 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultimodal Adaptive Fusion of Face and Gait Features using Keyless attention based Deep Neural Networks for Human Identification
Mar 24, 2023



Biometrics plays a significant role in vision-based surveillance applications. Soft biometrics such as gait is widely used with face in surveillance tasks like person recognition and re-identification. Nevertheless, in practical scenarios, classical fusion techniques respond poorly to changes in individual users and in the external environment. To this end, we propose a novel adaptive multi-biometric fusion strategy for the dynamic incorporation of gait and face biometric cues by leveraging keyless attention deep neural networks. Various external factors such as viewpoint and distance to the camera, are investigated in this study. Extensive experiments have shown superior performanceof the proposed model compared with the state-of-the-art model.
3DSGrasp: 3D Shape-Completion for Robotic Grasp
Jan 02, 2023



Real-world robotic grasping can be done robustly if a complete 3D Point Cloud Data (PCD) of an object is available. However, in practice, PCDs are often incomplete when objects are viewed from few and sparse viewpoints before the grasping action, leading to the generation of wrong or inaccurate grasp poses. We propose a novel grasping strategy, named 3DSGrasp, that predicts the missing geometry from the partial PCD to produce reliable grasp poses. Our proposed PCD completion network is a Transformer-based encoder-decoder network with an Offset-Attention layer. Our network is inherently invariant to the object pose and point's permutation, which generates PCDs that are geometrically consistent and completed properly. Experiments on a wide range of partial PCD show that 3DSGrasp outperforms the best state-of-the-art method on PCD completion tasks and largely improves the grasping success rate in real-world scenarios. The code and dataset will be made available upon acceptance.
1st Workshop on Maritime Computer Vision 2023: Challenge Results
Nov 28, 2022



The 1$^{\text{st}}$ Workshop on Maritime Computer Vision (MaCVi) 2023 focused on maritime computer vision for Unmanned Aerial Vehicles (UAV) and Unmanned Surface Vehicle (USV), and organized several subchallenges in this domain: (i) UAV-based Maritime Object Detection, (ii) UAV-based Maritime Object Tracking, (iii) USV-based Maritime Obstacle Segmentation and (iv) USV-based Maritime Obstacle Detection. The subchallenges were based on the SeaDronesSee and MODS benchmarks. This report summarizes the main findings of the individual subchallenges and introduces a new benchmark, called SeaDronesSee Object Detection v2, which extends the previous benchmark by including more classes and footage. We provide statistical and qualitative analyses, and assess trends in the best-performing methodologies of over 130 submissions. The methods are summarized in the appendix. The datasets, evaluation code and the leaderboard are publicly available at https://seadronessee.cs.uni-tuebingen.de/macvi.
Active Gaze Control for Foveal Scene Exploration
Aug 24, 2022
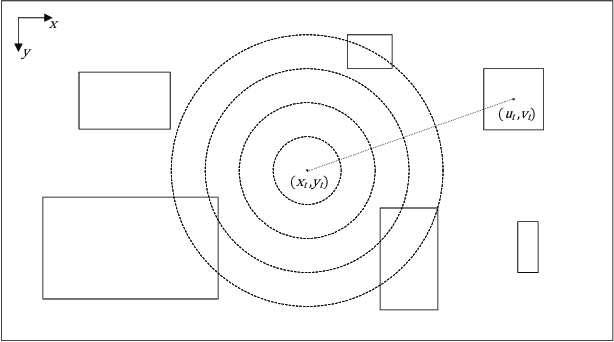
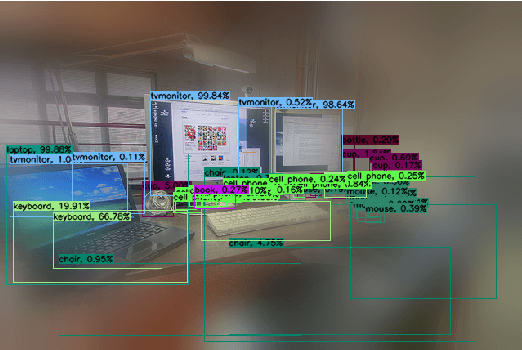

Active perception and foveal vision are the foundations of the human visual system. While foveal vision reduces the amount of information to process during a gaze fixation, active perception will change the gaze direction to the most promising parts of the visual field. We propose a methodology to emulate how humans and robots with foveal cameras would explore a scene, identifying the objects present in their surroundings with in least number of gaze shifts. Our approach is based on three key methods. First, we take an off-the-shelf deep object detector, pre-trained on a large dataset of regular images, and calibrate the classification outputs to the case of foveated images. Second, a body-centered semantic map, encoding the objects classifications and corresponding uncertainties, is sequentially updated with the calibrated detections, considering several data fusion techniques. Third, the next best gaze fixation point is determined based on information-theoretic metrics that aim at minimizing the overall expected uncertainty of the semantic map. When compared to the random selection of next gaze shifts, the proposed method achieves an increase in detection F1-score of 2-3 percentage points for the same number of gaze shifts and reduces to one third the number of required gaze shifts to attain similar performance.
Strategies for modelling open-loop saccade control of a cable-driven biomimetic robot eye
Mar 01, 2022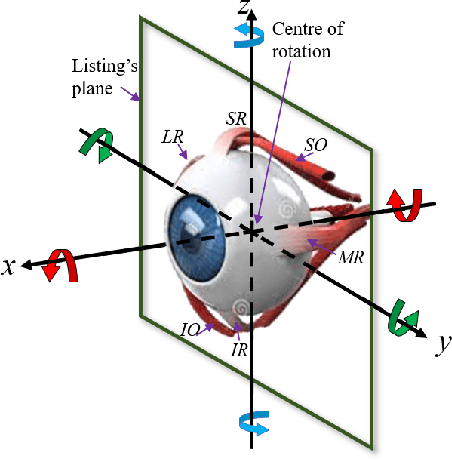
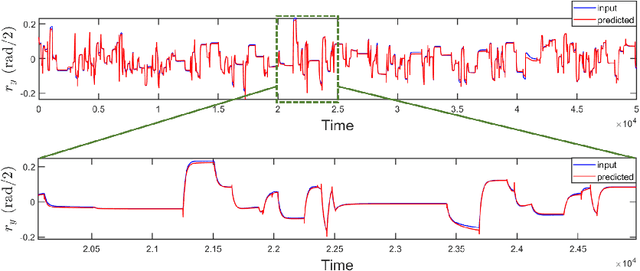

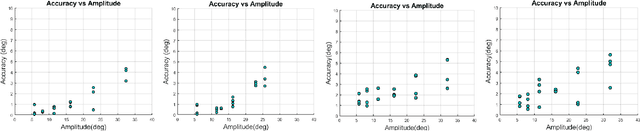
In human-robot interactions, eye movements play an important role in non-verbal communication. However, controlling the motions of a robotic eye that display similar performance as the human oculomotor system is still a major challenge. In this paper, we study how to control a realistic model of the human eye, with a cable-driven actuation system that mimicks the 6 extra-ocular muscles. We have built a robotic prototype and developed a non-linear simulation model, for which we compared different techniques to control its gaze behavior to match the main characteristics of saccade eye movements. In the first approach, we linearized the six degrees of freedom nonlinear model, using a local derivative technique, and designed linear-quadratic optimal controllers to optimize a cost function that accounts for accuracy, energy and duration. The second method learns a dynamic neural-network that matches the system dynamics, trained from sample trajectories of the system, and a non-linear trajectory optimization solver optimized a similar cost function. We focused on the generation of rapid saccadic eye movements with fully unconstrained kinematics, and the generation of control signals for the six cables that simultaneously satisfied several dynamic optimization criteria. The model faithfully mimicked the three-dimensional rotational kinematics and dynamics observed for human saccades. Our experimental results indicate that while the linear model provides a more accurate eye movement, the nonlinear model simulate eye dynamic properties in a better way faithful approximation to the properties of the human saccadic system than the linearized model, at the cost of larger training and optimization time.
Weakly-supervised fire segmentation by visualizing intermediate CNN layers
Nov 16, 2021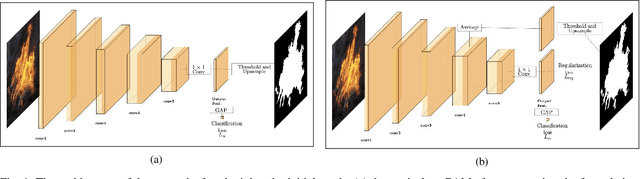
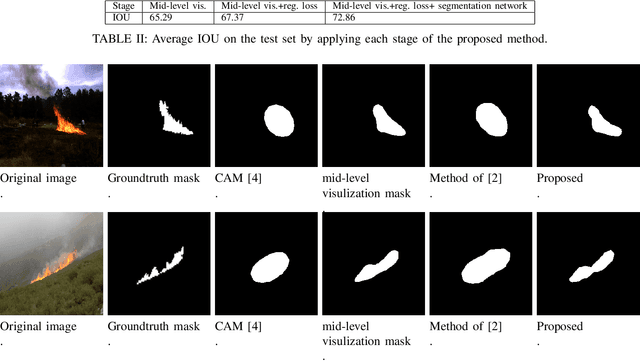
Fire localization in images and videos is an important step for an autonomous system to combat fire incidents. State-of-art image segmentation methods based on deep neural networks require a large number of pixel-annotated samples to train Convolutional Neural Networks (CNNs) in a fully-supervised manner. In this paper, we consider weakly supervised segmentation of fire in images, in which only image labels are used to train the network. We show that in the case of fire segmentation, which is a binary segmentation problem, the mean value of features in a mid-layer of classification CNN can perform better than conventional Class Activation Mapping (CAM) method. We also propose to further improve the segmentation accuracy by adding a rotation equivariant regularization loss on the features of the last convolutional layer. Our results show noticeable improvements over baseline method for weakly-supervised fire segmentation.
Attention on Classification for Fire Segmentation
Nov 04, 2021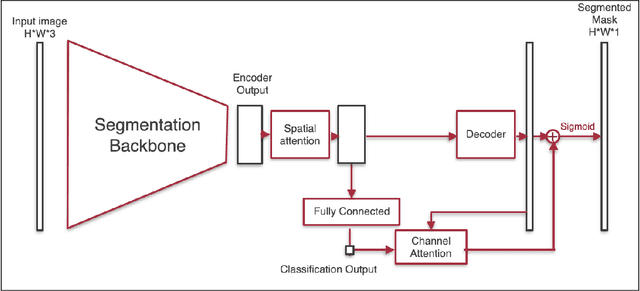
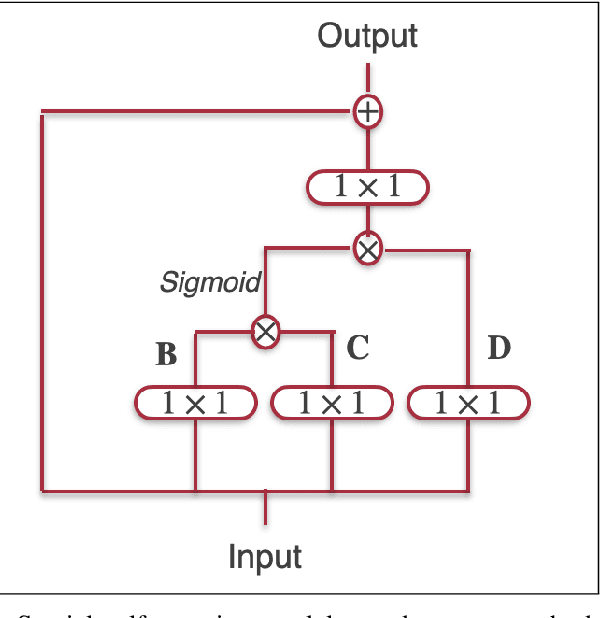


Detection and localization of fire in images and videos are important in tackling fire incidents. Although semantic segmentation methods can be used to indicate the location of pixels with fire in the images, their predictions are localized, and they often fail to consider global information of the existence of fire in the image which is implicit in the image labels. We propose a Convolutional Neural Network (CNN) for joint classification and segmentation of fire in images which improves the performance of the fire segmentation. We use a spatial self-attention mechanism to capture long-range dependency between pixels, and a new channel attention module which uses the classification probability as an attention weight. The network is jointly trained for both segmentation and classification, leading to improvement in the performance of the single-task image segmentation methods, and the previous methods proposed for fire segmentation.
Enabling AI and Robotic Coaches for Physical Rehabilitation Therapy: Iterative Design and Evaluation with Therapists and Post-Stroke Survivors
Jun 15, 2021
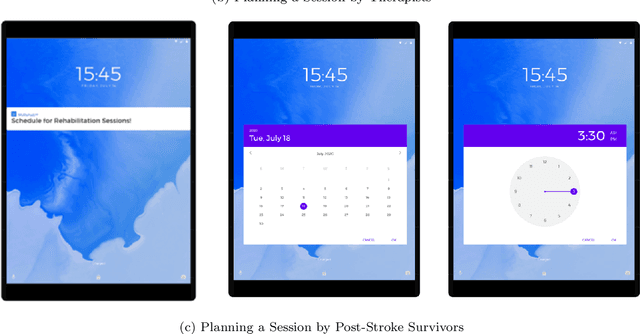

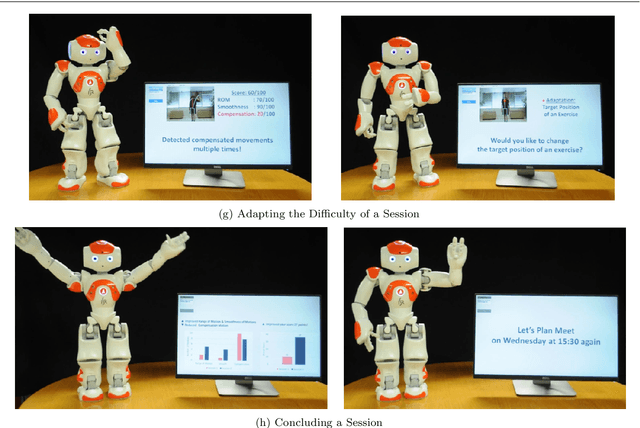
Artificial intelligence (AI) and robotic coaches promise the improved engagement of patients on rehabilitation exercises through social interaction. While previous work explored the potential of automatically monitoring exercises for AI and robotic coaches, the deployment of these systems remains a challenge. Previous work described the lack of involving stakeholders to design such functionalities as one of the major causes. In this paper, we present our efforts on eliciting the detailed design specifications on how AI and robotic coaches could interact with and guide patient's exercises in an effective and acceptable way with four therapists and five post-stroke survivors. Through iterative questionnaires and interviews, we found that both post-stroke survivors and therapists appreciated the potential benefits of AI and robotic coaches to achieve more systematic management and improve their self-efficacy and motivation on rehabilitation therapy. In addition, our evaluation sheds light on several practical concerns (e.g. a possible difficulty with the interaction for people with cognitive impairment, system failures, etc.). We discuss the value of early involvement of stakeholders and interactive techniques that complement system failures, but also support a personalized therapy session for the better deployment of AI and robotic exercise coaches.
One-shot action recognition towards novel assistive therapies
Feb 17, 2021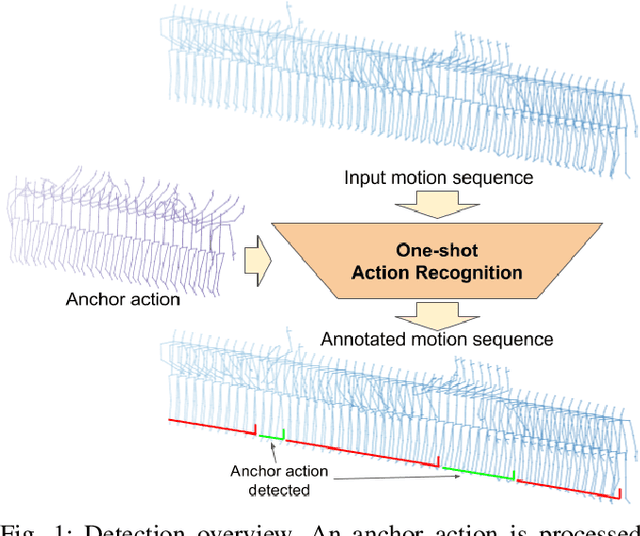
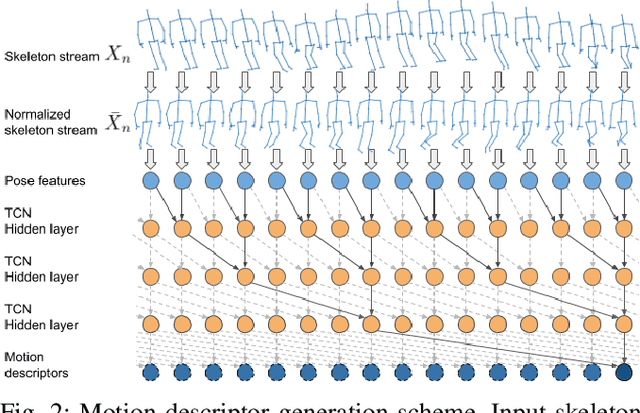
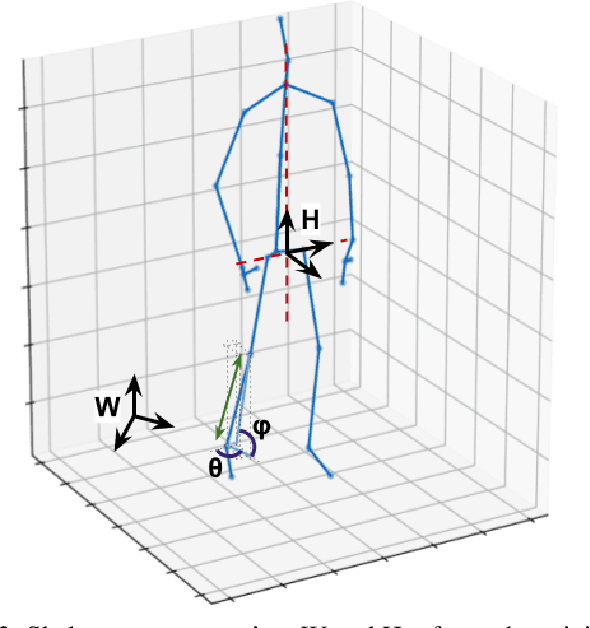

One-shot action recognition is a challenging problem, especially when the target video can contain one, more or none repetitions of the target action. Solutions to this problem can be used in many real world applications that require automated processing of activity videos. In particular, this work is motivated by the automated analysis of medical therapies that involve action imitation games. The presented approach incorporates a pre-processing step that standardizes heterogeneous motion data conditions and generates descriptive movement representations with a Temporal Convolutional Network for a final one-shot (or few-shot) action recognition. Our method achieves state-of-the-art results on the public NTU-120 one-shot action recognition challenge. Besides, we evaluate the approach on a real use-case of automated video analysis for therapy support with autistic people. The promising results prove its suitability for this kind of application in the wild, providing both quantitative and qualitative measures, essential for the patient evaluation and monitoring.
Where is my hand? Deep hand segmentation for visual self-recognition in humanoid robots
Feb 09, 2021
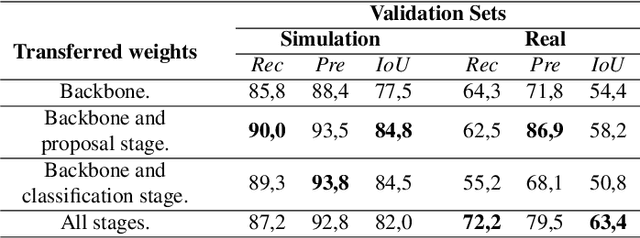
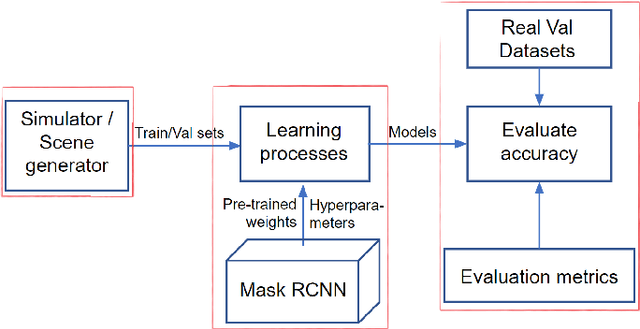
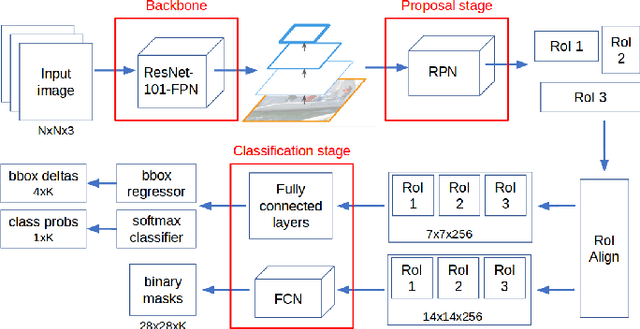
The ability to distinguish between the self and the background is of paramount importance for robotic tasks. The particular case of hands, as the end effectors of a robotic system that more often enter into contact with other elements of the environment, must be perceived and tracked with precision to execute the intended tasks with dexterity and without colliding with obstacles. They are fundamental for several applications, from Human-Robot Interaction tasks to object manipulation. Modern humanoid robots are characterized by high number of degrees of freedom which makes their forward kinematics models very sensitive to uncertainty. Thus, resorting to vision sensing can be the only solution to endow these robots with a good perception of the self, being able to localize their body parts with precision. In this paper, we propose the use of a Convolution Neural Network (CNN) to segment the robot hand from an image in an egocentric view. It is known that CNNs require a huge amount of data to be trained. To overcome the challenge of labeling real-world images, we propose the use of simulated datasets exploiting domain randomization techniques. We fine-tuned the Mask-RCNN network for the specific task of segmenting the hand of the humanoid robot Vizzy. We focus our attention on developing a methodology that requires low amounts of data to achieve reasonable performance while giving detailed insight on how to properly generate variability in the training dataset. Moreover, we analyze the fine-tuning process within the complex model of Mask-RCNN, understanding which weights should be transferred to the new task of segmenting robot hands. Our final model was trained solely on synthetic images and achieves an average IoU of 82% on synthetic validation data and 56.3% on real test data. These results were achieved with only 1000 training images and 3 hours of training time using a single GPU.