 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrompt-Based Multi-Modal Image Segmentation
Dec 18, 2021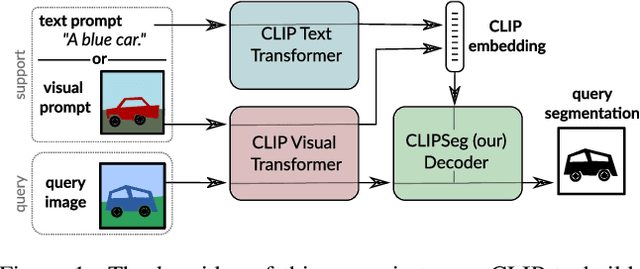

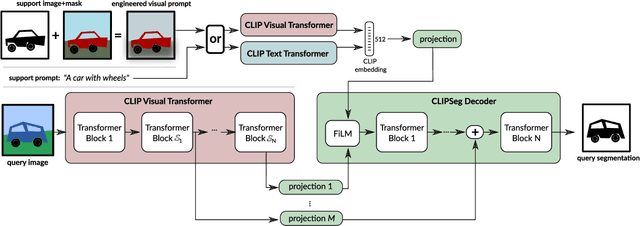

Image segmentation is usually addressed by training a model for a fixed set of object classes. Incorporating additional classes or more complex queries later is expensive as it requires re-training the model on a dataset that encompasses these expressions. Here we propose a system that can generate image segmentations based on arbitrary prompts at test time. A prompt can be either a text or an image. This approach enables us to create a unified model (trained once) for three common segmentation tasks, which come with distinct challenges: referring expression segmentation, zero-shot segmentation and one-shot segmentation. We build upon the CLIP model as a backbone which we extend with a transformer-based decoder that enables dense prediction. After training on an extended version of the PhraseCut dataset, our system generates a binary segmentation map for an image based on a free-text prompt or on an additional image expressing the query. Different variants of the latter image-based prompts are analyzed in detail. This novel hybrid input allows for dynamic adaptation not only to the three segmentation tasks mentioned above, but to any binary segmentation task where a text or image query can be formulated. Finally, we find our system to adapt well to generalized queries involving affordances or properties. Source code: https://eckerlab.org/code/clipseg
Closing the Generalization Gap in One-Shot Object Detection
Nov 09, 2020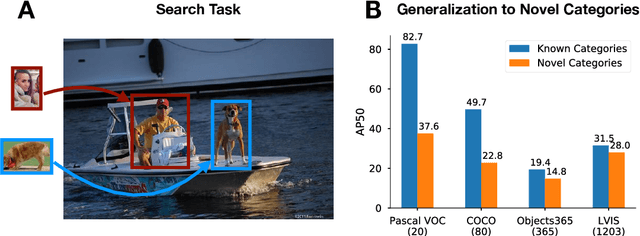
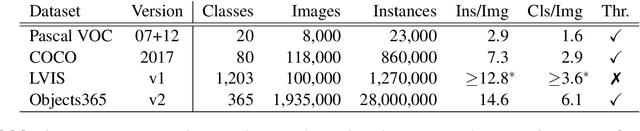

Despite substantial progress in object detection and few-shot learning, detecting objects based on a single example - one-shot object detection - remains a challenge: trained models exhibit a substantial generalization gap, where object categories used during training are detected much more reliably than novel ones. Here we show that this generalization gap can be nearly closed by increasing the number of object categories used during training. Our results show that the models switch from memorizing individual categories to learning object similarity over the category distribution, enabling strong generalization at test time. Importantly, in this regime standard methods to improve object detection models like stronger backbones or longer training schedules also benefit novel categories, which was not the case for smaller datasets like COCO. Our results suggest that the key to strong few-shot detection models may not lie in sophisticated metric learning approaches, but instead in scaling the number of categories. Future data annotation efforts should therefore focus on wider datasets and annotate a larger number of categories rather than gathering more images or instances per category.
Unmasking the Inductive Biases of Unsupervised Object Representations for Video Sequences
Jun 12, 2020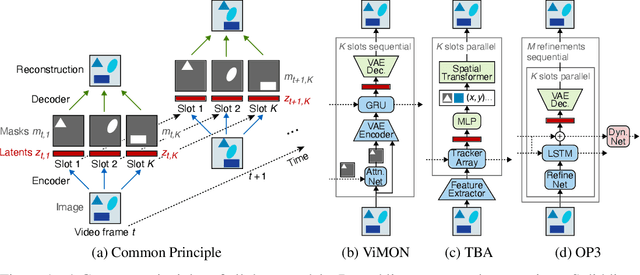
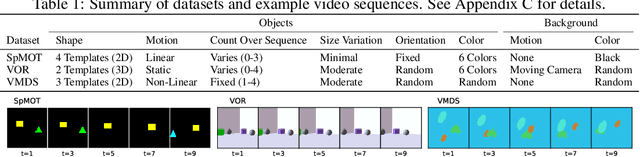
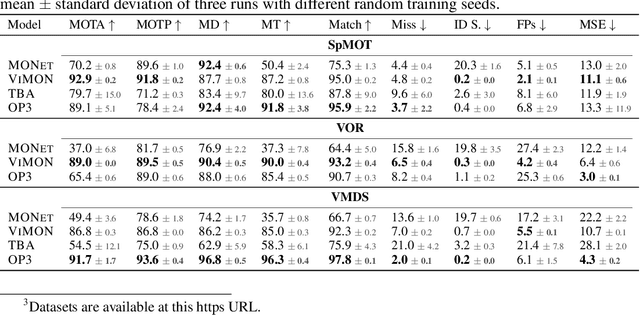
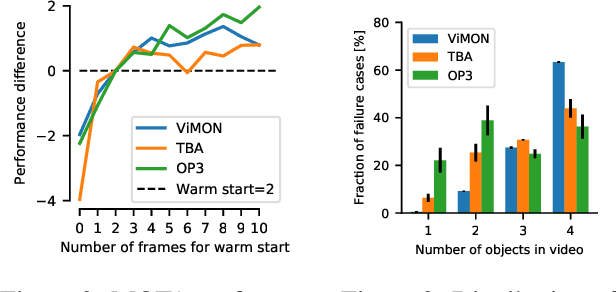
Perceiving the world in terms of objects is a crucial prerequisite for reasoning and scene understanding. Recently, several methods have been proposed for unsupervised learning of object-centric representations. However, since these models have been evaluated with respect to different downstream tasks, it remains unclear how they compare in terms of basic perceptual abilities such as detection, figure-ground segmentation and tracking of individual objects. In this paper, we argue that the established evaluation protocol of multi-object tracking tests precisely these perceptual qualities and we propose a new benchmark dataset based on procedurally generated video sequences. Using this benchmark, we compare the perceptual abilities of three state-of-the-art unsupervised object-centric learning approaches. Towards this goal, we propose a video-extension of MONet, a seminal object-centric model for static scenes, and compare it to two recent video models: OP3, which exploits clustering via spatial mixture models, and TBA, which uses an explicit factorization via spatial transformers. Our results indicate that architectures which employ unconstrained latent representations based on per-object variational autoencoders and full-image object masks are able to learn more powerful representations in terms of object detection, segmentation and tracking than the explicitly parameterized spatial transformer based architecture. We also observe that none of the methods are able to gracefully handle the most challenging tracking scenarios, suggesting that our synthetic video benchmark may provide fruitful guidance towards learning more robust object-centric video representations.
Benchmarking Robustness in Object Detection: Autonomous Driving when Winter is Coming
Jul 17, 2019
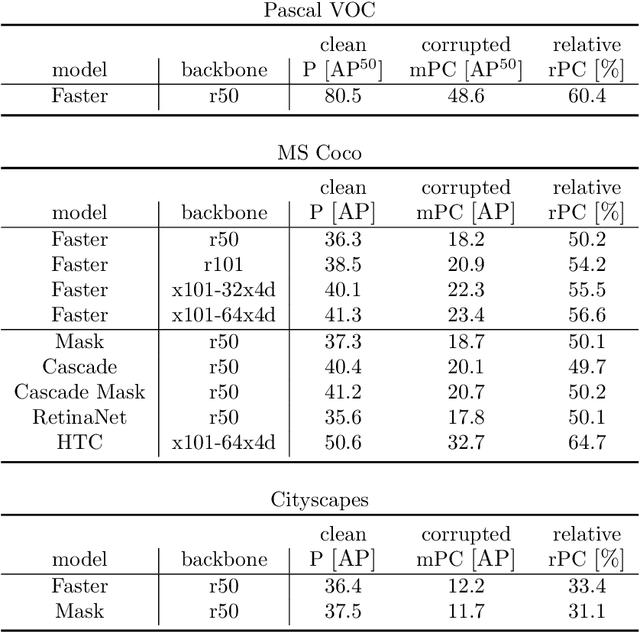


The ability to detect objects regardless of image distortions or weather conditions is crucial for real-world applications of deep learning like autonomous driving. We here provide an easy-to-use benchmark to assess how object detection models perform when image quality degrades. The three resulting benchmark datasets, termed Pascal-C, Coco-C and Cityscapes-C, contain a large variety of image corruptions. We show that a range of standard object detection models suffer a severe performance loss on corrupted images (down to 30-60% of the original performance). However, a simple data augmentation trick - stylizing the training images - leads to a substantial increase in robustness across corruption type, severity and dataset. We envision our comprehensive benchmark to track future progress towards building robust object detection models. Benchmark, code and data are available at: http://github.com/bethgelab/robust-detection-benchmark
One-Shot Instance Segmentation
Nov 28, 2018

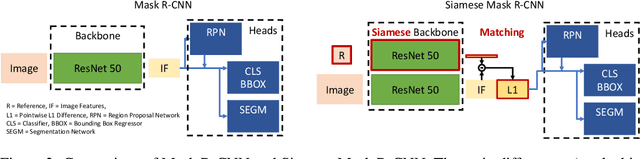

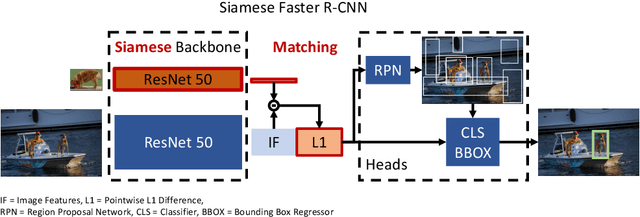
We tackle one-shot visual search by example for arbitrary object categories: Given an example image of a novel reference object, find and segment all object instances of the same category within a scene. To address this problem, we propose Siamese Mask R-CNN. It extends Mask R-CNN by a Siamese backbone encoding both reference image and scene, allowing it to target detection and segmentation towards the reference category. We use Siamese Mask R-CNN to perform one-shot instance segmentation on MS-COCO, demonstrating that it can detect and segment objects of novel categories it was not trained on, and without using mask annotations at test time. Our results highlight challenges of the one-shot setting: while transferring knowledge about instance segmentation to novel object categories not used during training works very well, targeting the detection and segmentation networks towards the reference category appears to be more difficult. Our work provides a first strong baseline for one-shot instance segmentation and will hopefully inspire further research in this relatively unexplored field.
A rotation-equivariant convolutional neural network model of primary visual cortex
Sep 27, 2018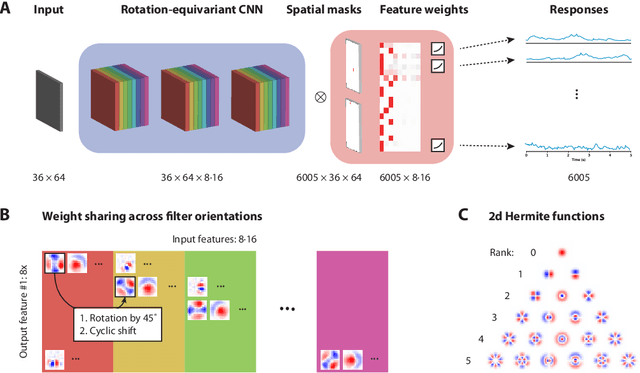
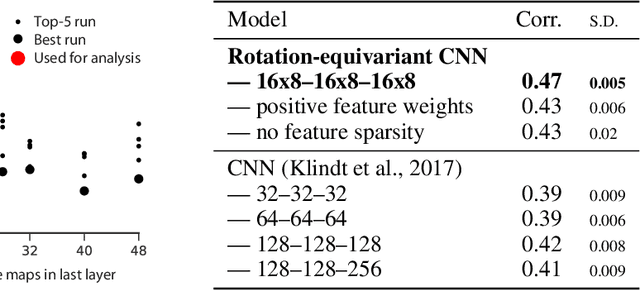
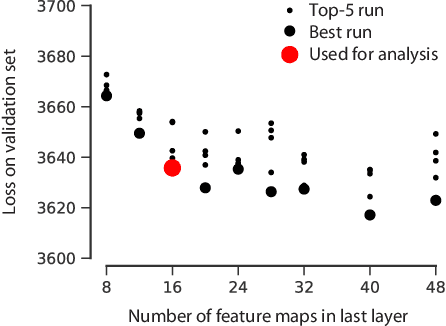
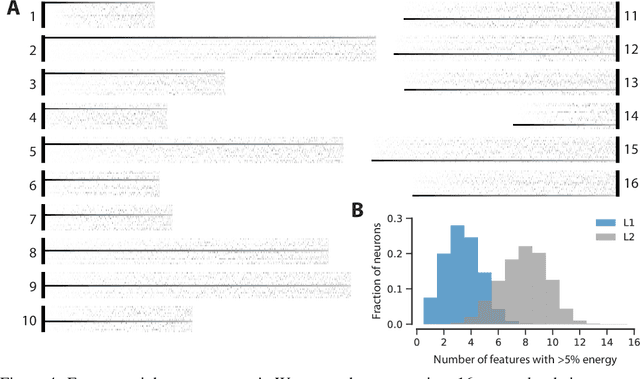
Classical models describe primary visual cortex (V1) as a filter bank of orientation-selective linear-nonlinear (LN) or energy models, but these models fail to predict neural responses to natural stimuli accurately. Recent work shows that models based on convolutional neural networks (CNNs) lead to much more accurate predictions, but it remains unclear which features are extracted by V1 neurons beyond orientation selectivity and phase invariance. Here we work towards systematically studying V1 computations by categorizing neurons into groups that perform similar computations. We present a framework to identify common features independent of individual neurons' orientation selectivity by using a rotation-equivariant convolutional neural network, which automatically extracts every feature at multiple different orientations. We fit this model to responses of a population of 6000 neurons to natural images recorded in mouse primary visual cortex using two-photon imaging. We show that our rotation-equivariant network not only outperforms a regular CNN with the same number of feature maps, but also reveals a number of common features shared by many V1 neurons, which deviate from the typical textbook idea of V1 as a bank of Gabor filters. Our findings are a first step towards a powerful new tool to study the nonlinear computations in V1.
Diverse feature visualizations reveal invariances in early layers of deep neural networks
Jul 27, 2018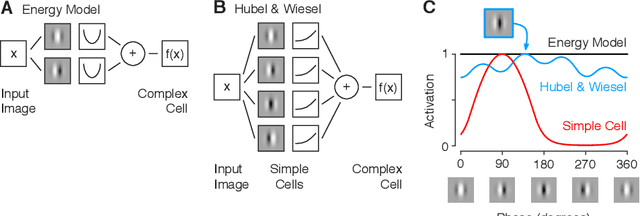
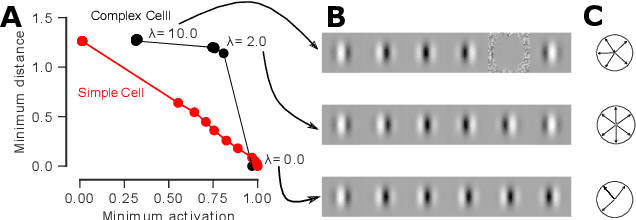
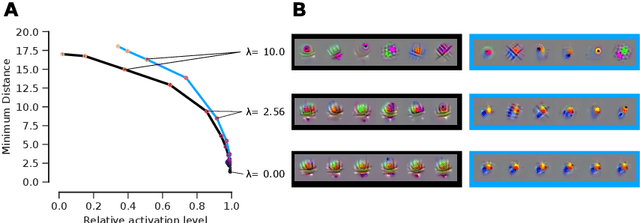
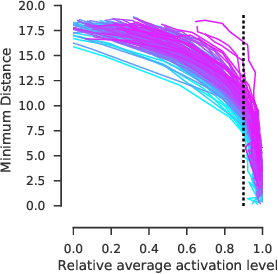
Visualizing features in deep neural networks (DNNs) can help understanding their computations. Many previous studies aimed to visualize the selectivity of individual units by finding meaningful images that maximize their activation. However, comparably little attention has been paid to visualizing to what image transformations units in DNNs are invariant. Here we propose a method to discover invariances in the responses of hidden layer units of deep neural networks. Our approach is based on simultaneously searching for a batch of images that strongly activate a unit while at the same time being as distinct from each other as possible. We find that even early convolutional layers in VGG-19 exhibit various forms of response invariance: near-perfect phase invariance in some units and invariance to local diffeomorphic transformations in others. At the same time, we uncover representational differences with ResNet-50 in its corresponding layers. We conclude that invariance transformations are a major computational component learned by DNNs and we provide a systematic method to study them.
One-Shot Segmentation in Clutter
Jun 13, 2018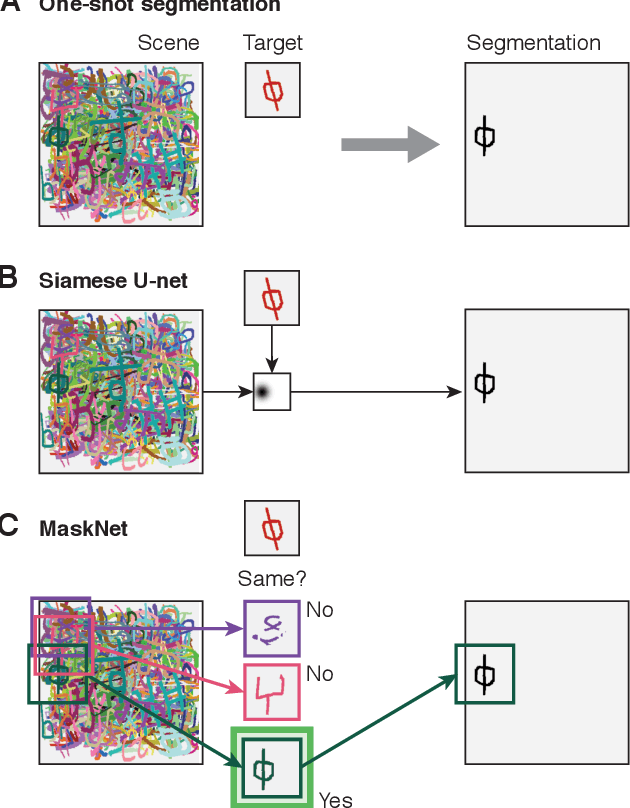
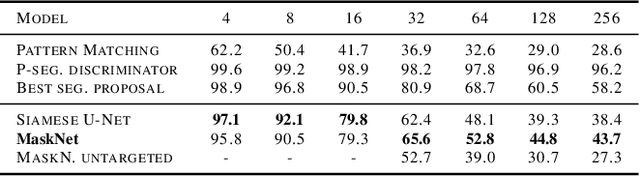


We tackle the problem of one-shot segmentation: finding and segmenting a previously unseen object in a cluttered scene based on a single instruction example. We propose a novel dataset, which we call $\textit{cluttered Omniglot}$. Using a baseline architecture combining a Siamese embedding for detection with a U-net for segmentation we show that increasing levels of clutter make the task progressively harder. Using oracle models with access to various amounts of ground-truth information, we evaluate different aspects of the problem and show that in this kind of visual search task, detection and segmentation are two intertwined problems, the solution to each of which helps solving the other. We therefore introduce $\textit{MaskNet}$, an improved model that attends to multiple candidate locations, generates segmentation proposals to mask out background clutter and selects among the segmented objects. Our findings suggest that such image recognition models based on an iterative refinement of object detection and foreground segmentation may provide a way to deal with highly cluttered scenes.
Neural system identification for large populations separating "what" and "where"
Jan 29, 2018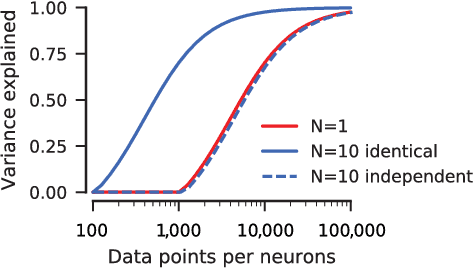
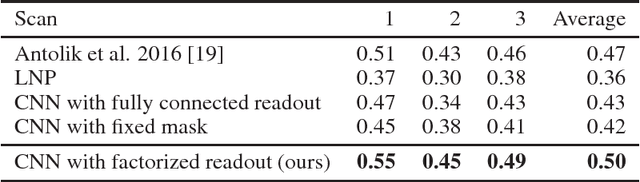
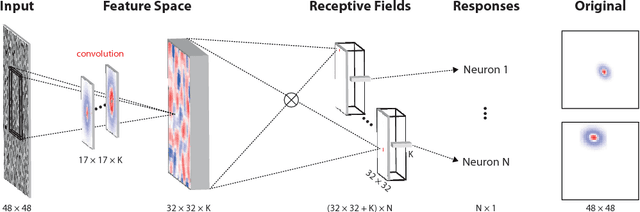
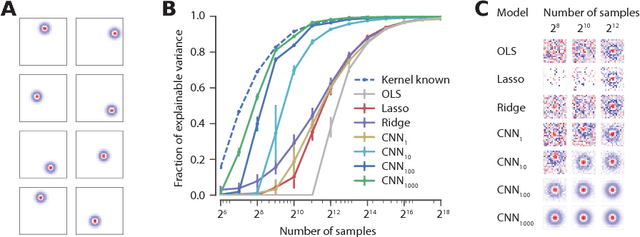
Neuroscientists classify neurons into different types that perform similar computations at different locations in the visual field. Traditional methods for neural system identification do not capitalize on this separation of 'what' and 'where'. Learning deep convolutional feature spaces that are shared among many neurons provides an exciting path forward, but the architectural design needs to account for data limitations: While new experimental techniques enable recordings from thousands of neurons, experimental time is limited so that one can sample only a small fraction of each neuron's response space. Here, we show that a major bottleneck for fitting convolutional neural networks (CNNs) to neural data is the estimation of the individual receptive field locations, a problem that has been scratched only at the surface thus far. We propose a CNN architecture with a sparse readout layer factorizing the spatial (where) and feature (what) dimensions. Our network scales well to thousands of neurons and short recordings and can be trained end-to-end. We evaluate this architecture on ground-truth data to explore the challenges and limitations of CNN-based system identification. Moreover, we show that our network model outperforms current state-of-the art system identification models of mouse primary visual cortex.
Controlling Perceptual Factors in Neural Style Transfer
May 11, 2017



Neural Style Transfer has shown very exciting results enabling new forms of image manipulation. Here we extend the existing method to introduce control over spatial location, colour information and across spatial scale. We demonstrate how this enhances the method by allowing high-resolution controlled stylisation and helps to alleviate common failure cases such as applying ground textures to sky regions. Furthermore, by decomposing style into these perceptual factors we enable the combination of style information from multiple sources to generate new, perceptually appealing styles from existing ones. We also describe how these methods can be used to more efficiently produce large size, high-quality stylisation. Finally we show how the introduced control measures can be applied in recent methods for Fast Neural Style Transfer.