 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Correspondence from the Cycle-Consistency of Time
Apr 02, 2019
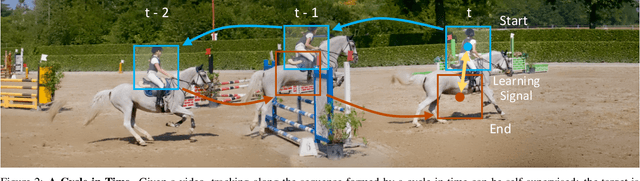
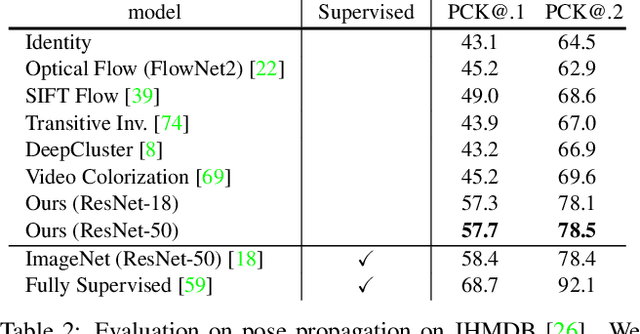
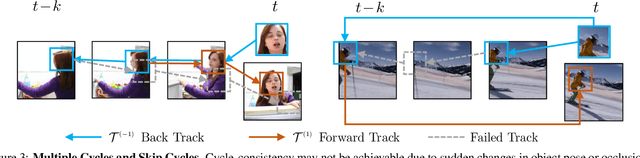
We introduce a self-supervised method for learning visual correspondence from unlabeled video. The main idea is to use cycle-consistency in time as free supervisory signal for learning visual representations from scratch. At training time, our model learns a feature map representation to be useful for performing cycle-consistent tracking. At test time, we use the acquired representation to find nearest neighbors across space and time. We demonstrate the generalizability of the representation -- without finetuning -- across a range of visual correspondence tasks, including video object segmentation, keypoint tracking, and optical flow. Our approach outperforms previous self-supervised methods and performs competitively with strongly supervised methods.
Discovering Visual Patterns in Art Collections with Spatially-consistent Feature Learning
Mar 08, 2019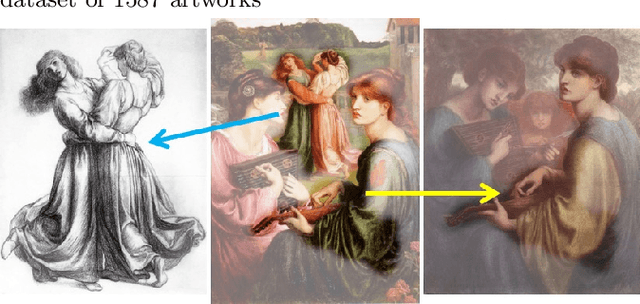
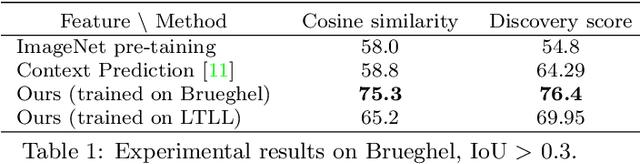
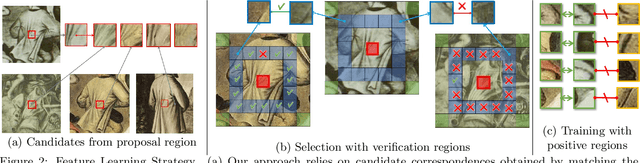
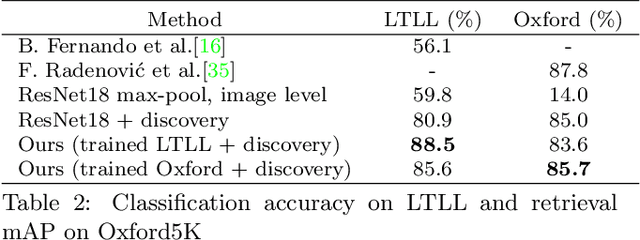
Our goal in this paper is to discover near duplicate patterns in large collections of artworks. This is harder than standard instance mining due to differences in the artistic media (oil, pastel, drawing, etc), and imperfections inherent in the copying process. The key technical insight is to adapt a standard deep feature to this task by fine-tuning it on the specific art collection using self-supervised learning. More specifically, spatial consistency between neighbouring feature matches is used as supervisory fine-tuning signal. The adapted feature leads to more accurate style-invariant matching, and can be used with a standard discovery approach, based on geometric verification, to identify duplicate patterns in the dataset. The approach is evaluated on several different datasets and shows surprisingly good qualitative discovery results. For quantitative evaluation of the method, we annotated 273 near duplicate details in a dataset of 1587 artworks attributed to Jan Brueghel and his workshop. Beyond artwork, we also demonstrate improvement on localization on the Oxford5K photo dataset as well as on historical photograph localization on the Large Time Lags Location (LTLL) dataset.
Learning to Control Self-Assembling Morphologies: A Study of Generalization via Modularity
Feb 14, 2019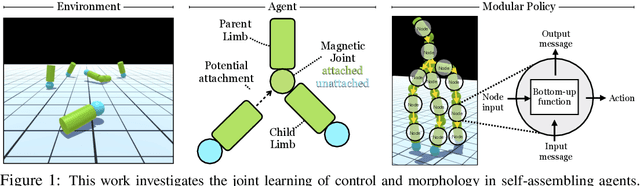
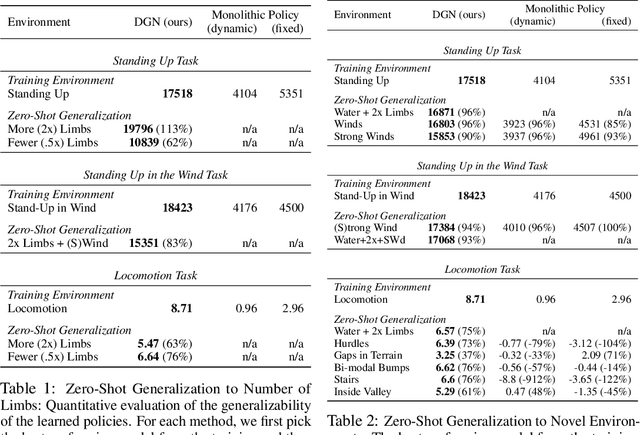
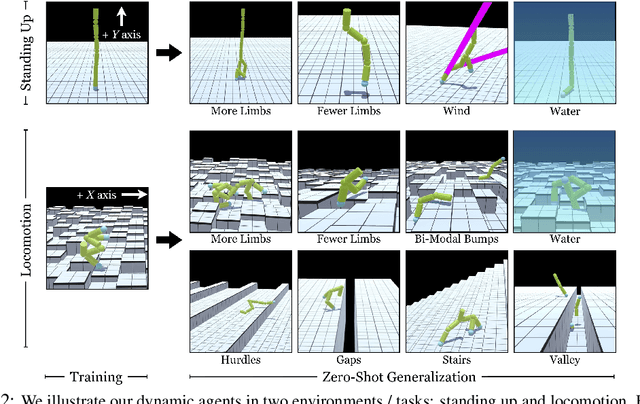

Contemporary sensorimotor learning approaches typically start with an existing complex agent (e.g., a robotic arm), which they learn to control. In contrast, this paper investigates a modular co-evolution strategy: a collection of primitive agents learns to dynamically self-assemble into composite bodies while also learning to coordinate their behavior to control these bodies. Each primitive agent consists of a limb with a motor attached at one end. Limbs may choose to link up to form collectives. When a limb initiates a link-up action and there is another limb nearby, the latter is magnetically connected to the 'parent' limb's motor. This forms a new single agent, which may further link with other agents. In this way, complex morphologies can emerge, controlled by a policy whose architecture is in explicit correspondence with the morphology. We evaluate the performance of these 'dynamic' and 'modular' agents in simulated environments. We demonstrate better generalization to test-time changes both in the environment, as well as in the agent morphology, compared to static and monolithic baselines. Project videos and code are available at https://pathak22.github.io/modular-assemblies/
Dataset Distillation
Nov 27, 2018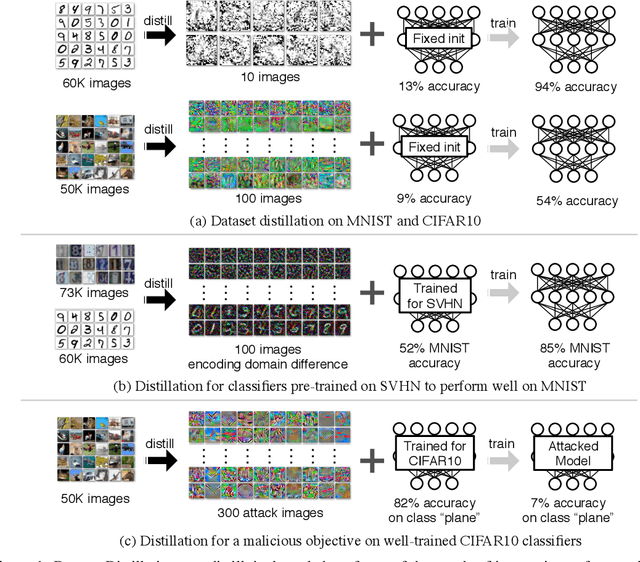

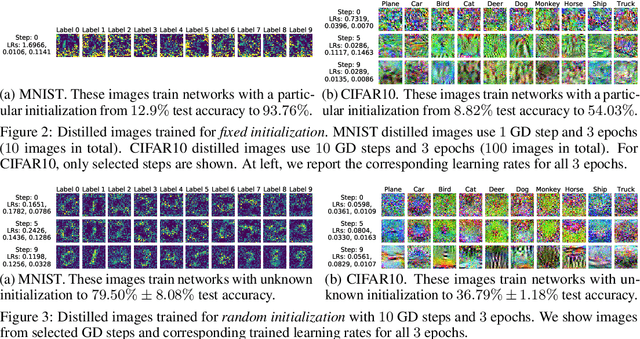

Model distillation aims to distill the knowledge of a complex model into a simpler one. In this paper, we consider an alternative formulation called {\em dataset distillation}: we keep the model fixed and instead attempt to distill the knowledge from a large training dataset into a small one. The idea is to {\em synthesize} a small number of data points that do not need to come from the correct data distribution, but will, when given to the learning algorithm as training data, approximate the model trained on the original data. For example, we show that it is possible to compress $60,000$ MNIST training images into just $10$ synthetic {\em distilled images} (one per class) and achieve close to original performance with only a few steps of gradient descent, given a particular fixed network initialization. We evaluate our method in a wide range of initialization settings and with different learning objectives. Experiments on multiple datasets show the advantage of our approach compared to alternative methods in most settings.
Toward Multimodal Image-to-Image Translation
Oct 24, 2018

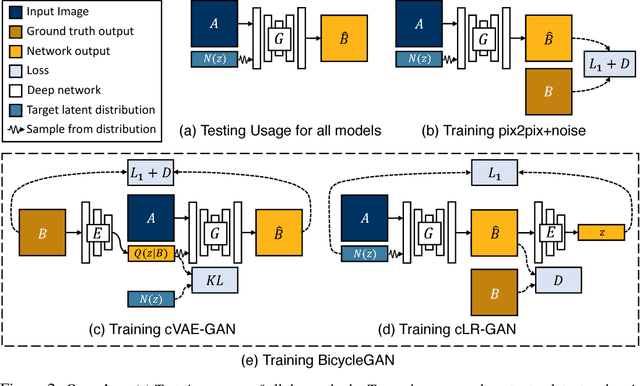
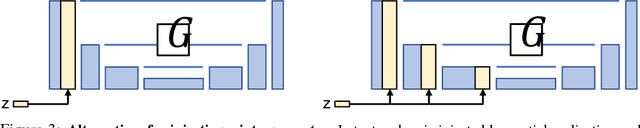
Many image-to-image translation problems are ambiguous, as a single input image may correspond to multiple possible outputs. In this work, we aim to model a \emph{distribution} of possible outputs in a conditional generative modeling setting. The ambiguity of the mapping is distilled in a low-dimensional latent vector, which can be randomly sampled at test time. A generator learns to map the given input, combined with this latent code, to the output. We explicitly encourage the connection between output and the latent code to be invertible. This helps prevent a many-to-one mapping from the latent code to the output during training, also known as the problem of mode collapse, and produces more diverse results. We explore several variants of this approach by employing different training objectives, network architectures, and methods of injecting the latent code. Our proposed method encourages bijective consistency between the latent encoding and output modes. We present a systematic comparison of our method and other variants on both perceptual realism and diversity.
Time-Agnostic Prediction: Predicting Predictable Video Frames
Oct 23, 2018
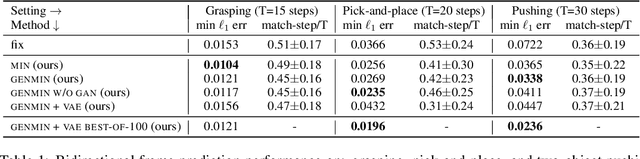

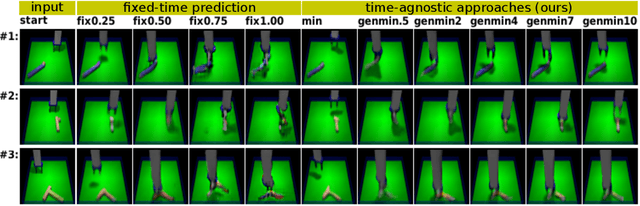
Prediction is arguably one of the most basic functions of an intelligent system. In general, the problem of predicting events in the future or between two waypoints is exceedingly difficult. However, most phenomena naturally pass through relatively predictable bottlenecks---while we cannot predict the precise trajectory of a robot arm between being at rest and holding an object up, we can be certain that it must have picked the object up. To exploit this, we decouple visual prediction from a rigid notion of time. While conventional approaches predict frames at regularly spaced temporal intervals, our time-agnostic predictors (TAP) are not tied to specific times so that they may instead discover predictable "bottleneck" frames no matter when they occur. We evaluate our approach for future and intermediate frame prediction across three robotic manipulation tasks. Our predictions are not only of higher visual quality, but also correspond to coherent semantic subgoals in temporally extended tasks.
Audio-Visual Scene Analysis with Self-Supervised Multisensory Features
Oct 09, 2018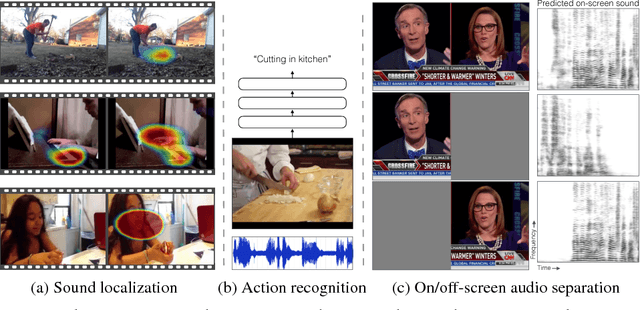

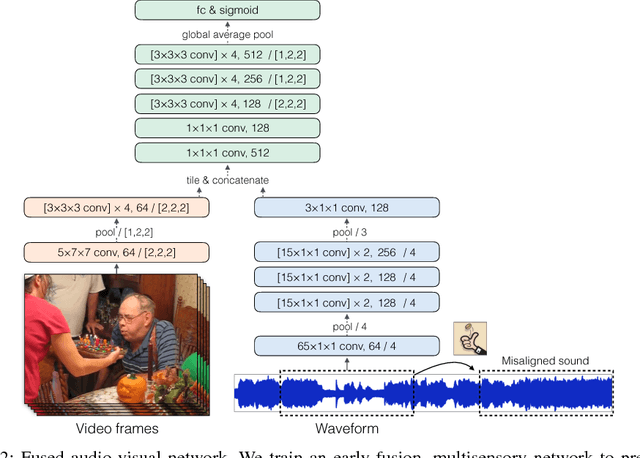
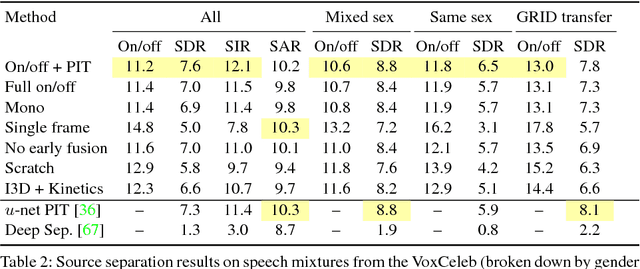
The thud of a bouncing ball, the onset of speech as lips open -- when visual and audio events occur together, it suggests that there might be a common, underlying event that produced both signals. In this paper, we argue that the visual and audio components of a video signal should be modeled jointly using a fused multisensory representation. We propose to learn such a representation in a self-supervised way, by training a neural network to predict whether video frames and audio are temporally aligned. We use this learned representation for three applications: (a) sound source localization, i.e. visualizing the source of sound in a video; (b) audio-visual action recognition; and (c) on/off-screen audio source separation, e.g. removing the off-screen translator's voice from a foreign official's speech. Code, models, and video results are available on our webpage: http://andrewowens.com/multisensory
Fighting Fake News: Image Splice Detection via Learned Self-Consistency
Sep 05, 2018
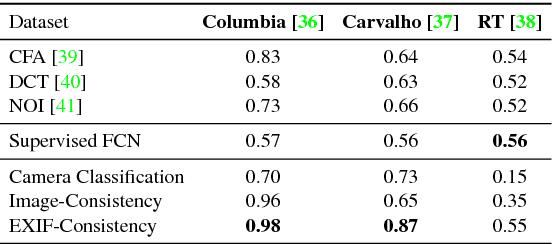

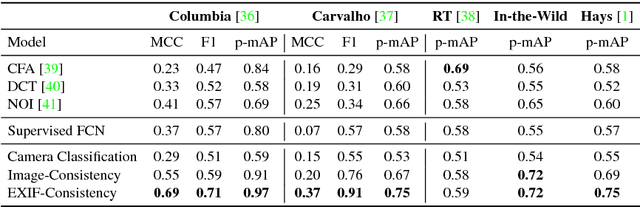
Advances in photo editing and manipulation tools have made it significantly easier to create fake imagery. Learning to detect such manipulations, however, remains a challenging problem due to the lack of sufficient amounts of manipulated training data. In this paper, we propose a learning algorithm for detecting visual image manipulations that is trained only using a large dataset of real photographs. The algorithm uses the automatically recorded photo EXIF metadata as supervisory signal for training a model to determine whether an image is self-consistent -- that is, whether its content could have been produced by a single imaging pipeline. We apply this self-consistency model to the task of detecting and localizing image splices. The proposed method obtains state-of-the-art performance on several image forensics benchmarks, despite never seeing any manipulated images at training. That said, it is merely a step in the long quest for a truly general purpose visual forensics tool.
Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks
Aug 30, 2018
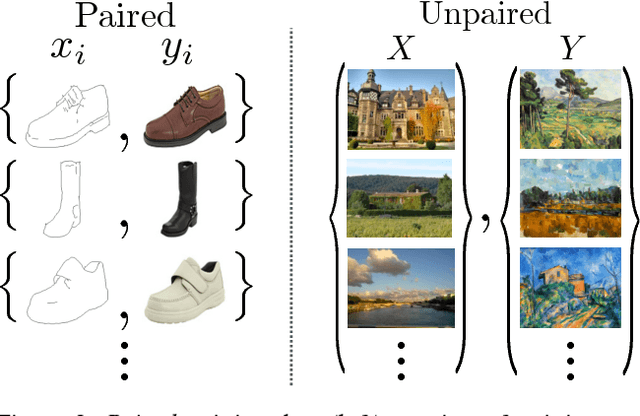
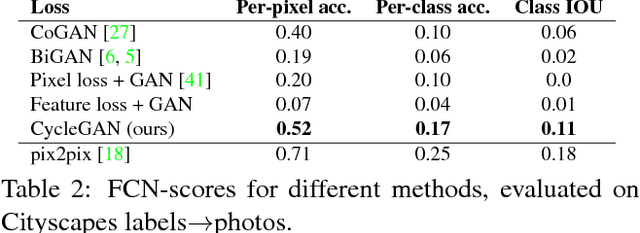
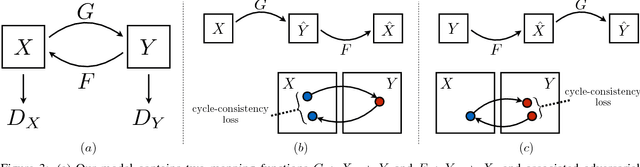
Image-to-image translation is a class of vision and graphics problems where the goal is to learn the mapping between an input image and an output image using a training set of aligned image pairs. However, for many tasks, paired training data will not be available. We present an approach for learning to translate an image from a source domain $X$ to a target domain $Y$ in the absence of paired examples. Our goal is to learn a mapping $G: X \rightarrow Y$ such that the distribution of images from $G(X)$ is indistinguishable from the distribution $Y$ using an adversarial loss. Because this mapping is highly under-constrained, we couple it with an inverse mapping $F: Y \rightarrow X$ and introduce a cycle consistency loss to push $F(G(X)) \approx X$ (and vice versa). Qualitative results are presented on several tasks where paired training data does not exist, including collection style transfer, object transfiguration, season transfer, photo enhancement, etc. Quantitative comparisons against several prior methods demonstrate the superiority of our approach.
Everybody Dance Now
Aug 22, 2018


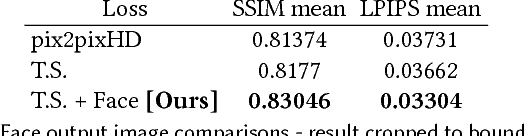
This paper presents a simple method for "do as I do" motion transfer: given a source video of a person dancing we can transfer that performance to a novel (amateur) target after only a few minutes of the target subject performing standard moves. We pose this problem as a per-frame image-to-image translation with spatio-temporal smoothing. Using pose detections as an intermediate representation between source and target, we learn a mapping from pose images to a target subject's appearance. We adapt this setup for temporally coherent video generation including realistic face synthesis. Our video demo can be found at https://youtu.be/PCBTZh41Ris .