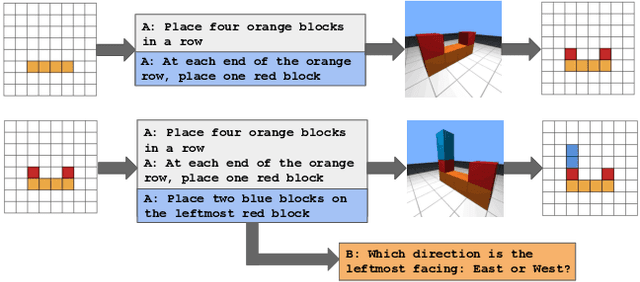
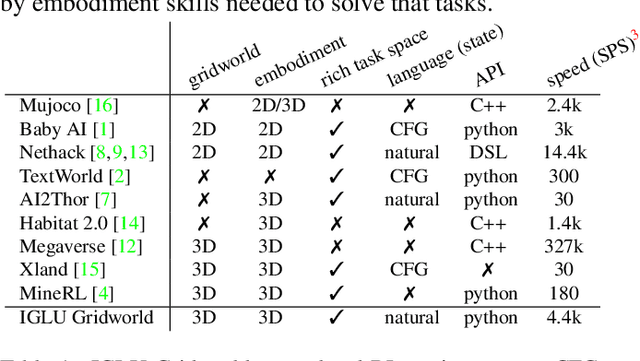
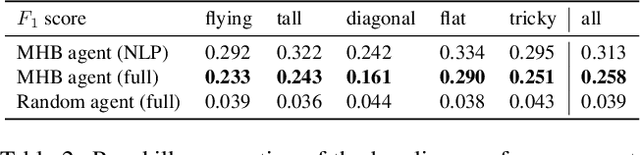
We present the IGLU Gridworld: a reinforcement learning environment for building and evaluating language conditioned embodied agents in a scalable way. The environment features visual agent embodiment, interactive learning through collaboration, language conditioned RL, and combinatorically hard task (3d blocks building) space.
IGLU 2022: Interactive Grounded Language Understanding in a Collaborative Environment at NeurIPS 2022
May 27, 2022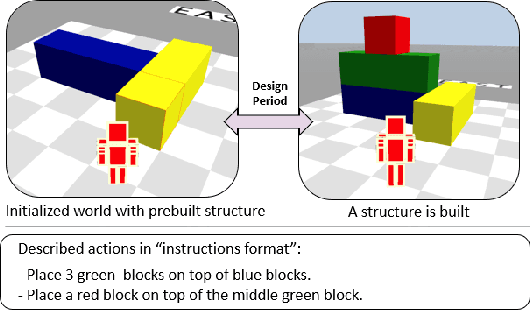

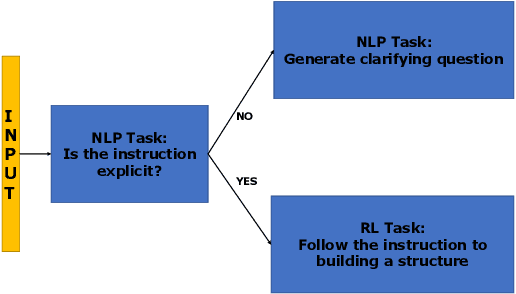
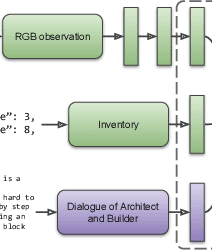
Human intelligence has the remarkable ability to adapt to new tasks and environments quickly. Starting from a very young age, humans acquire new skills and learn how to solve new tasks either by imitating the behavior of others or by following provided natural language instructions. To facilitate research in this direction, we propose IGLU: Interactive Grounded Language Understanding in a Collaborative Environment. The primary goal of the competition is to approach the problem of how to develop interactive embodied agents that learn to solve a task while provided with grounded natural language instructions in a collaborative environment. Understanding the complexity of the challenge, we split it into sub-tasks to make it feasible for participants. This research challenge is naturally related, but not limited, to two fields of study that are highly relevant to the NeurIPS community: Natural Language Understanding and Generation (NLU/G) and Reinforcement Learning (RL). Therefore, the suggested challenge can bring two communities together to approach one of the crucial challenges in AI. Another critical aspect of the challenge is the dedication to perform a human-in-the-loop evaluation as a final evaluation for the agents developed by contestants.
Interactive Grounded Language Understanding in a Collaborative Environment: IGLU 2021
May 05, 2022
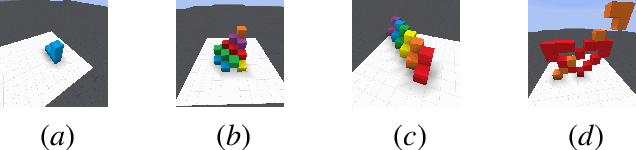
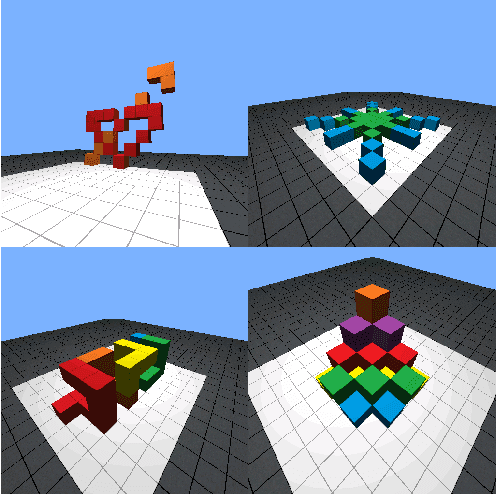
Human intelligence has the remarkable ability to quickly adapt to new tasks and environments. Starting from a very young age, humans acquire new skills and learn how to solve new tasks either by imitating the behavior of others or by following provided natural language instructions. To facilitate research in this direction, we propose \emph{IGLU: Interactive Grounded Language Understanding in a Collaborative Environment}. The primary goal of the competition is to approach the problem of how to build interactive agents that learn to solve a task while provided with grounded natural language instructions in a collaborative environment. Understanding the complexity of the challenge, we split it into sub-tasks to make it feasible for participants.
* arXiv admin note: substantial text overlap with arXiv:2110.06536
NeurIPS 2021 Competition IGLU: Interactive Grounded Language Understanding in a Collaborative Environment
Oct 15, 2021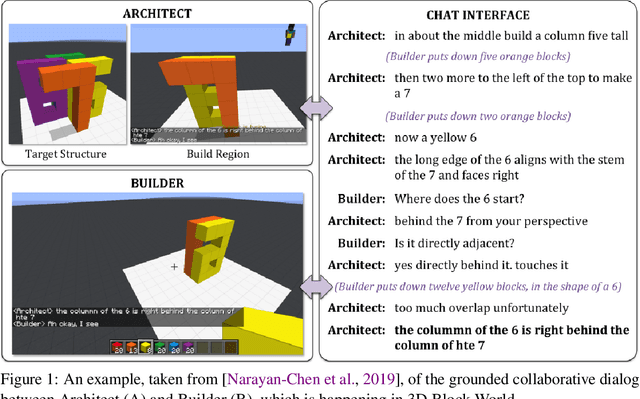

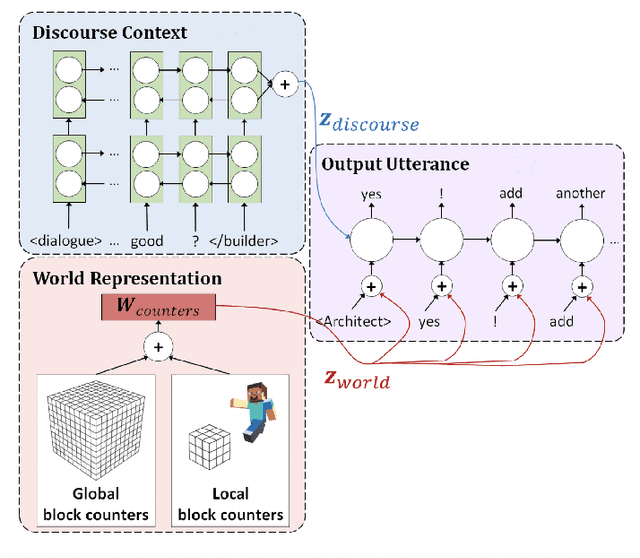
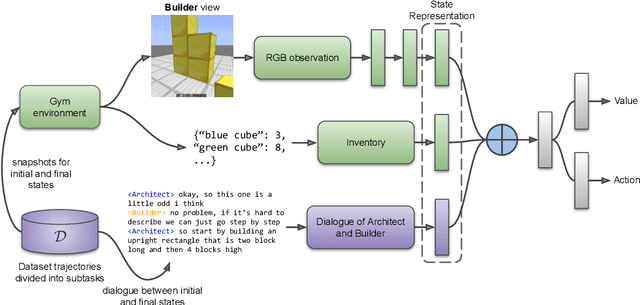
Human intelligence has the remarkable ability to adapt to new tasks and environments quickly. Starting from a very young age, humans acquire new skills and learn how to solve new tasks either by imitating the behavior of others or by following provided natural language instructions. To facilitate research in this direction, we propose IGLU: Interactive Grounded Language Understanding in a Collaborative Environment. The primary goal of the competition is to approach the problem of how to build interactive agents that learn to solve a task while provided with grounded natural language instructions in a collaborative environment. Understanding the complexity of the challenge, we split it into sub-tasks to make it feasible for participants. This research challenge is naturally related, but not limited, to two fields of study that are highly relevant to the NeurIPS community: Natural Language Understanding and Generation (NLU/G) and Reinforcement Learning (RL). Therefore, the suggested challenge can bring two communities together to approach one of the important challenges in AI. Another important aspect of the challenge is the dedication to perform a human-in-the-loop evaluation as a final evaluation for the agents developed by contestants.
Long-Term Exploration in Persistent MDPs
Sep 21, 2021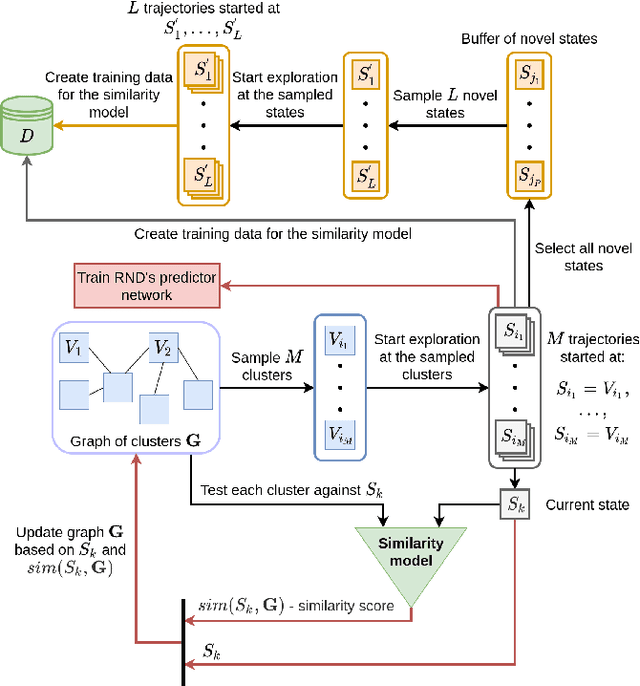
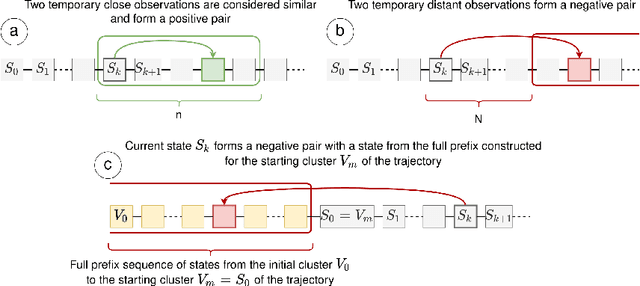
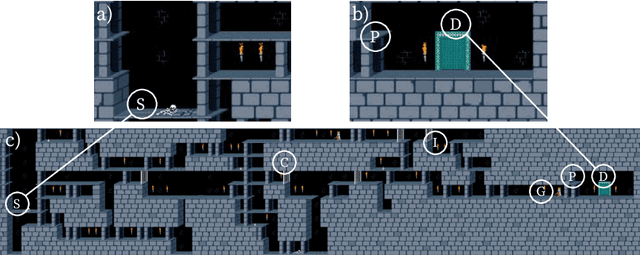

Exploration is an essential part of reinforcement learning, which restricts the quality of learned policy. Hard-exploration environments are defined by huge state space and sparse rewards. In such conditions, an exhaustive exploration of the environment is often impossible, and the successful training of an agent requires a lot of interaction steps. In this paper, we propose an exploration method called Rollback-Explore (RbExplore), which utilizes the concept of the persistent Markov decision process, in which agents during training can roll back to visited states. We test our algorithm in the hard-exploration Prince of Persia game, without rewards and domain knowledge. At all used levels of the game, our agent outperforms or shows comparable results with state-of-the-art curiosity methods with knowledge-based intrinsic motivation: ICM and RND. An implementation of RbExplore can be found at https://github.com/cds-mipt/RbExplore.